 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Paper and Code
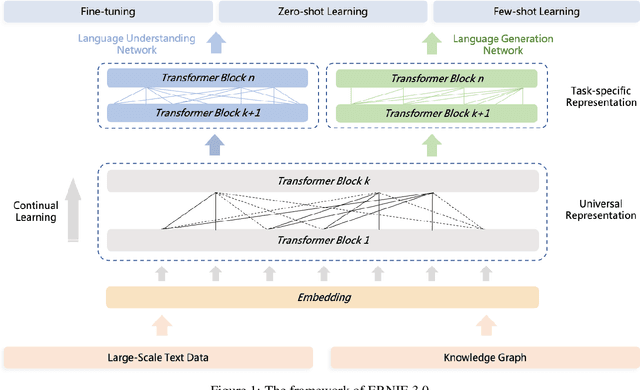
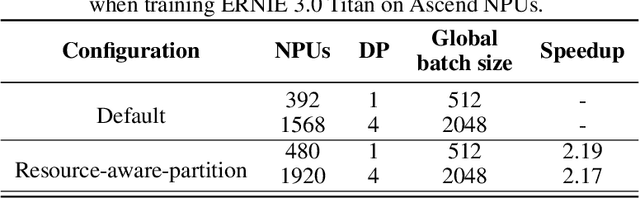
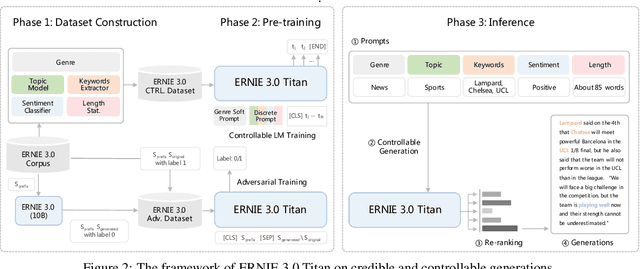
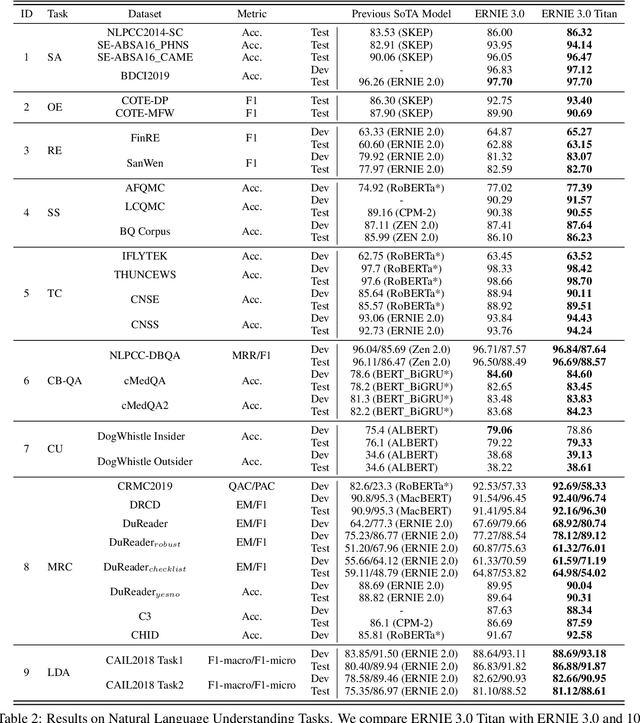
Pre-trained language models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. GPT-3 has shown that scaling up pre-trained language models can further exploit their enormous potential. A unified framework named ERNIE 3.0 was recently proposed for pre-training large-scale knowledge enhanced models and trained a model with 10 billion parameters. ERNIE 3.0 outperformed the state-of-the-art models on various NLP tasks. In order to explore the performance of scaling up ERNIE 3.0, we train a hundred-billion-parameter model called ERNIE 3.0 Titan with up to 260 billion parameters on the PaddlePaddle platform. Furthermore, we design a self-supervised adversarial loss and a controllable language modeling loss to make ERNIE 3.0 Titan generate credible and controllable texts. To reduce the computation overhead and carbon emission, we propose an online distillation framework for ERNIE 3.0 Titan, where the teacher model will teach students and train itself simultaneously. ERNIE 3.0 Titan is the largest Chinese dense pre-trained model so far. Empirical results show that the ERNIE 3.0 Titan outperforms the state-of-the-art models on 68 NLP datasets.