 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwinBERT: End-to-End Transformers with Sparse Attention for Video Captioning
Paper and Code
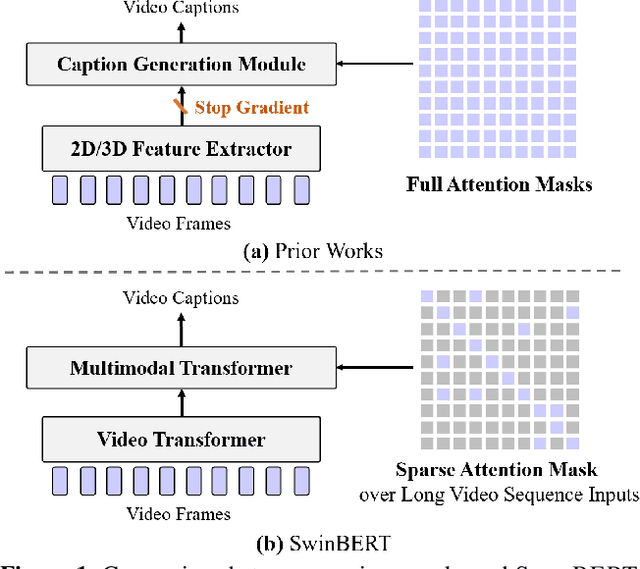

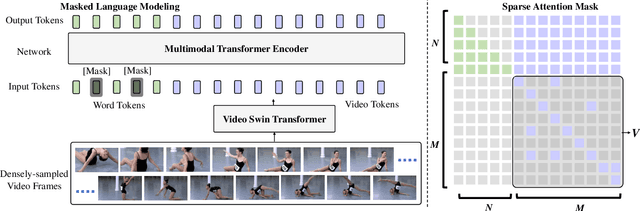
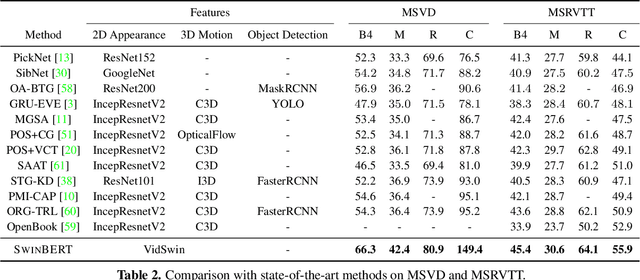
The canonical approach to video captioning dictates a caption generation model to learn from offline-extracted dense video features. These feature extractors usually operate on video frames sampled at a fixed frame rate and are often trained on image/video understanding tasks, without adaption to video captioning data. In this work, we present SwinBERT, an end-to-end transformer-based model for video captioning, which takes video frame patches directly as inputs, and outputs a natural language description. Instead of leveraging multiple 2D/3D feature extractors, our method adopts a video transformer to encode spatial-temporal representations that can adapt to variable lengths of video input without dedicated design for different frame rates. Based on this model architecture, we show that video captioning can benefit significantly from more densely sampled video frames as opposed to previous successes with sparsely sampled video frames for video-and-language understanding tasks (e.g., video question answering). Moreover, to avoid the inherent redundancy in consecutive video frames, we propose adaptively learning a sparse attention mask and optimizing it for task-specific performance improvement through better long-range video sequence modeling. Through extensive experiments on 5 video captioning datasets, we show that SwinBERT achieves across-the-board performance improvements over previous methods, often by a large margin. The learned sparse attention masks in addition push the limit to new state of the arts, and can be transferred between different video lengths and between different datasets.