 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaled ReLU Matters for Training Vision Transformers
Paper and Code
Sep 08, 2021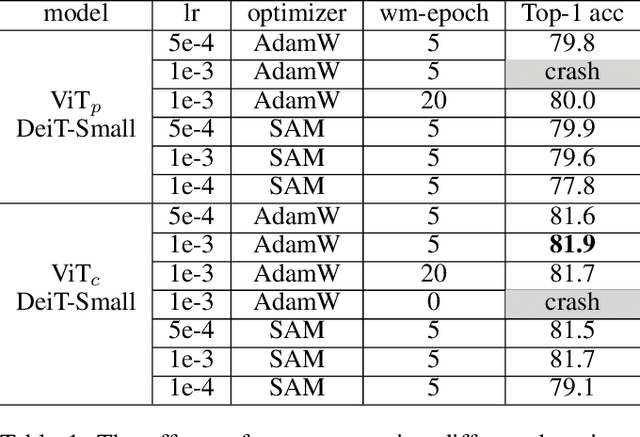
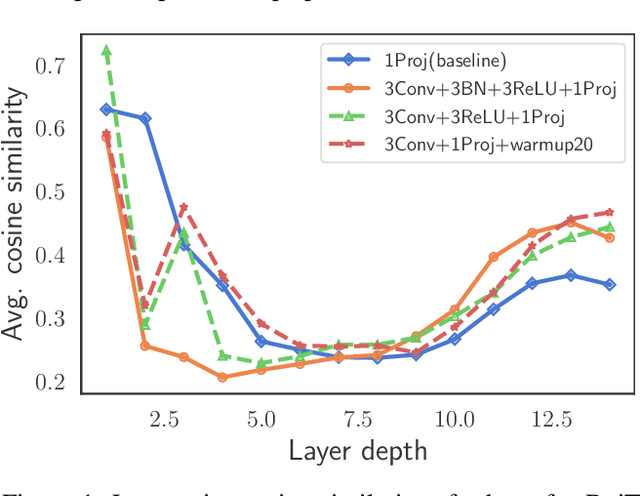
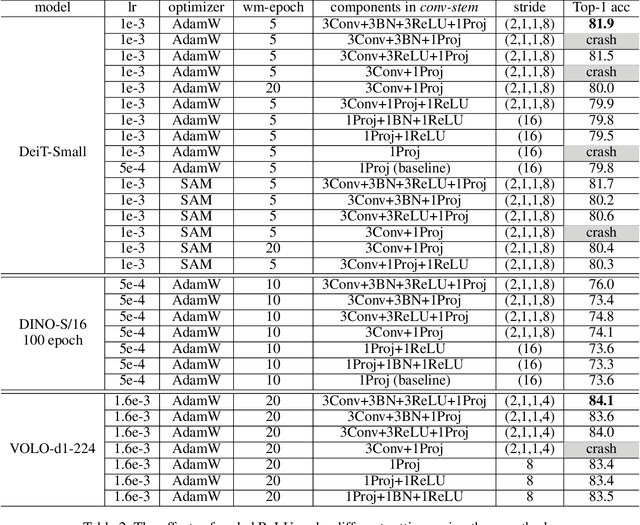
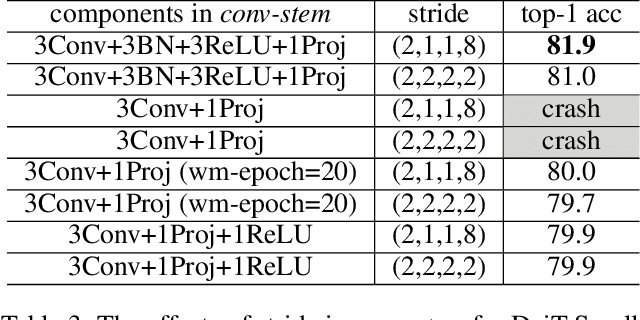
Vision transformers (ViTs) have been an alternative design paradigm to convolutional neural networks (CNNs). However, the training of ViTs is much harder than CNNs, as it is sensitive to the training parameters, such as learning rate, optimizer and warmup epoch. The reasons for training difficulty are empirically analysed in ~\cite{xiao2021early}, and the authors conjecture that the issue lies with the \textit{patchify-stem} of ViT models and propose that early convolutions help transformers see better. In this paper, we further investigate this problem and extend the above conclusion: only early convolutions do not help for stable training, but the scaled ReLU operation in the \textit{convolutional stem} (\textit{conv-stem}) matters. We verify, both theoretically and empirically, that scaled ReLU in \textit{conv-stem} not only improves training stabilization, but also increases the diversity of patch tokens, thus boosting peak performance with a large margin via adding few parameters and flops. In addition, extensive experiments are conducted to demonstrate that previous ViTs are far from being well trained, further showing that ViTs have great potential to be a better substitute of CNNs.