 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Attacking Graph Neural Network and its Explanations
Paper and Code
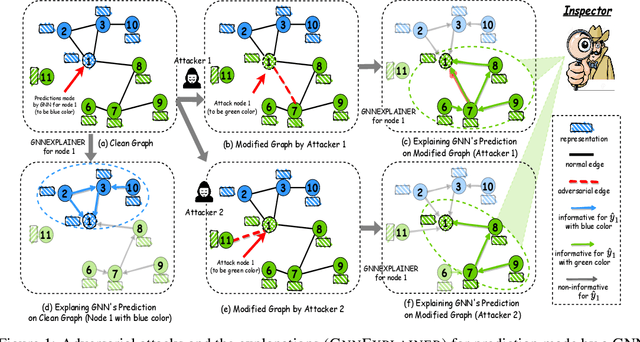
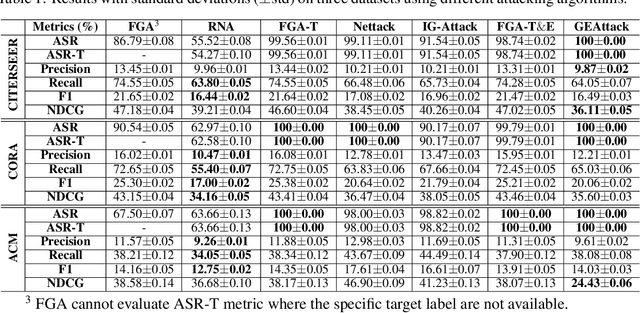
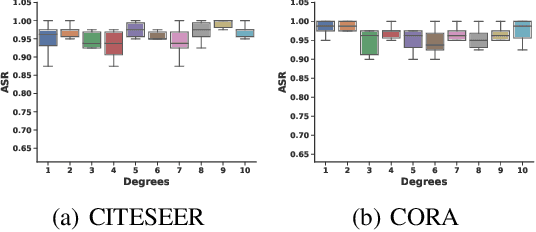

Graph Neural Networks (GNNs) have boosted the performance for many graph-related tasks. Despite the great success, recent studies have shown that GNNs are highly vulnerable to adversarial attacks, where adversaries can mislead the GNNs' prediction by modifying graphs. On the other hand, the explanation of GNNs (GNNExplainer) provides a better understanding of a trained GNN model by generating a small subgraph and features that are most influential for its prediction. In this paper, we first perform empirical studies to validate that GNNExplainer can act as an inspection tool and have the potential to detect the adversarial perturbations for graphs. This finding motivates us to further initiate a new problem investigation: Whether a graph neural network and its explanations can be jointly attacked by modifying graphs with malicious desires? It is challenging to answer this question since the goals of adversarial attacks and bypassing the GNNExplainer essentially contradict each other. In this work, we give a confirmative answer to this question by proposing a novel attack framework (GEAttack), which can attack both a GNN model and its explanations by simultaneously exploiting their vulnerabilities. Extensive experiments on two explainers (GNNExplainer and PGExplainer) under various real-world datasets demonstrate the effectiveness of the proposed method.