 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVA: An Open-Domain Chinese Dialogue System with Large-Scale Generative Pre-Training
Paper and Code

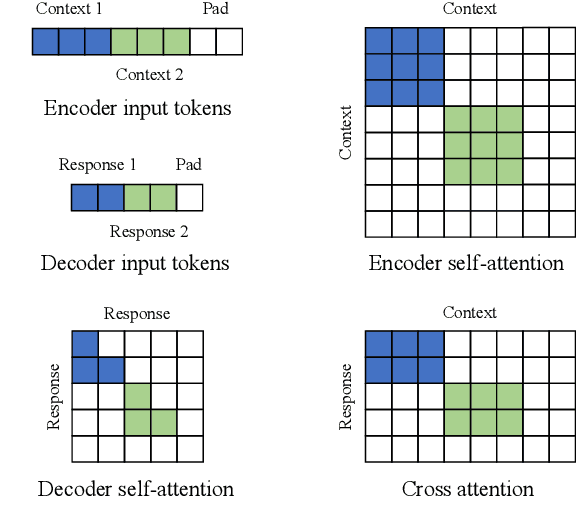
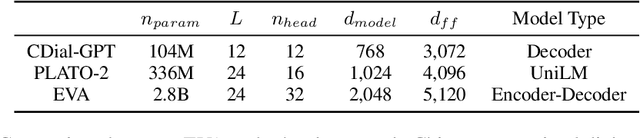
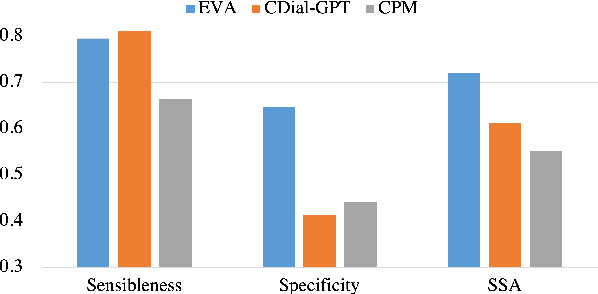
Although pre-trained language models have remarkably enhanced the generation ability of dialogue systems, open-domain Chinese dialogue systems are still limited by the dialogue data and the model size compared with English ones. In this paper, we propose EVA, a Chinese dialogue system that contains the largest Chinese pre-trained dialogue model with 2.8B parameters. To build this model, we collect the largest Chinese dialogue dataset named WDC-Dialogue from various public social media. This dataset contains 1.4B context-response pairs and is used as the pre-training corpus of EVA. Extensive experiments on automatic and human evaluation show that EVA outperforms other Chinese pre-trained dialogue models especially in the multi-turn interaction of human-bot conversations.