 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-Drop: Regularized Dropout for Neural Networks
Paper and Code
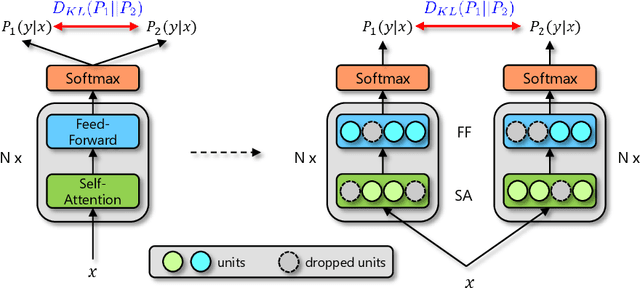

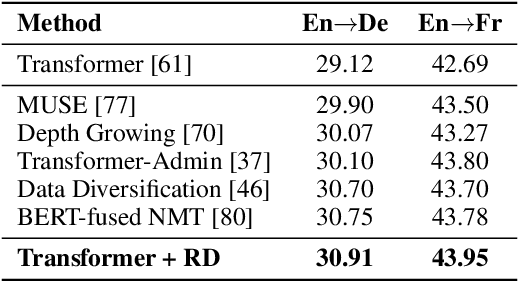
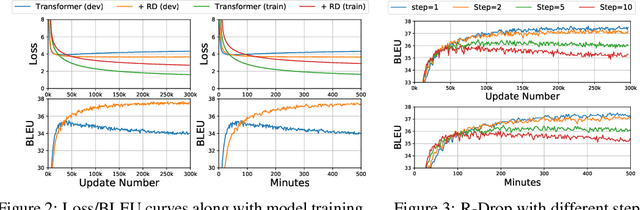
Dropout is a powerful and widely used technique to regularize the training of deep neural networks. In this paper, we introduce a simple regularization strategy upon dropout in model training, namely R-Drop, which forces the output distributions of different sub models generated by dropout to be consistent with each other. Specifically, for each training sample, R-Drop minimizes the bidirectional KL-divergence between the output distributions of two sub models sampled by dropout. Theoretical analysis reveals that R-Drop reduces the freedom of the model parameters and complements dropout. Experiments on $\bf{5}$ widely used deep learning tasks ($\bf{18}$ datasets in total), including neural machine translation, abstractive summarization, language understanding, language modeling, and image classification, show that R-Drop is universally effective. In particular, it yields substantial improvements when applied to fine-tune large-scale pre-trained models, e.g., ViT, RoBERTa-large, and BART, and achieves state-of-the-art (SOTA) performances with the vanilla Transformer model on WMT14 English$\to$German translation ($\bf{30.91}$ BLEU) and WMT14 English$\to$French translation ($\bf{43.95}$ BLEU), even surpassing models trained with extra large-scale data and expert-designed advanced variants of Transformer models. Our code is available at GitHub{\url{https://github.com/dropreg/R-Drop}}.