 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-based Vision Transformer for Subtyping of Papillary Renal Cell Carcinoma in Histopathological Image
Paper and Code
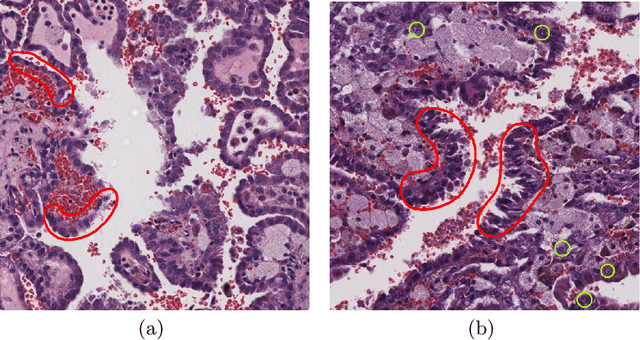
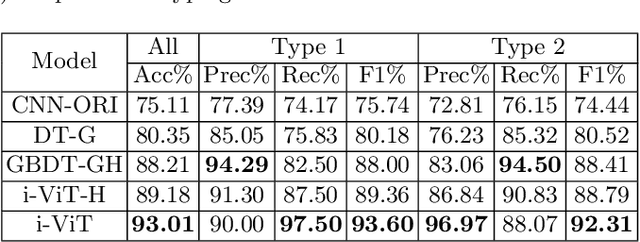
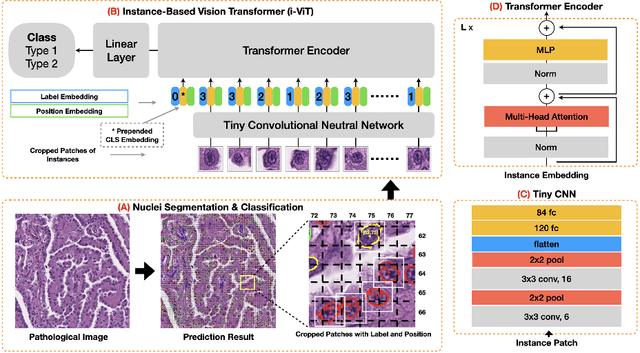
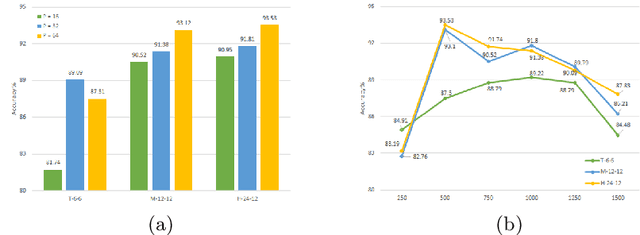
Histological subtype of papillary (p) renal cell carcinoma (RCC), type 1 vs. type 2, is an essential prognostic factor. The two subtypes of pRCC have a similar pattern, i.e., the papillary architecture, yet some subtle differences, including cellular and cell-layer level patterns. However, the cellular and cell-layer level patterns almost cannot be captured by existing CNN-based models in large-size histopathological images, which brings obstacles to directly applying these models to such a fine-grained classification task. This paper proposes a novel instance-based Vision Transformer (i-ViT) to learn robust representations of histopathological images for the pRCC subtyping task by extracting finer features from instance patches (by cropping around segmented nuclei and assigning predicted grades). The proposed i-ViT takes top-K instances as input and aggregates them for capturing both the cellular and cell-layer level patterns by a position-embedding layer, a grade-embedding layer, and a multi-head multi-layer self-attention module. To evaluate the performance of the proposed framework, experienced pathologists are invited to selected 1162 regions of interest from 171 whole slide images of type 1 and type 2 pRCC. Experimental results show that the proposed method achieves better performance than existing CNN-based models with a significant margin.