 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Compress Once: Towards Effective and Elastic BERT Compression via Exploit-Explore Stochastic Nature Gradient
Paper and Code
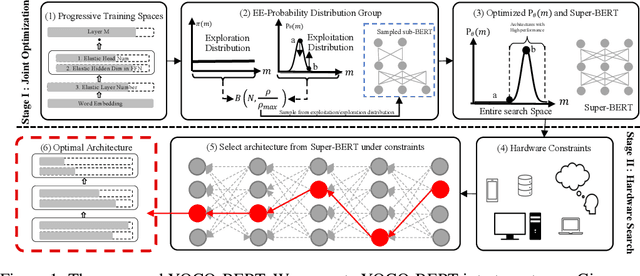
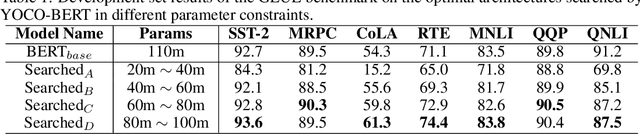
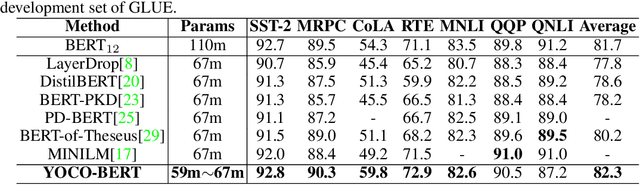
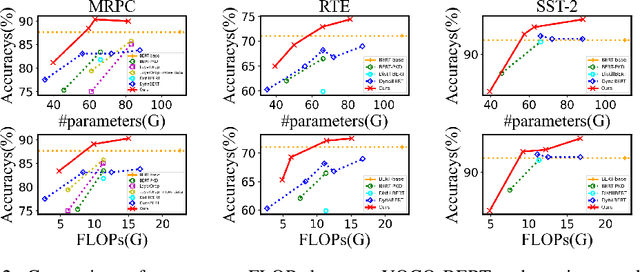
Despite superior performance on various natural language processing tasks, pre-trained models such as BERT are challenged by deploying on resource-constraint devices. Most existing model compression approaches require re-compression or fine-tuning across diverse constraints to accommodate various hardware deployments. This practically limits the further application of model compression. Moreover, the ineffective training and searching process of existing elastic compression paradigms[4,27] prevents the direct migration to BERT compression. Motivated by the necessity of efficient inference across various constraints on BERT, we propose a novel approach, YOCO-BERT, to achieve compress once and deploy everywhere. Specifically, we first construct a huge search space with 10^13 architectures, which covers nearly all configurations in BERT model. Then, we propose a novel stochastic nature gradient optimization method to guide the generation of optimal candidate architecture which could keep a balanced trade-off between explorations and exploitation. When a certain resource constraint is given, a lightweight distribution optimization approach is utilized to obtain the optimal network for target deployment without fine-tuning. Compared with state-of-the-art algorithms, YOCO-BERT provides more compact models, yet achieving 2.1%-4.5% average accuracy improvement on the GLUE benchmark. Besides, YOCO-BERT is also more effective, e.g.,the training complexity is O(1)for N different devices. Code is availablehttps://github.com/MAC-AutoML/YOCO-BERT.