 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAAformer: Auto-Aligned Transformer for Person Re-Identification
Paper and Code
Apr 02, 2021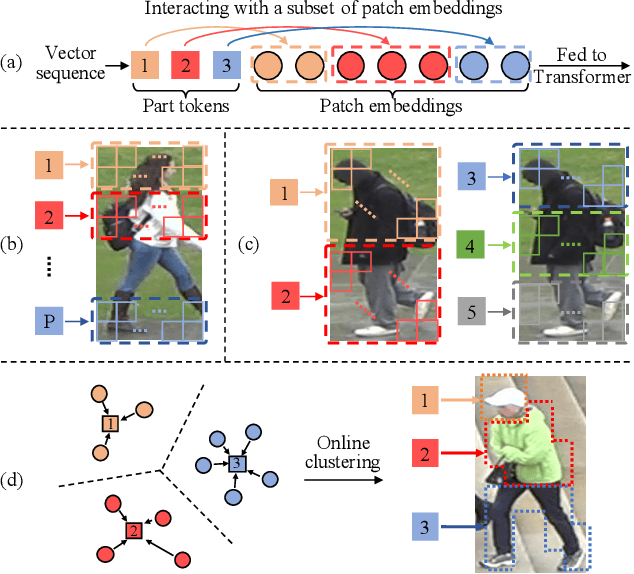
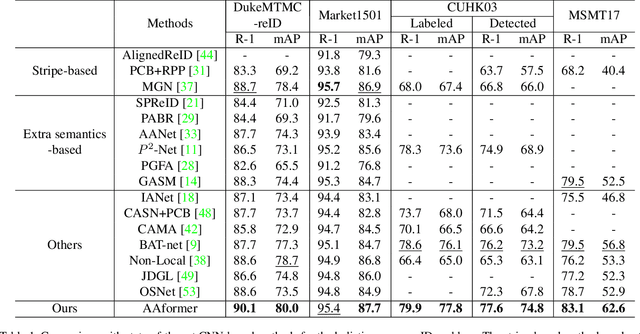
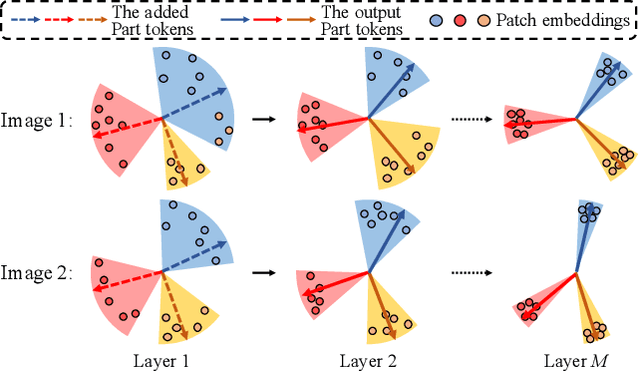
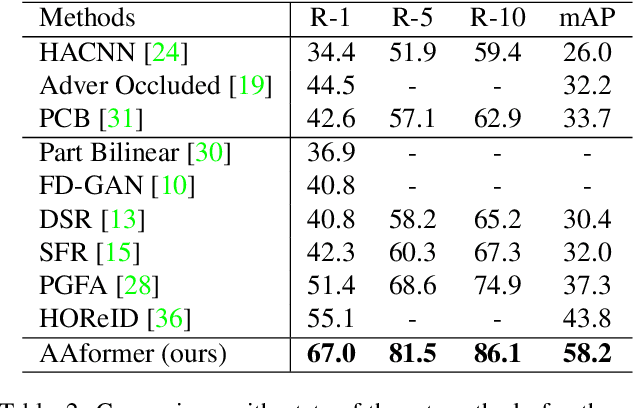
Transformer is showing its superiority over convolutional architectures in many vision tasks like image classification and object detection. However, the lacking of an explicit alignment mechanism limits its capability in person re-identification (re-ID), in which there are inevitable misalignment issues caused by pose/viewpoints variations, etc. On the other hand, the alignment paradigm of convolutional neural networks does not perform well in Transformer in our experiments. To address this problem, we develop a novel alignment framework for Transformer through adding the learnable vectors of "part tokens" to learn the part representations and integrating the part alignment into the self-attention. A part token only interacts with a subset of patch embeddings and learns to represent this subset. Based on the framework, we design an online Auto-Aligned Transformer (AAformer) to adaptively assign the patch embeddings of the same semantics to the identical part token in the running time. The part tokens can be regarded as the part prototypes, and a fast variant of Sinkhorn-Knopp algorithm is employed to cluster the patch embeddings to part tokens online. AAformer can be viewed as a new principled formulation for simultaneously learning both part alignment and part representations. Extensive experiments validate the effectiveness of part tokens and the superiority of AAformer over various state-of-the-art CNN-based methods. Our codes will be released.