 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Pre-trained Language Models via Calibrated Cascade
Paper and Code
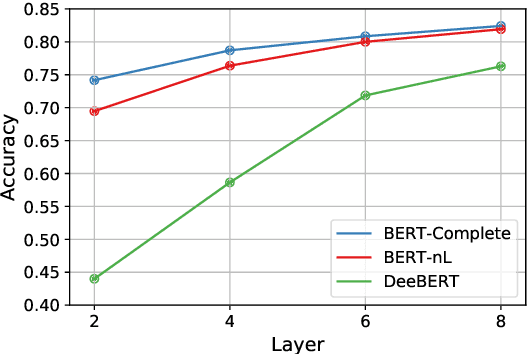
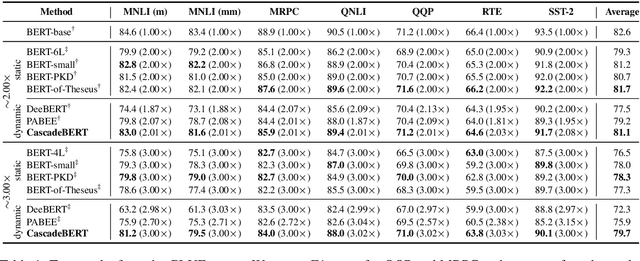
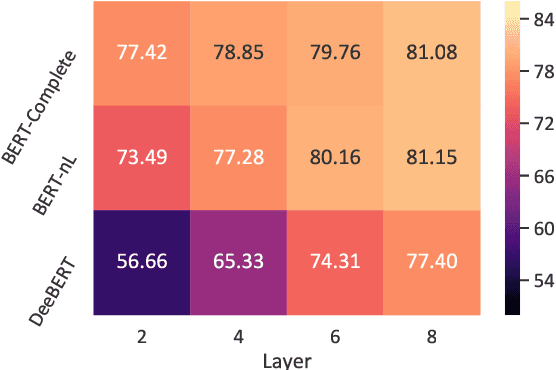
Dynamic early exiting aims to accelerate pre-trained language models' (PLMs) inference by exiting in shallow layer without passing through the entire model. In this paper, we analyze the working mechanism of dynamic early exiting and find it cannot achieve a satisfying trade-off between inference speed and performance. On one hand, the PLMs' representations in shallow layers are not sufficient for accurate prediction. One the other hand, the internal off-ramps cannot provide reliable exiting decisions. To remedy this, we instead propose CascadeBERT, which dynamically selects a proper-sized, complete model in a cascading manner. To obtain more reliable model selection, we further devise a difficulty-aware objective, encouraging the model output class probability to reflect the real difficulty of each instance. Extensive experimental results demonstrate the superiority of our proposal over strong baseline models of PLMs' acceleration including both dynamic early exiting and knowledge distillation methods.