 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleNAS: One-Shot Learning of Scale-Aware Representations for Visual Recognition
Paper and Code
Nov 30, 2020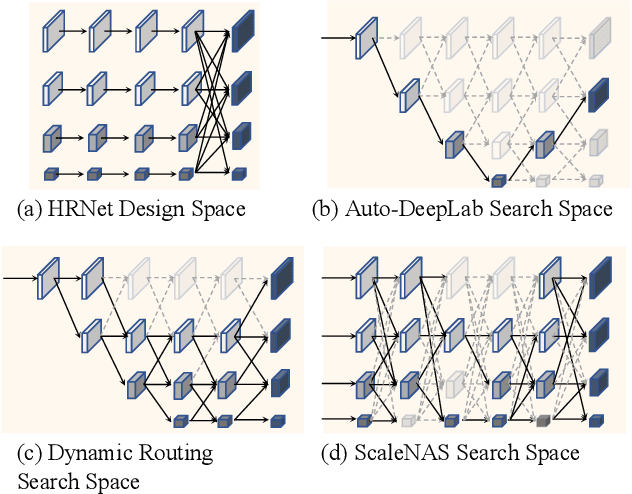
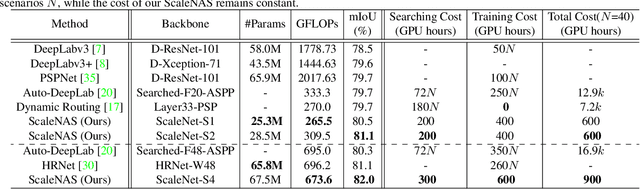
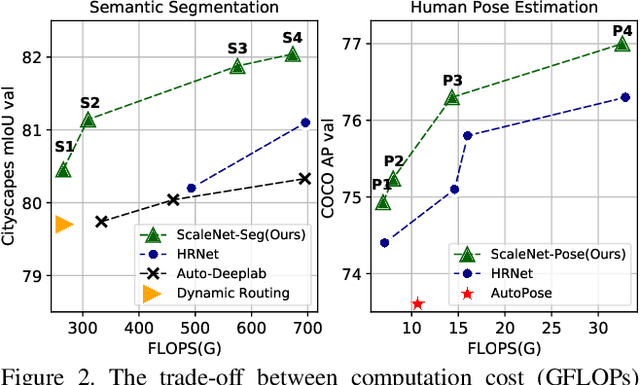
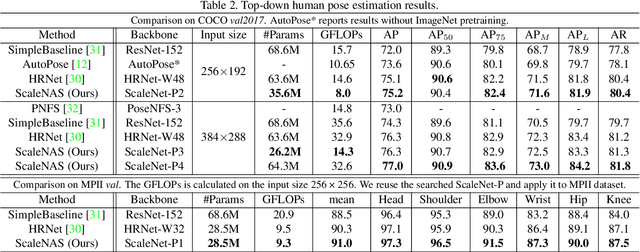
Scale variance among different sizes of body parts and objects is a challenging problem for visual recognition tasks. Existing works usually design dedicated backbone or apply Neural architecture Search(NAS) for each task to tackle this challenge. However, existing works impose significant limitations on the design or search space. To solve these problems, we present ScaleNAS, a one-shot learning method for exploring scale-aware representations. ScaleNAS solves multiple tasks at a time by searching multi-scale feature aggregation. ScaleNAS adopts a flexible search space that allows an arbitrary number of blocks and cross-scale feature fusions. To cope with the high search cost incurred by the flexible space, ScaleNAS employs one-shot learning for multi-scale supernet driven by grouped sampling and evolutionary search. Without further retraining, ScaleNet can be directly deployed for different visual recognition tasks with superior performance. We use ScaleNAS to create high-resolution models for two different tasks, ScaleNet-P for human pose estimation and ScaleNet-S for semantic segmentation. ScaleNet-P and ScaleNet-S outperform existing manually crafted and NAS-based methods in both tasks. When applying ScaleNet-P to bottom-up human pose estimation, it surpasses the state-of-the-art HigherHRNet. In particular, ScaleNet-P4 achieves 71.6% AP on COCO test-dev, achieving new state-of-the-art result.