 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLID 2020: The Learning from Imperfect Data Challenge Results
Paper and Code
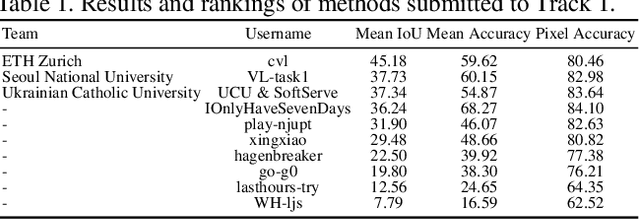
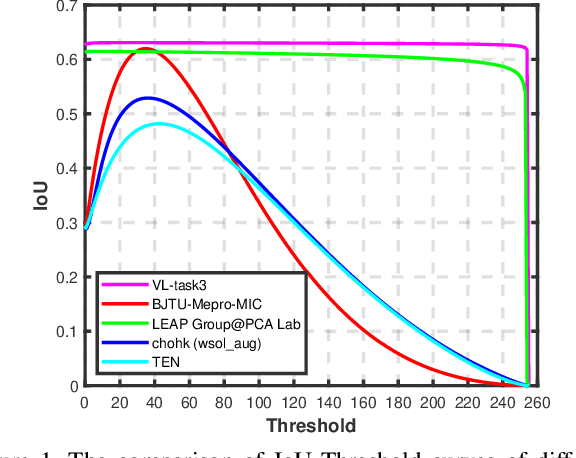

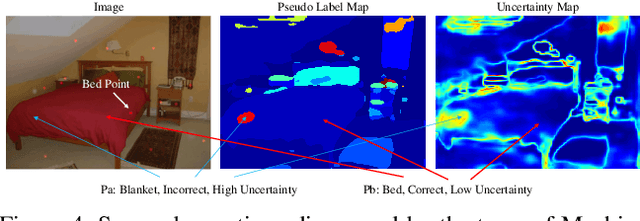
Learning from imperfect data becomes an issue in many industrial applications after the research community has made profound progress in supervised learning from perfectly annotated datasets. The purpose of the Learning from Imperfect Data (LID) workshop is to inspire and facilitate the research in developing novel approaches that would harness the imperfect data and improve the data-efficiency during training. A massive amount of user-generated data nowadays available on multiple internet services. How to leverage those and improve the machine learning models is a high impact problem. We organize the challenges in conjunction with the workshop. The goal of these challenges is to find the state-of-the-art approaches in the weakly supervised learning setting for object detection, semantic segmentation, and scene parsing. There are three tracks in the challenge, i.e., weakly supervised semantic segmentation (Track 1), weakly supervised scene parsing (Track 2), and weakly supervised object localization (Track 3). In Track 1, based on ILSVRC DET, we provide pixel-level annotations of 15K images from 200 categories for evaluation. In Track 2, we provide point-based annotations for the training set of ADE20K. In Track 3, based on ILSVRC CLS-LOC, we provide pixel-level annotations of 44,271 images for evaluation. Besides, we further introduce a new evaluation metric proposed by \cite{zhang2020rethinking}, i.e., IoU curve, to measure the quality of the generated object localization maps. This technical report summarizes the highlights from the challenge. The challenge submission server and the leaderboard will continue to open for the researchers who are interested in it. More details regarding the challenge and the benchmarks are available at https://lidchallenge.github.io