 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCylinder3D: An Effective 3D Framework for Driving-scene LiDAR Semantic Segmentation
Paper and Code
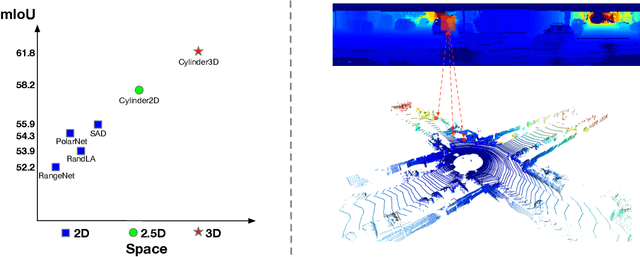
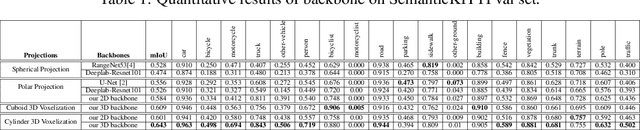
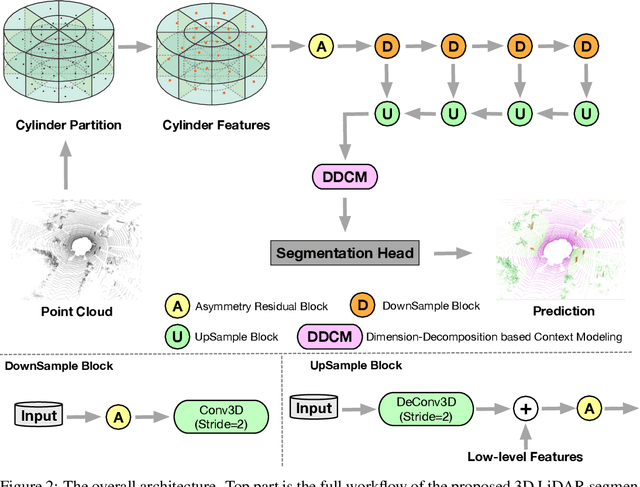
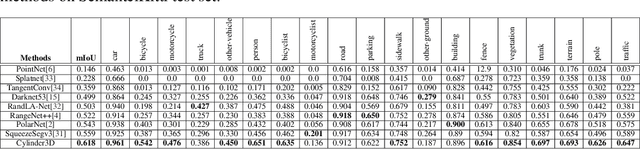
State-of-the-art methods for large-scale driving-scene LiDAR semantic segmentation often project and process the point clouds in the 2D space. The projection methods includes spherical projection, bird-eye view projection, etc. Although this process makes the point cloud suitable for the 2D CNN-based networks, it inevitably alters and abandons the 3D topology and geometric relations. A straightforward solution to tackle the issue of 3D-to-2D projection is to keep the 3D representation and process the points in the 3D space. In this work, we first perform an in-depth analysis for different representations and backbones in 2D and 3D spaces, and reveal the effectiveness of 3D representations and networks on LiDAR segmentation. Then, we develop a 3D cylinder partition and a 3D cylinder convolution based framework, termed as Cylinder3D, which exploits the 3D topology relations and structures of driving-scene point clouds. Moreover, a dimension-decomposition based context modeling module is introduced to explore the high-rank context information in point clouds in a progressive manner. We evaluate the proposed model on a large-scale driving-scene dataset, i.e. SematicKITTI. Our method achieves state-of-the-art performance and outperforms existing methods by 6% in terms of mIoU.