 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Precision Training: Quantify Back Propagation in Neural Networks with Fixed-point Numbers
Paper and Code
Nov 01, 2019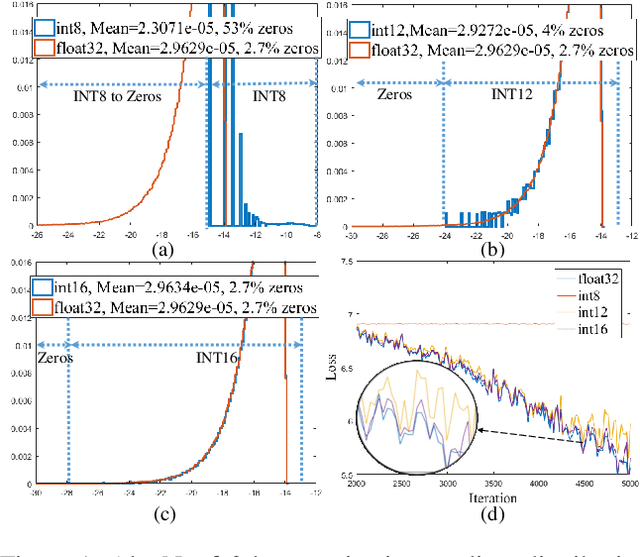
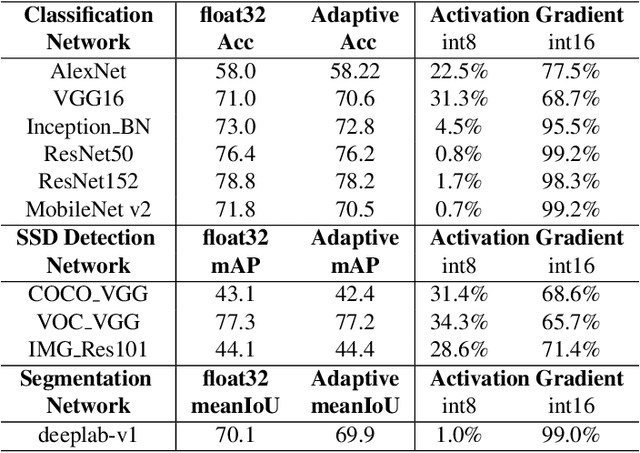
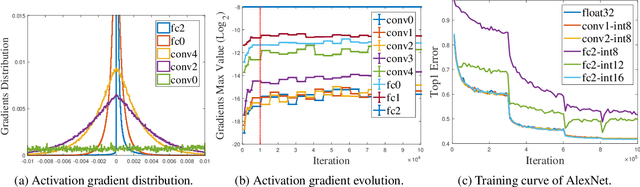
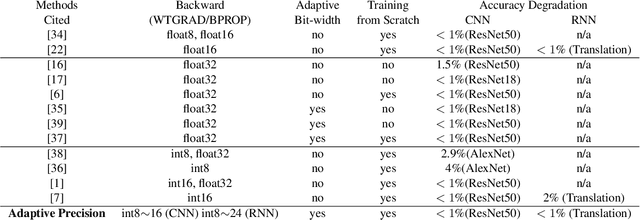
Recent emerged quantization technique (i.e., using low bit-width fixed-point data instead of high bit-width floating-point data) has been applied to inference of deep neural networks for fast and efficient execution. However, directly applying quantization in training can cause significant accuracy loss, thus remaining an open challenge. In this paper, we propose a novel training approach, which applies a layer-wise precision-adaptive quantization in deep neural networks. The new training approach leverages our key insight that the degradation of training accuracy is attributed to the dramatic change of data distribution. Therefore, by keeping the data distribution stable through a layer-wise precision-adaptive quantization, we are able to directly train deep neural networks using low bit-width fixed-point data and achieve guaranteed accuracy, without changing hyper parameters. Experimental results on a wide variety of network architectures (e.g., convolution and recurrent networks) and applications (e.g., image classification, object detection, segmentation and machine translation) show that the proposed approach can train these neural networks with negligible accuracy losses (-1.40%~1.3%, 0.02% on average), and speed up training by 252% on a state-of-the-art Intel CPU.