 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarNet: Targeted Computation for Object Detection in Point Clouds
Paper and Code
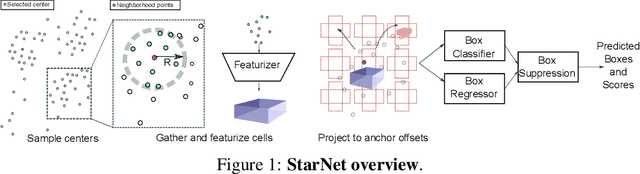
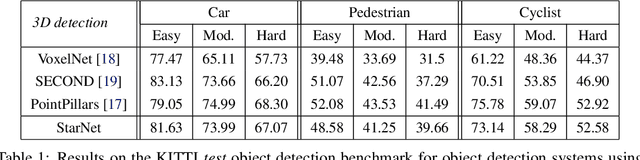
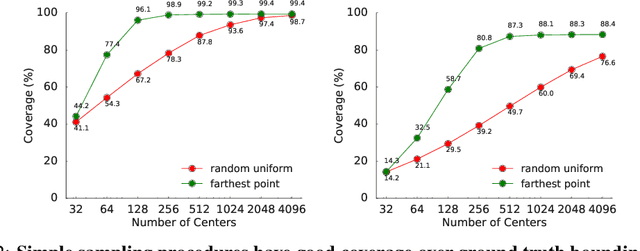
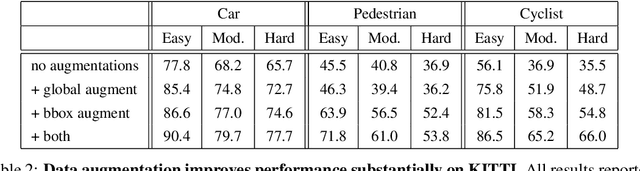
LiDAR sensor systems provide high resolution spatial information about the environment for self-driving cars. Therefore, detecting objects from point clouds derived from LiDAR represents a critical problem. Previous work on object detection from LiDAR has emphasized re-purposing convolutional approaches from traditional camera imagery. In this work, we present an object detection system designed specifically for point cloud data blending aspects of one-stage and two-stage systems. We observe that objects in point clouds are quite distinct from traditional camera images: objects are sparse and vary widely in location, but do not exhibit scale distortions observed in single camera perspective. These two observations suggest that simple and cheap data-driven object proposals to maximize spatial coverage or match the observed densities of point cloud data may suffice. This recognition paired with a local, non-convolutional, point-based network permits building an object detector for point clouds that may be trained only once, but adapted to different computational settings -- targeted to different predictive priorities or spatial regions. We demonstrate this flexibility and the targeted detection strategies on both the KITTI detection dataset as well as on the large-scale Waymo Open Dataset. Furthermore, we find that a single network is competitive with other point cloud detectors across a range of computational budgets, while being more flexible to adapt to contextual priorities.