 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Dynamics and Returns: Value Function Decomposition with Future Prediction
Paper and Code
May 27, 2019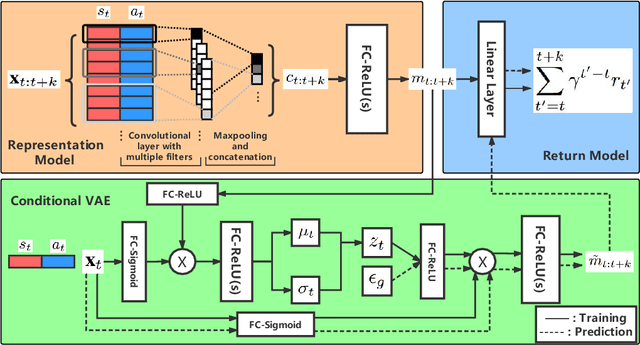
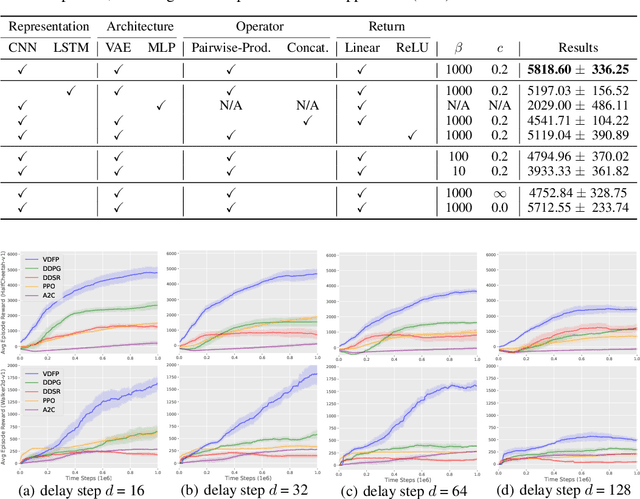
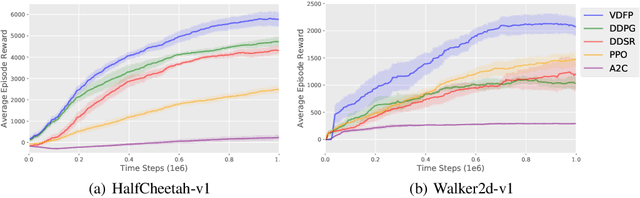

Value functions are crucial for model-free Reinforcement Learning (RL) to obtain a policy implicitly or guide the policy updates. Value estimation heavily depends on the stochasticity of environmental dynamics and the quality of reward signals. In this paper, we propose a two-step understanding of value estimation from the perspective of future prediction, through decomposing the value function into a reward-independent future dynamics part and a policy-independent trajectory return part. We then derive a practical deep RL algorithm from the above decomposition, consisting of a convolutional trajectory representation model, a conditional variational dynamics model to predict the expected representation of future trajectory and a convex trajectory return model that maps a trajectory representation to its return. Our algorithm is evaluated in MuJoCo continuous control tasks and shows superior results under both common settings and delayed reward settings.