 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Adversarial Examples by Activation Promotion and Suppression
Paper and Code
Apr 03, 2019
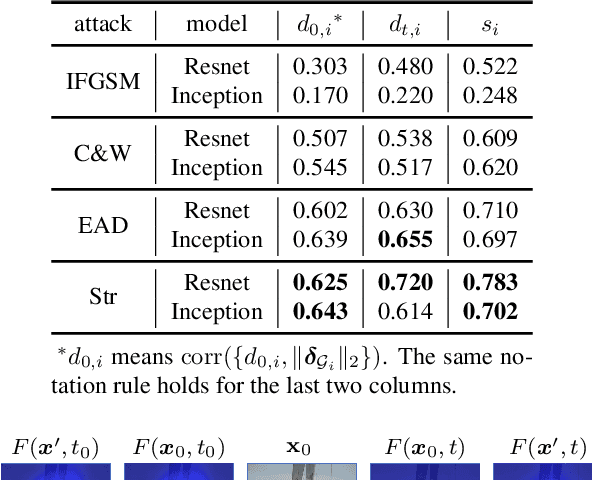
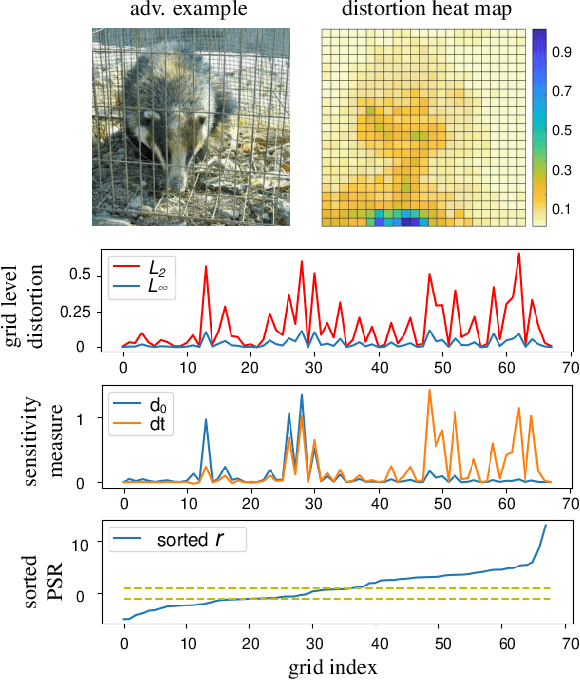

It is widely known that convolutional neural networks (CNNs) are vulnerable to adversarial examples: crafted images with imperceptible perturbations. However, interpretability of these perturbations is less explored in the literature. This work aims to better understand the roles of adversarial perturbations and provide visual explanations from pixel, image and network perspectives. We show that adversaries make a promotion and suppression effect (PSE) on neurons' activation and can be primarily categorized into three types: 1)suppression-dominated perturbations that mainly reduce the classification score of the true label, 2)promotion-dominated perturbations that focus on boosting the confidence of the target label, and 3)balanced perturbations that play a dual role on suppression and promotion. Further, we provide the image-level interpretability of adversarial examples, which links PSE of pixel-level perturbations to class-specific discriminative image regions localized by class activation mapping. Lastly, we analyze the effect of adversarial examples through network dissection, which offers concept-level interpretability of hidden units. We show that there exists a tight connection between the sensitivity (against attacks) of internal response of units with their interpretability on semantic concepts.