 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynetgy: Algorithm-hardware Co-design for ConvNet Accelerators on Embedded FPGAs
Paper and Code
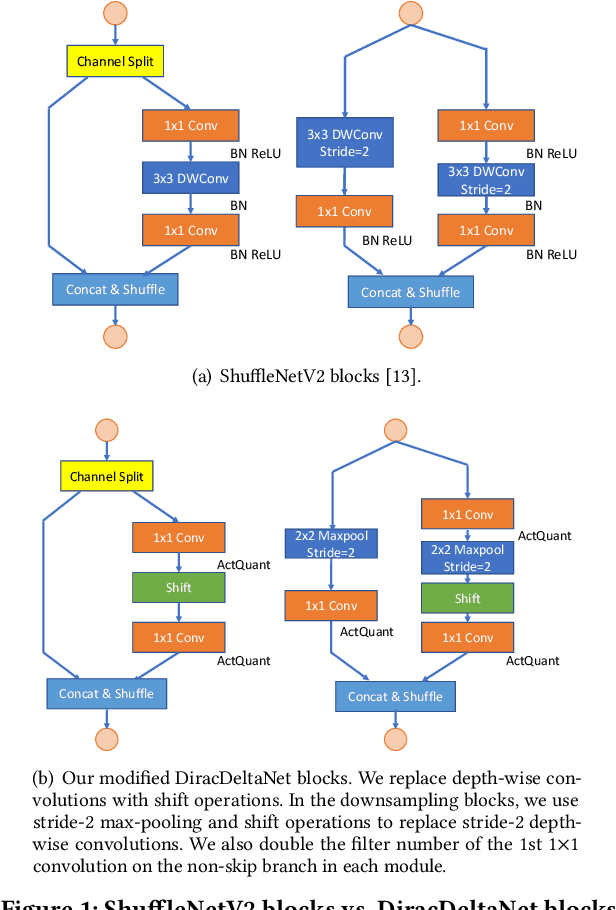
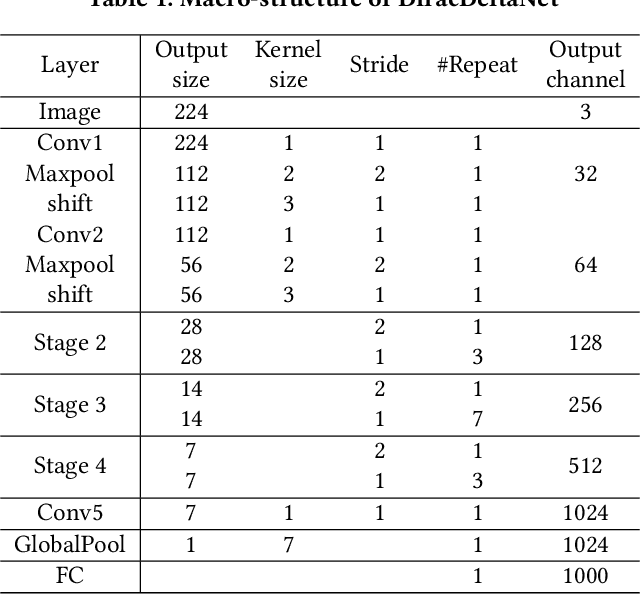
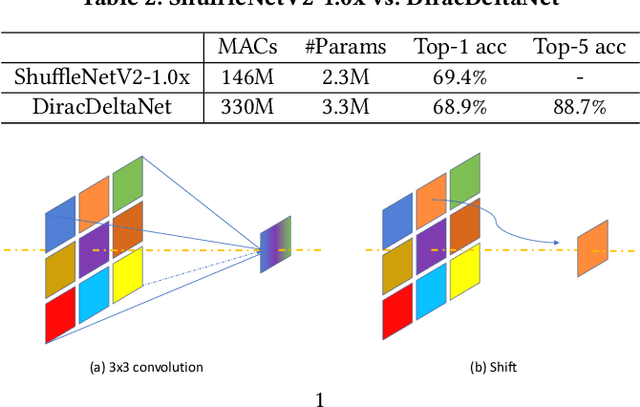
Using FPGAs to accelerate ConvNets has attracted significant attention in recent years. However, FPGA accelerator design has not leveraged the latest progress of ConvNets. As a result, the key application characteristics such as frames-per-second (FPS) are ignored in favor of simply counting GOPs, and results on accuracy, which is critical to application success, are often not even reported. In this work, we adopt an algorithm-hardware co-design approach to develop a ConvNet accelerator called Synetgy and a novel ConvNet model called DiracNet. Both the accelerator and ConvNet are tailored to FPGA requirements. DiractNet, as the name suggests, is a ConvNet with only 1x1 convolutions while spatial convolutions are replaced by more efficient shift operations. DiracNet achieves competitive accuracy on ImageNet (89.0% top-5), but with 48x fewer parameters and 65x fewer OPs than VGG16. We further quantize DiracNet's weights to 1-bit and activations to 4-bits, with less than 1% accuracy loss. These quantizations exploit well the nature of FPGA hardware. In short, DiracNet's small model size, low computational OP count, ultra-low precision and simplified operators allow us to co-design a highly customized computing unit for an FPGA. We implement the computing units for DiracNet on an Ultra96 SoC system through high-level synthesis. The implementation only took 2 people 1 month to complete. Our accelerator's final top-5 accuracy of 88.3% on ImageNet, is higher than all the previously reported embedded FPGA accelerators. In addition, the accelerator reaches an inference speed of 72.8 FPS on the ImageNet classification task, surpassing prior works with similar accuracy by at least 12.8x.