 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Adversarial Attack: Towards General Implementation and Better Interpretability
Paper and Code
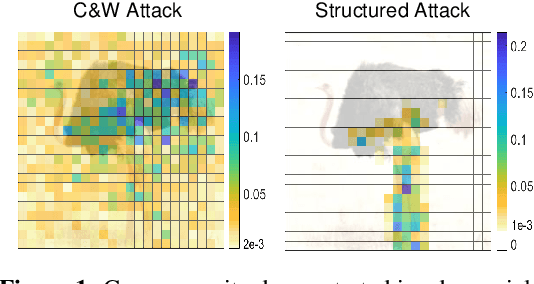
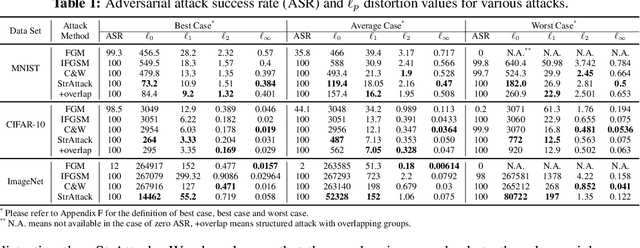
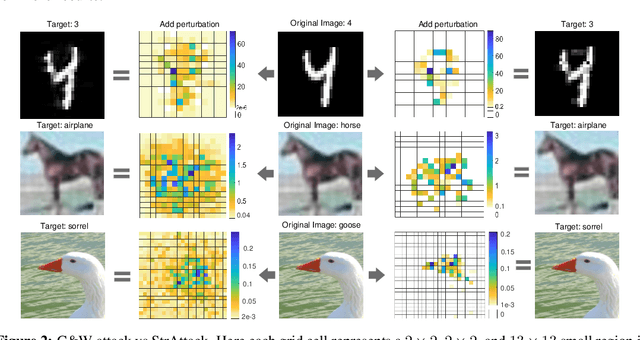

When generating adversarial examples to attack deep neural networks (DNNs), Lp norm of the added perturbation is usually used to measure the similarity between original image and adversarial example. However, such adversarial attacks perturbing the raw input spaces may fail to capture structural information hidden in the input. This work develops a more general attack model, i.e., the structured attack (StrAttack), which explores group sparsity in adversarial perturbations by sliding a mask through images aiming for extracting key spatial structures. An ADMM (alternating direction method of multipliers)-based framework is proposed that can split the original problem into a sequence of analytically solvable subproblems and can be generalized to implement other attacking methods. Strong group sparsity is achieved in adversarial perturbations even with the same level of Lp norm distortion as the state-of-the-art attacks. We demonstrate the effectiveness of StrAttack by extensive experimental results onMNIST, CIFAR-10, and ImageNet. We also show that StrAttack provides better interpretability (i.e., better correspondence with discriminative image regions)through adversarial saliency map (Papernot et al., 2016b) and class activation map(Zhou et al., 2016).