 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTable-r1: Self-supervised and Reinforcement Learning for Program-based Table Reasoning in Small Language Models
Jun 06, 2025Table reasoning (TR) requires structured reasoning over semi-structured tabular data and remains challenging, particularly for small language models (SLMs, e.g., LLaMA-8B) due to their limited capacity compared to large LMs (LLMs, e.g., GPT-4o). To narrow this gap, we explore program-based TR (P-TR), which circumvents key limitations of text-based TR (T-TR), notably in numerical reasoning, by generating executable programs. However, applying P-TR to SLMs introduces two challenges: (i) vulnerability to heterogeneity in table layouts, and (ii) inconsistency in reasoning due to limited code generation capability. We propose Table-r1, a two-stage P-TR method designed for SLMs. Stage 1 introduces an innovative self-supervised learning task, Layout Transformation Inference, to improve tabular layout generalization from a programmatic view. Stage 2 adopts a mix-paradigm variant of Group Relative Policy Optimization, enhancing P-TR consistency while allowing dynamic fallback to T-TR when needed. Experiments on four TR benchmarks demonstrate that Table-r1 outperforms all SLM-based methods, achieving at least a 15% accuracy improvement over the base model (LLaMA-8B) across all datasets and reaching performance competitive with LLMs.
Assessing Graph-based Deep Learning Models for Predicting Flash Point
Feb 26, 2020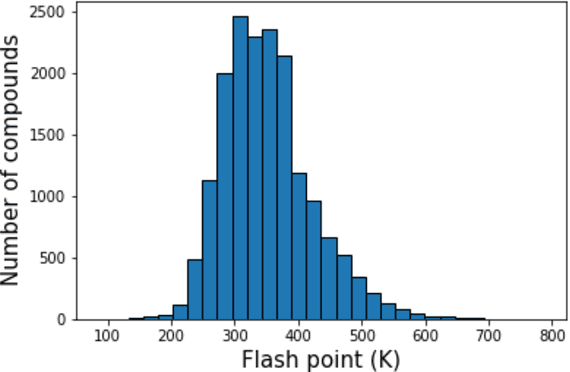
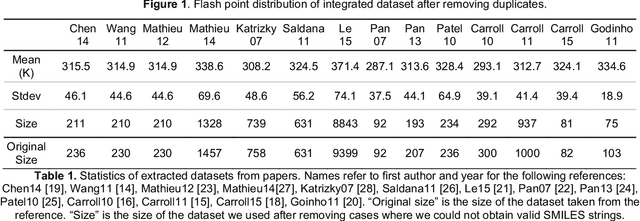
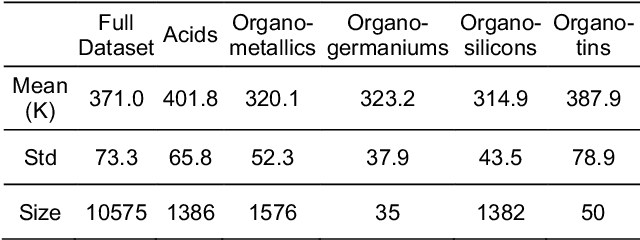
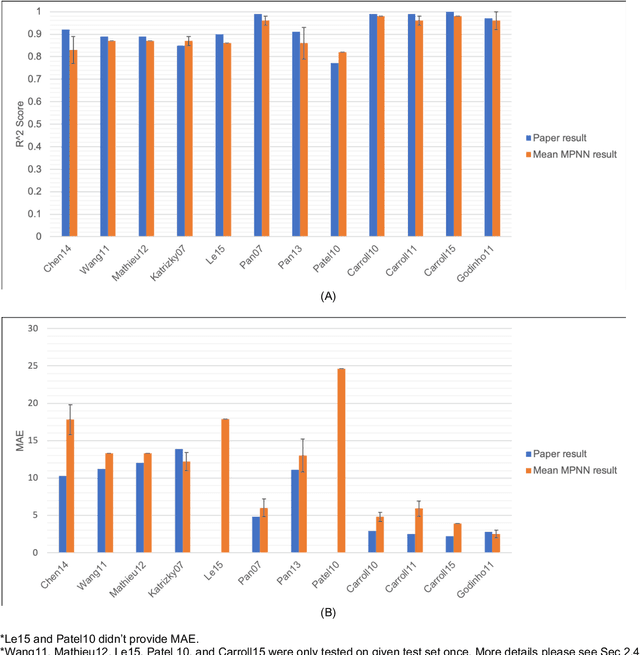
Flash points of organic molecules play an important role in preventing flammability hazards and large databases of measured values exist, although millions of compounds remain unmeasured. To rapidly extend existing data to new compounds many researchers have used quantitative structure-property relationship (QSPR) analysis to effectively predict flash points. In recent years graph-based deep learning (GBDL) has emerged as a powerful alternative method to traditional QSPR. In this paper, GBDL models were implemented in predicting flash point for the first time. We assessed the performance of two GBDL models, message-passing neural network (MPNN) and graph convolutional neural network (GCNN), by comparing methods. Our result shows that MPNN both outperforms GCNN and yields slightly worse but comparable performance with previous QSPR studies. The average R2 and Mean Absolute Error (MAE) scores of MPNN are, respectively, 2.3% lower and 2.0 K higher than previous comparable studies. To further explore GBDL models, we collected the largest flash point dataset to date, which contains 10575 unique molecules. The optimized MPNN gives a test data R2 of 0.803 and MAE of 17.8 K on the complete dataset. We also extracted 5 datasets from our integrated dataset based on molecular types (acids, organometallics, organogermaniums, organosilicons, and organotins) and explore the quality of the model in these classes.against 12 previous QSPR studies using more traditional
* 26 pages, 6 tabels, 3 figures