 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining generative neural networks via Maximum Mean Discrepancy optimization
May 14, 2015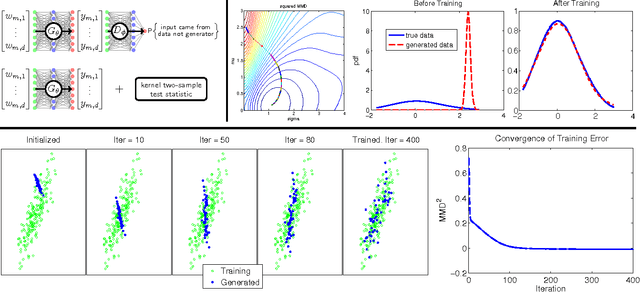


We consider training a deep neural network to generate samples from an unknown distribution given i.i.d. data. We frame learning as an optimization minimizing a two-sample test statistic---informally speaking, a good generator network produces samples that cause a two-sample test to fail to reject the null hypothesis. As our two-sample test statistic, we use an unbiased estimate of the maximum mean discrepancy, which is the centerpiece of the nonparametric kernel two-sample test proposed by Gretton et al. (2012). We compare to the adversarial nets framework introduced by Goodfellow et al. (2014), in which learning is a two-player game between a generator network and an adversarial discriminator network, both trained to outwit the other. From this perspective, the MMD statistic plays the role of the discriminator. In addition to empirical comparisons, we prove bounds on the generalization error incurred by optimizing the empirical MMD.
Beta diffusion trees and hierarchical feature allocations
Apr 03, 2015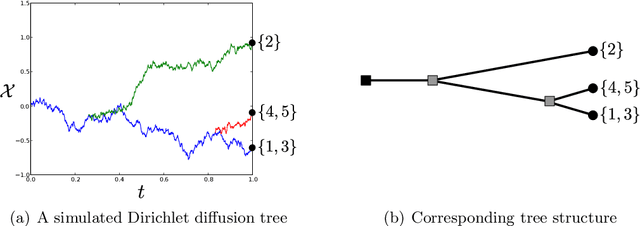
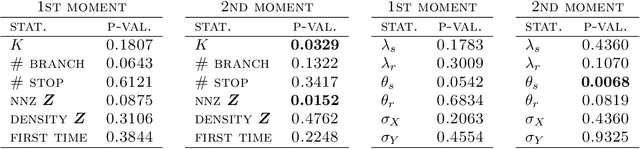
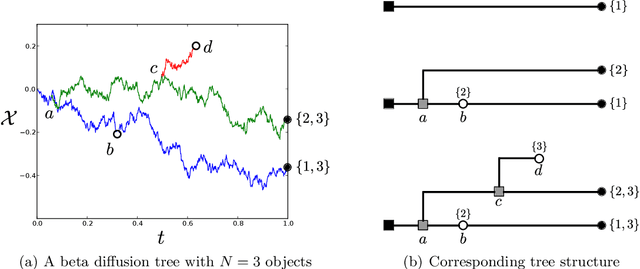
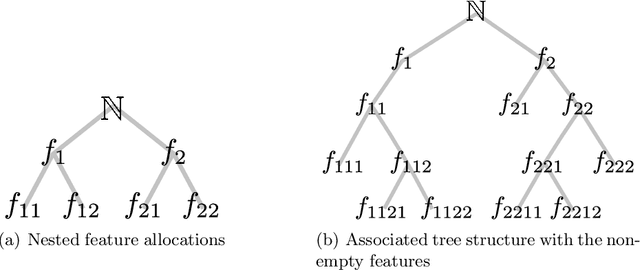
We define the beta diffusion tree, a random tree structure with a set of leaves that defines a collection of overlapping subsets of objects, known as a feature allocation. A generative process for the tree structure is defined in terms of particles (representing the objects) diffusing in some continuous space, analogously to the Dirichlet diffusion tree (Neal, 2003), which defines a tree structure over partitions (i.e., non-overlapping subsets) of the objects. Unlike in the Dirichlet diffusion tree, multiple copies of a particle may exist and diffuse along multiple branches in the beta diffusion tree, and an object may therefore belong to multiple subsets of particles. We demonstrate how to build a hierarchically-clustered factor analysis model with the beta diffusion tree and how to perform inference over the random tree structures with a Markov chain Monte Carlo algorithm. We conclude with several numerical experiments on missing data problems with data sets of gene expression microarrays, international development statistics, and intranational socioeconomic measurements.
Sublinear-Time Approximate MCMC Transitions for Probabilistic Programs
Mar 09, 2015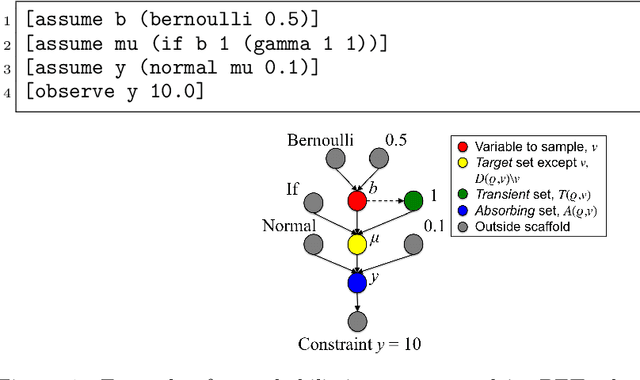

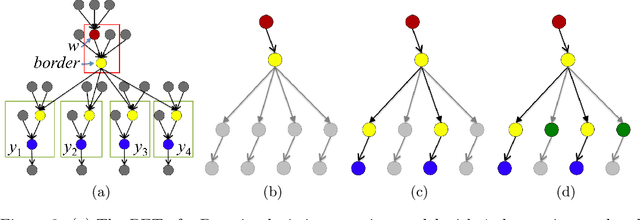
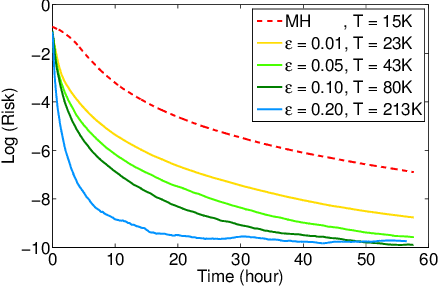
Probabilistic programming languages can simplify the development of machine learning techniques, but only if inference is sufficiently scalable. Unfortunately, Bayesian parameter estimation for highly coupled models such as regressions and state-space models still scales poorly; each MCMC transition takes linear time in the number of observations. This paper describes a sublinear-time algorithm for making Metropolis-Hastings (MH) updates to latent variables in probabilistic programs. The approach generalizes recently introduced approximate MH techniques: instead of subsampling data items assumed to be independent, it subsamples edges in a dynamically constructed graphical model. It thus applies to a broader class of problems and interoperates with other general-purpose inference techniques. Empirical results, including confirmation of sublinear per-transition scaling, are presented for Bayesian logistic regression, nonlinear classification via joint Dirichlet process mixtures, and parameter estimation for stochastic volatility models (with state estimation via particle MCMC). All three applications use the same implementation, and each requires under 20 lines of probabilistic code.
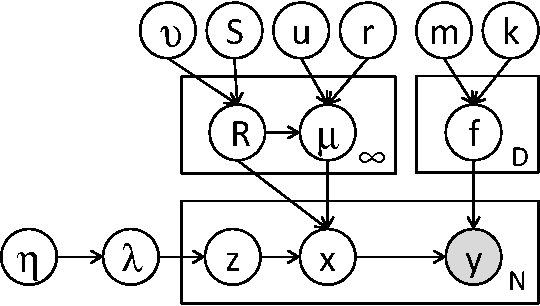
Latent Gaussian Processes for Distribution Estimation of Multivariate Categorical Data
Mar 07, 2015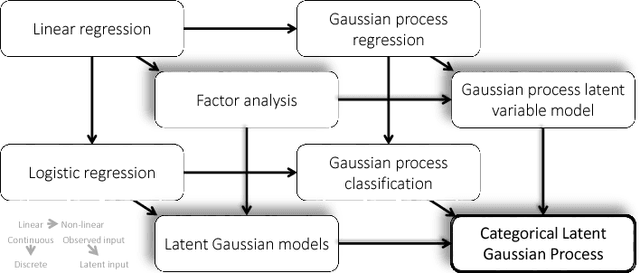
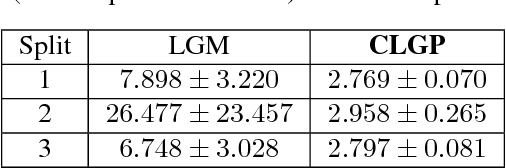
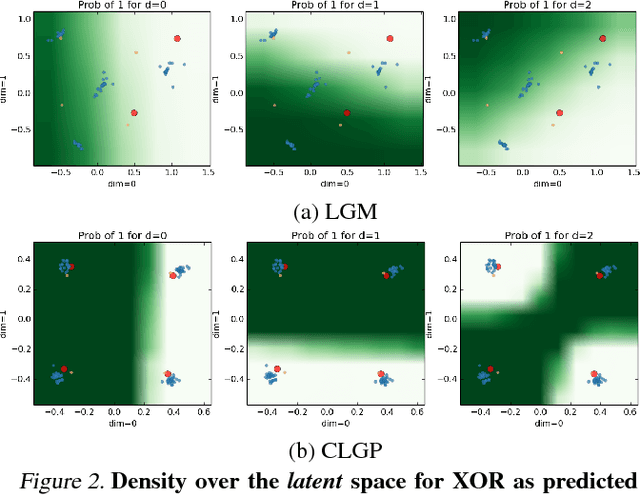

Multivariate categorical data occur in many applications of machine learning. One of the main difficulties with these vectors of categorical variables is sparsity. The number of possible observations grows exponentially with vector length, but dataset diversity might be poor in comparison. Recent models have gained significant improvement in supervised tasks with this data. These models embed observations in a continuous space to capture similarities between them. Building on these ideas we propose a Bayesian model for the unsupervised task of distribution estimation of multivariate categorical data. We model vectors of categorical variables as generated from a non-linear transformation of a continuous latent space. Non-linearity captures multi-modality in the distribution. The continuous representation addresses sparsity. Our model ties together many existing models, linking the linear categorical latent Gaussian model, the Gaussian process latent variable model, and Gaussian process classification. We derive inference for our model based on recent developments in sampling based variational inference. We show empirically that the model outperforms its linear and discrete counterparts in imputation tasks of sparse data.
Slice Sampling for Probabilistic Programming
Jan 20, 2015

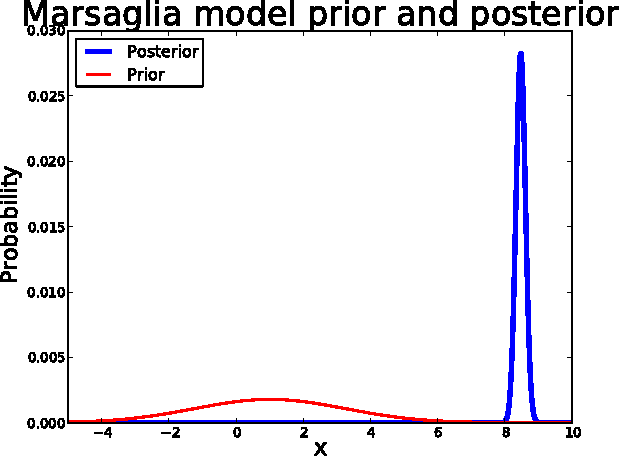
We introduce the first, general purpose, slice sampling inference engine for probabilistic programs. This engine is released as part of StocPy, a new Turing-Complete probabilistic programming language, available as a Python library. We present a transdimensional generalisation of slice sampling which is necessary for the inference engine to work on traces with different numbers of random variables. We show that StocPy compares favourably to other PPLs in terms of flexibility and usability, and that slice sampling can outperform previously introduced inference methods. Our experiments include a logistic regression, HMM, and Bayesian Neural Net.
Scalable Variational Gaussian Process Classification
Nov 07, 2014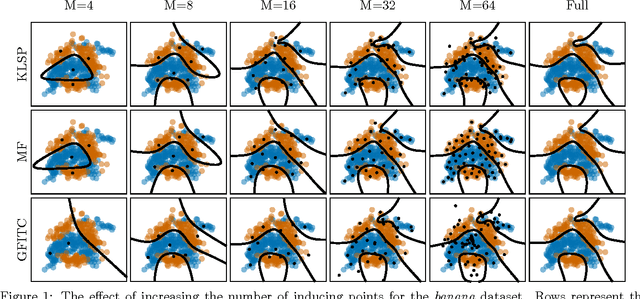
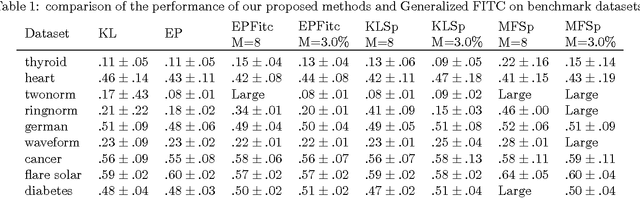
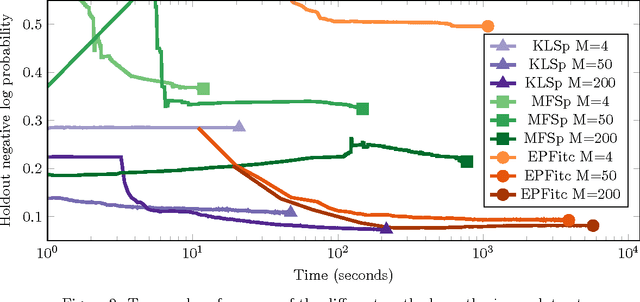
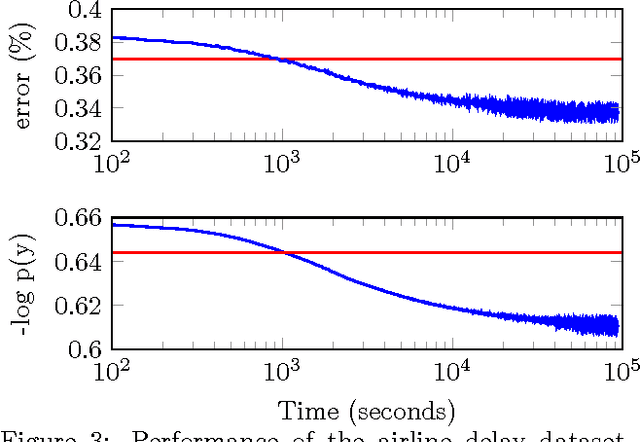
Gaussian process classification is a popular method with a number of appealing properties. We show how to scale the model within a variational inducing point framework, outperforming the state of the art on benchmark datasets. Importantly, the variational formulation can be exploited to allow classification in problems with millions of data points, as we demonstrate in experiments.
Warped Mixtures for Nonparametric Cluster Shapes
Aug 09, 2014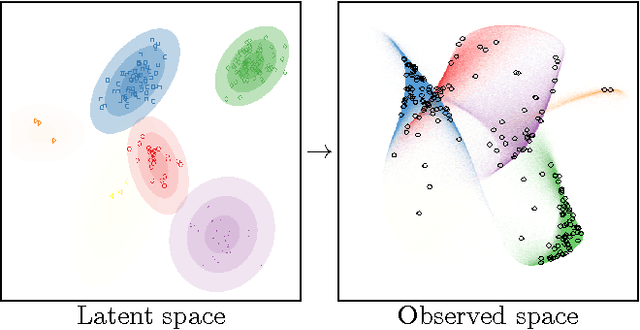


A mixture of Gaussians fit to a single curved or heavy-tailed cluster will report that the data contains many clusters. To produce more appropriate clusterings, we introduce a model which warps a latent mixture of Gaussians to produce nonparametric cluster shapes. The possibly low-dimensional latent mixture model allows us to summarize the properties of the high-dimensional clusters (or density manifolds) describing the data. The number of manifolds, as well as the shape and dimension of each manifold is automatically inferred. We derive a simple inference scheme for this model which analytically integrates out both the mixture parameters and the warping function. We show that our model is effective for density estimation, performs better than infinite Gaussian mixture models at recovering the true number of clusters, and produces interpretable summaries of high-dimensional datasets.
Classification using log Gaussian Cox processes
Jun 20, 2014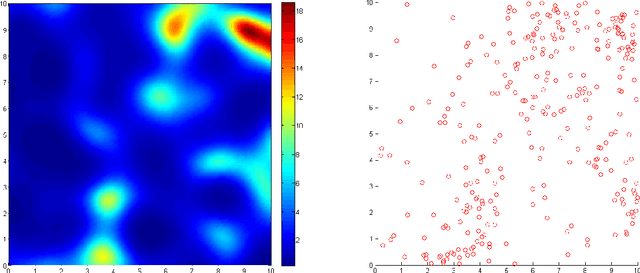

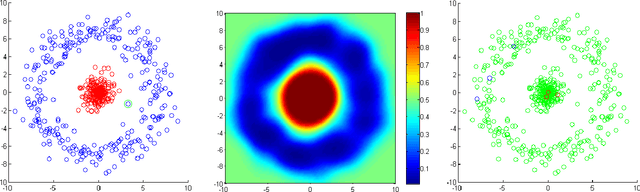

McCullagh and Yang (2006) suggest a family of classification algorithms based on Cox processes. We further investigate the log Gaussian variant which has a number of appealing properties. Conditioned on the covariates, the distribution over labels is given by a type of conditional Markov random field. In the supervised case, computation of the predictive probability of a single test point scales linearly with the number of training points and the multiclass generalization is straightforward. We show new links between the supervised method and classical nonparametric methods. We give a detailed analysis of the pairwise graph representable Markov random field, which we use to extend the model to semi-supervised learning problems, and propose an inference method based on graph min-cuts. We give the first experimental analysis on supervised and semi-supervised datasets and show good empirical performance.
Predictive Entropy Search for Efficient Global Optimization of Black-box Functions
Jun 10, 2014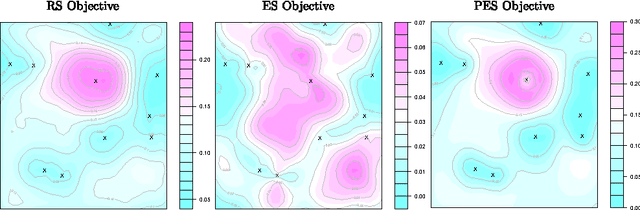
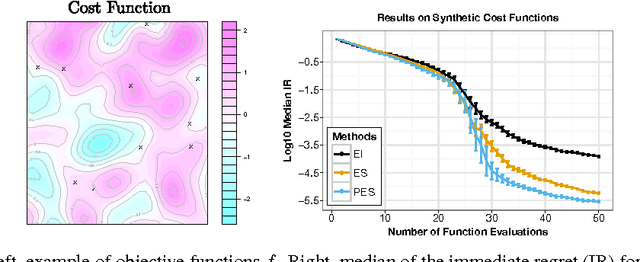
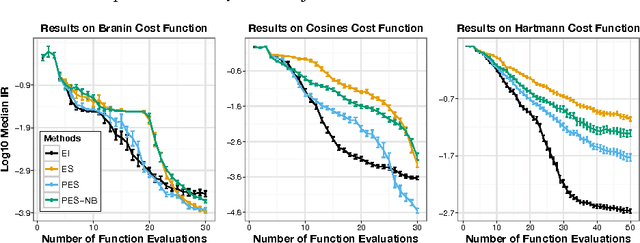
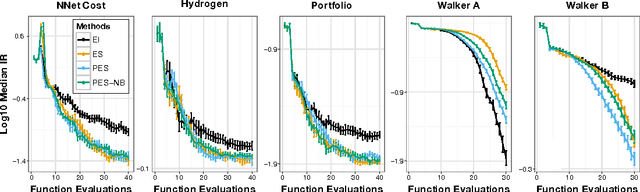
We propose a novel information-theoretic approach for Bayesian optimization called Predictive Entropy Search (PES). At each iteration, PES selects the next evaluation point that maximizes the expected information gained with respect to the global maximum. PES codifies this intractable acquisition function in terms of the expected reduction in the differential entropy of the predictive distribution. This reformulation allows PES to obtain approximations that are both more accurate and efficient than other alternatives such as Entropy Search (ES). Furthermore, PES can easily perform a fully Bayesian treatment of the model hyperparameters while ES cannot. We evaluate PES in both synthetic and real-world applications, including optimization problems in machine learning, finance, biotechnology, and robotics. We show that the increased accuracy of PES leads to significant gains in optimization performance.
Randomized Nonlinear Component Analysis
May 13, 2014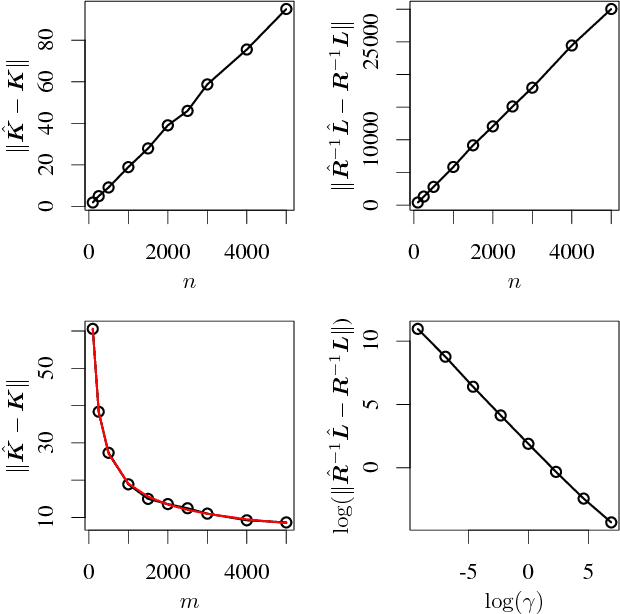
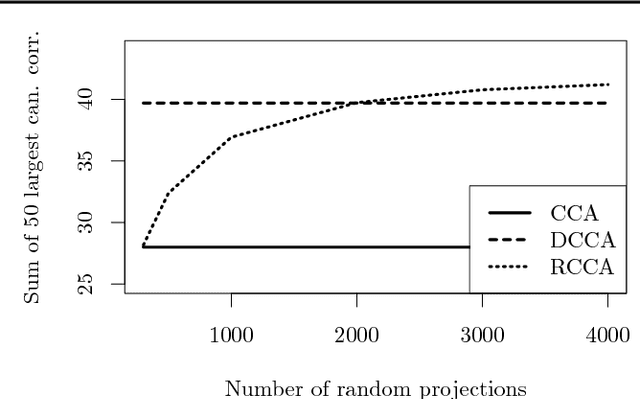
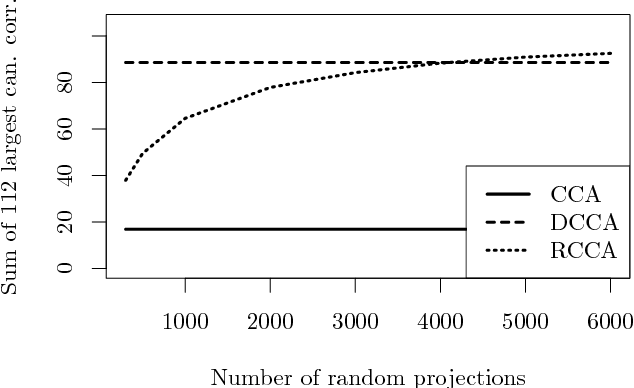
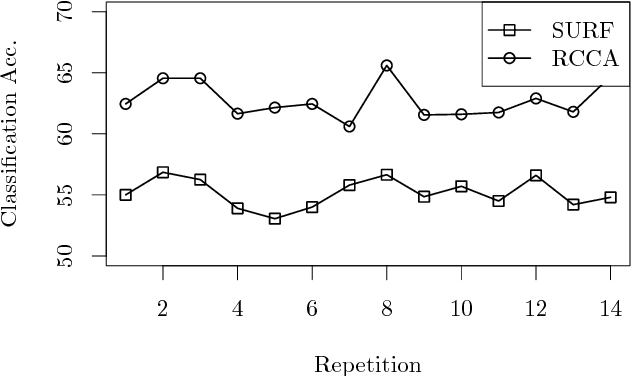
Classical methods such as Principal Component Analysis (PCA) and Canonical Correlation Analysis (CCA) are ubiquitous in statistics. However, these techniques are only able to reveal linear relationships in data. Although nonlinear variants of PCA and CCA have been proposed, these are computationally prohibitive in the large scale. In a separate strand of recent research, randomized methods have been proposed to construct features that help reveal nonlinear patterns in data. For basic tasks such as regression or classification, random features exhibit little or no loss in performance, while achieving drastic savings in computational requirements. In this paper we leverage randomness to design scalable new variants of nonlinear PCA and CCA; our ideas extend to key multivariate analysis tools such as spectral clustering or LDA. We demonstrate our algorithms through experiments on real-world data, on which we compare against the state-of-the-art. A simple R implementation of the presented algorithms is provided.