 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGFix: Perceptually Enhanced Gaussian Splatting Video Compression
Nov 10, 2025



3D Gaussian Splatting (3DGS) enhances 3D scene reconstruction through explicit representation and fast rendering, demonstrating potential benefits for various low-level vision tasks, including video compression. However, existing 3DGS-based video codecs generally exhibit more noticeable visual artifacts and relatively low compression ratios. In this paper, we specifically target the perceptual enhancement of 3DGS-based video compression, based on the assumption that artifacts from 3DGS rendering and quantization resemble noisy latents sampled during diffusion training. Building on this premise, we propose a content-adaptive framework, GFix, comprising a streamlined, single-step diffusion model that serves as an off-the-shelf neural enhancer. Moreover, to increase compression efficiency, We propose a modulated LoRA scheme that freezes the low-rank decompositions and modulates the intermediate hidden states, thereby achieving efficient adaptation of the diffusion backbone with highly compressible updates. Experimental results show that GFix delivers strong perceptual quality enhancement, outperforming GSVC with up to 72.1% BD-rate savings in LPIPS and 21.4% in FID.
Benchmarking Conventional and Learned Video Codecs with a Low-Delay Configuration
Aug 09, 2024



Recent advances in video compression have seen significant coding performance improvements with the development of new standards and learning-based video codecs. However, most of these works focus on application scenarios that allow a certain amount of system delay (e.g., Random Access mode in MPEG codecs), which is not always acceptable for live delivery. This paper conducts a comparative study of state-of-the-art conventional and learned video coding methods based on a low delay configuration. Specifically, this study includes two MPEG standard codecs (H.266/VVC VTM and JVET ECM), two AOM codecs (AV1 libaom and AVM), and two recent neural video coding models (DCVC-DC and DCVC-FM). To allow a fair and meaningful comparison, the evaluation was performed on test sequences defined in the AOM and MPEG common test conditions in the YCbCr 4:2:0 color space. The evaluation results show that the JVET ECM codecs offer the best overall coding performance among all codecs tested, with a 16.1% (based on PSNR) average BD-rate saving over AOM AVM, and 11.0% over DCVC-FM. We also observed inconsistent performance with the learned video codecs, DCVC-DC and DCVC-FM, for test content with large background motions.
Advances In Video Compression System Using Deep Neural Network: A Review And Case Studies
Jan 16, 2021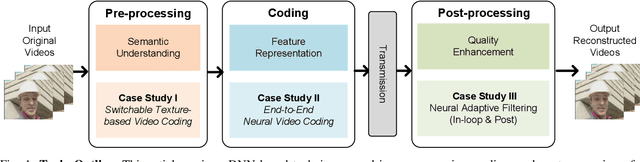
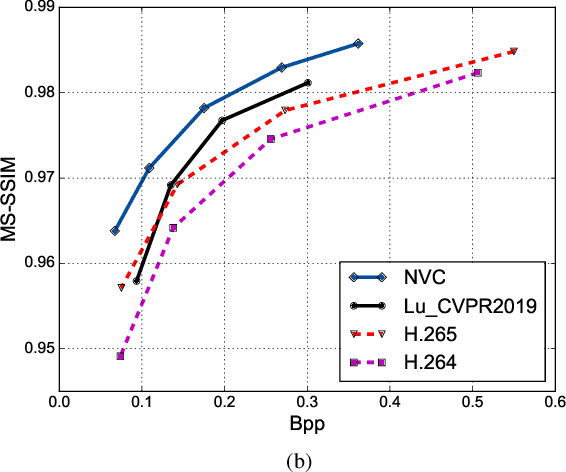

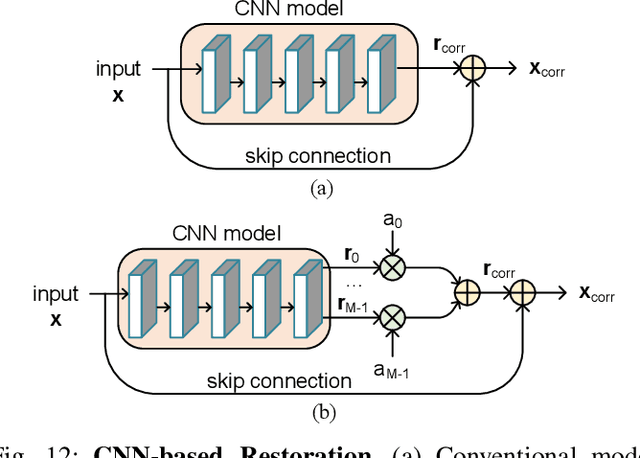
Significant advances in video compression system have been made in the past several decades to satisfy the nearly exponential growth of Internet-scale video traffic. From the application perspective, we have identified three major functional blocks including pre-processing, coding, and post-processing, that have been continuously investigated to maximize the end-user quality of experience (QoE) under a limited bit rate budget. Recently, artificial intelligence (AI) powered techniques have shown great potential to further increase the efficiency of the aforementioned functional blocks, both individually and jointly. In this article, we review extensively recent technical advances in video compression system, with an emphasis on deep neural network (DNN)-based approaches; and then present three comprehensive case studies. On pre-processing, we show a switchable texture-based video coding example that leverages DNN-based scene understanding to extract semantic areas for the improvement of subsequent video coder. On coding, we present an end-to-end neural video coding framework that takes advantage of the stacked DNNs to efficiently and compactly code input raw videos via fully data-driven learning. On post-processing, we demonstrate two neural adaptive filters to respectively facilitate the in-loop and post filtering for the enhancement of compressed frames. Finally, a companion website hosting the contents developed in this work can be accessed publicly at https://purdueviper.github.io/dnn-coding/.
Texture Segmentation Based Video Compression Using Convolutional Neural Networks
Feb 08, 2018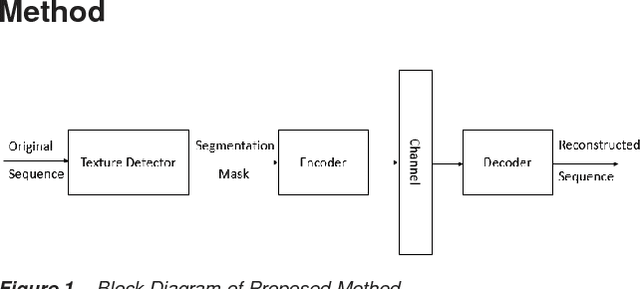

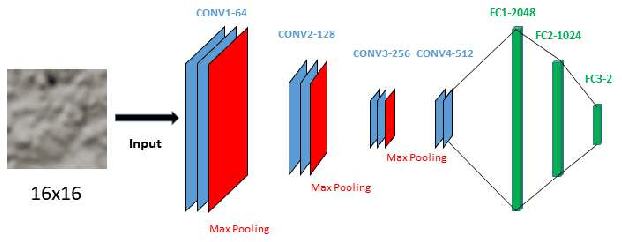
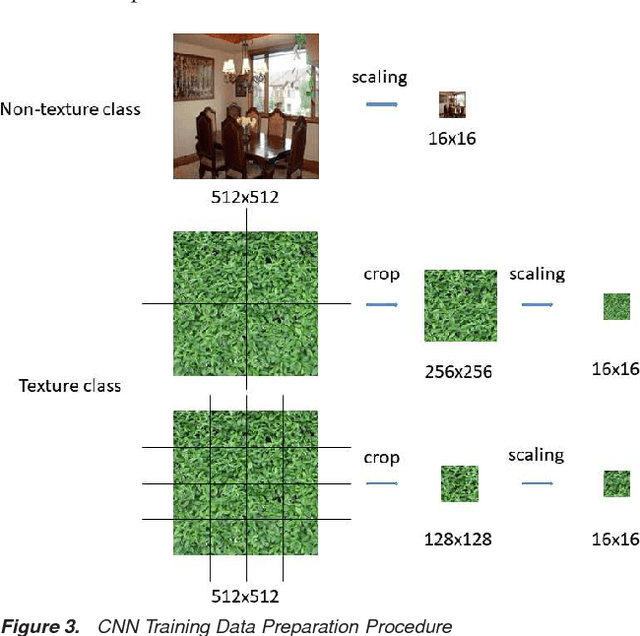
There has been a growing interest in using different approaches to improve the coding efficiency of modern video codec in recent years as demand for web-based video consumption increases. In this paper, we propose a model-based approach that uses texture analysis/synthesis to reconstruct blocks in texture regions of a video to achieve potential coding gains using the AV1 codec developed by the Alliance for Open Media (AOM). The proposed method uses convolutional neural networks to extract texture regions in a frame, which are then reconstructed using a global motion model. Our preliminary results show an increase in coding efficiency while maintaining satisfactory visual quality.