 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching LLMs How to Learn with Contextual Fine-Tuning
Mar 12, 2025Prompting Large Language Models (LLMs), or providing context on the expected model of operation, is an effective way to steer the outputs of such models to satisfy human desiderata after they have been trained. But in rapidly evolving domains, there is often need to fine-tune LLMs to improve either the kind of knowledge in their memory or their abilities to perform open ended reasoning in new domains. When human's learn new concepts, we often do so by linking the new material that we are studying to concepts we have already learned before. To that end, we ask, "can prompting help us teach LLMs how to learn". In this work, we study a novel generalization of instruction tuning, called contextual fine-tuning, to fine-tune LLMs. Our method leverages instructional prompts designed to mimic human cognitive strategies in learning and problem-solving to guide the learning process during training, aiming to improve the model's interpretation and understanding of domain-specific knowledge. We empirically demonstrate that this simple yet effective modification improves the ability of LLMs to be fine-tuned rapidly on new datasets both within the medical and financial domains.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Planning In Natural Language Improves LLM Search For Code Generation
Sep 05, 2024



While scaling training compute has led to remarkable improvements in large language models (LLMs), scaling inference compute has not yet yielded analogous gains. We hypothesize that a core missing component is a lack of diverse LLM outputs, leading to inefficient search due to models repeatedly sampling highly similar, yet incorrect generations. We empirically demonstrate that this lack of diversity can be mitigated by searching over candidate plans for solving a problem in natural language. Based on this insight, we propose PLANSEARCH, a novel search algorithm which shows strong results across HumanEval+, MBPP+, and LiveCodeBench (a contamination-free benchmark for competitive coding). PLANSEARCH generates a diverse set of observations about the problem and then uses these observations to construct plans for solving the problem. By searching over plans in natural language rather than directly over code solutions, PLANSEARCH explores a significantly more diverse range of potential solutions compared to baseline search methods. Using PLANSEARCH on top of Claude 3.5 Sonnet achieves a state-of-the-art pass@200 of 77.0% on LiveCodeBench, outperforming both the best score achieved without search (pass@1 = 41.4%) and using standard repeated sampling (pass@200 = 60.6%). Finally, we show that, across all models, search algorithms, and benchmarks analyzed, we can accurately predict performance gains due to search as a direct function of the diversity over generated ideas.
LLM Defenses Are Not Robust to Multi-Turn Human Jailbreaks Yet
Aug 27, 2024



Recent large language model (LLM) defenses have greatly improved models' ability to refuse harmful queries, even when adversarially attacked. However, LLM defenses are primarily evaluated against automated adversarial attacks in a single turn of conversation, an insufficient threat model for real-world malicious use. We demonstrate that multi-turn human jailbreaks uncover significant vulnerabilities, exceeding 70% attack success rate (ASR) on HarmBench against defenses that report single-digit ASRs with automated single-turn attacks. Human jailbreaks also reveal vulnerabilities in machine unlearning defenses, successfully recovering dual-use biosecurity knowledge from unlearned models. We compile these results into Multi-Turn Human Jailbreaks (MHJ), a dataset of 2,912 prompts across 537 multi-turn jailbreaks. We publicly release MHJ alongside a compendium of jailbreak tactics developed across dozens of commercial red teaming engagements, supporting research towards stronger LLM defenses.
A False Sense of Safety: Unsafe Information Leakage in 'Safe' AI Responses
Jul 02, 2024



Large Language Models (LLMs) are vulnerable to jailbreaks$\unicode{x2013}$methods to elicit harmful or generally impermissible outputs. Safety measures are developed and assessed on their effectiveness at defending against jailbreak attacks, indicating a belief that safety is equivalent to robustness. We assert that current defense mechanisms, such as output filters and alignment fine-tuning, are, and will remain, fundamentally insufficient for ensuring model safety. These defenses fail to address risks arising from dual-intent queries and the ability to composite innocuous outputs to achieve harmful goals. To address this critical gap, we introduce an information-theoretic threat model called inferential adversaries who exploit impermissible information leakage from model outputs to achieve malicious goals. We distinguish these from commonly studied security adversaries who only seek to force victim models to generate specific impermissible outputs. We demonstrate the feasibility of automating inferential adversaries through question decomposition and response aggregation. To provide safety guarantees, we define an information censorship criterion for censorship mechanisms, bounding the leakage of impermissible information. We propose a defense mechanism which ensures this bound and reveal an intrinsic safety-utility trade-off. Our work provides the first theoretically grounded understanding of the requirements for releasing safe LLMs and the utility costs involved.
Large Language Models Are Human-Level Prompt Engineers
Nov 03, 2022



By conditioning on natural language instructions, large language models (LLMs) have displayed impressive capabilities as general-purpose computers. However, task performance depends significantly on the quality of the prompt used to steer the model, and most effective prompts have been handcrafted by humans. Inspired by classical program synthesis and the human approach to prompt engineering, we propose Automatic Prompt Engineer (APE) for automatic instruction generation and selection. In our method, we treat the instruction as the "program," optimized by searching over a pool of instruction candidates proposed by an LLM in order to maximize a chosen score function. To evaluate the quality of the selected instruction, we evaluate the zero-shot performance of another LLM following the selected instruction. Experiments on 24 NLP tasks show that our automatically generated instructions outperform the prior LLM baseline by a large margin and achieve better or comparable performance to the instructions generated by human annotators on 19/24 tasks. We conduct extensive qualitative and quantitative analyses to explore the performance of APE. We show that APE-engineered prompts can be applied to steer models toward truthfulness and/or informativeness, as well as to improve few-shot learning performance by simply prepending them to standard in-context learning prompts. Please check out our webpage at https://sites.google.com/view/automatic-prompt-engineer.
Increasing Students' Engagement to Reminder Emails Through Multi-Armed Bandits
Aug 10, 2022
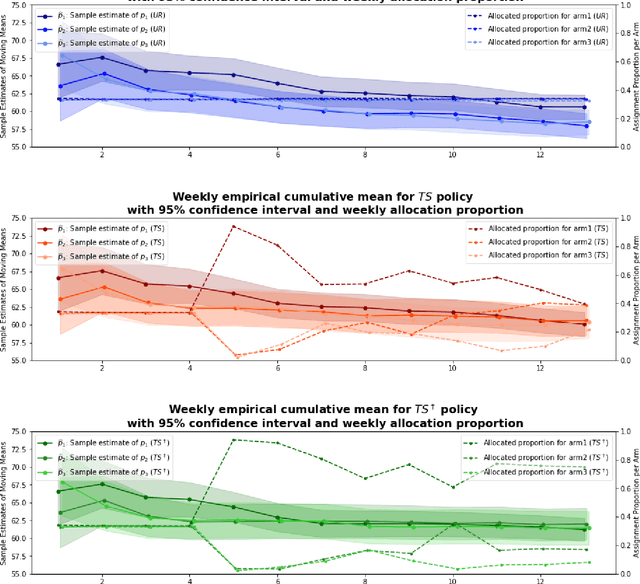


Conducting randomized experiments in education settings raises the question of how we can use machine learning techniques to improve educational interventions. Using Multi-Armed Bandits (MAB) algorithms like Thompson Sampling (TS) in adaptive experiments can increase students' chances of obtaining better outcomes by increasing the probability of assignment to the most optimal condition (arm), even before an intervention completes. This is an advantage over traditional A/B testing, which may allocate an equal number of students to both optimal and non-optimal conditions. The problem is the exploration-exploitation trade-off. Even though adaptive policies aim to collect enough information to allocate more students to better arms reliably, past work shows that this may not be enough exploration to draw reliable conclusions about whether arms differ. Hence, it is of interest to provide additional uniform random (UR) exploration throughout the experiment. This paper shows a real-world adaptive experiment on how students engage with instructors' weekly email reminders to build their time management habits. Our metric of interest is open email rates which tracks the arms represented by different subject lines. These are delivered following different allocation algorithms: UR, TS, and what we identified as TS{\dag} - which combines both TS and UR rewards to update its priors. We highlight problems with these adaptive algorithms - such as possible exploitation of an arm when there is no significant difference - and address their causes and consequences. Future directions includes studying situations where the early choice of the optimal arm is not ideal and how adaptive algorithms can address them.
Parameter efficient dendritic-tree neurons outperform perceptrons
Jul 02, 2022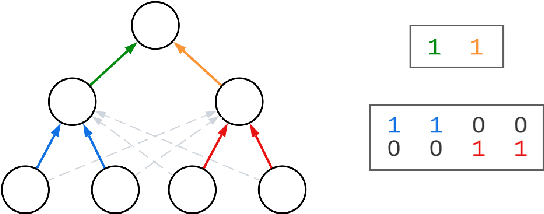


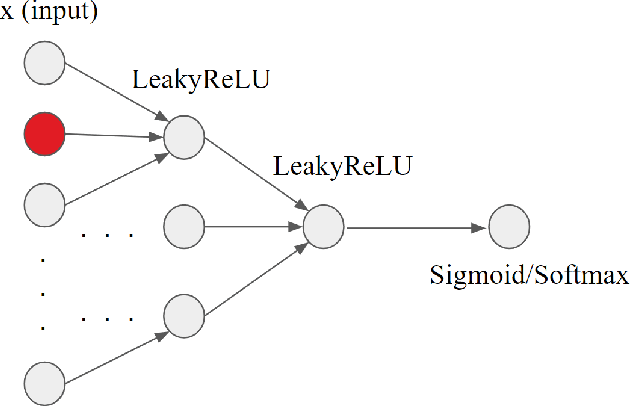
Biological neurons are more powerful than artificial perceptrons, in part due to complex dendritic input computations. Inspired to empower the perceptron with biologically inspired features, we explore the effect of adding and tuning input branching factors along with input dropout. This allows for parameter efficient non-linear input architectures to be discovered and benchmarked. Furthermore, we present a PyTorch module to replace multi-layer perceptron layers in existing architectures. Our initial experiments on MNIST classification demonstrate the accuracy and generalization improvement of dendritic neurons compared to existing perceptron architectures.