 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Scaling Laws for Large Language Models via Inverse Problems
Sep 09, 2025Large Language Models (LLMs) are large-scale pretrained models that have achieved remarkable success across diverse domains. These successes have been driven by unprecedented complexity and scale in both data and computations. However, due to the high costs of training such models, brute-force trial-and-error approaches to improve LLMs are not feasible. Inspired by the success of inverse problems in uncovering fundamental scientific laws, this position paper advocates that inverse problems can also efficiently uncover scaling laws that guide the building of LLMs to achieve the desirable performance with significantly better cost-effectiveness.
WASA: WAtermark-based Source Attribution for Large Language Model-Generated Data
Oct 01, 2023



The impressive performances of large language models (LLMs) and their immense potential for commercialization have given rise to serious concerns over the intellectual property (IP) of their training data. In particular, the synthetic texts generated by LLMs may infringe the IP of the data being used to train the LLMs. To this end, it is imperative to be able to (a) identify the data provider who contributed to the generation of a synthetic text by an LLM (source attribution) and (b) verify whether the text data from a data provider has been used to train an LLM (data provenance). In this paper, we show that both problems can be solved by watermarking, i.e., by enabling an LLM to generate synthetic texts with embedded watermarks that contain information about their source(s). We identify the key properties of such watermarking frameworks (e.g., source attribution accuracy, robustness against adversaries), and propose a WAtermarking for Source Attribution (WASA) framework that satisfies these key properties due to our algorithmic designs. Our WASA framework enables an LLM to learn an accurate mapping from the texts of different data providers to their corresponding unique watermarks, which sets the foundation for effective source attribution (and hence data provenance). Extensive empirical evaluations show that our WASA framework achieves effective source attribution and data provenance.
Assessing Attendance by Peer Information
Jun 06, 2021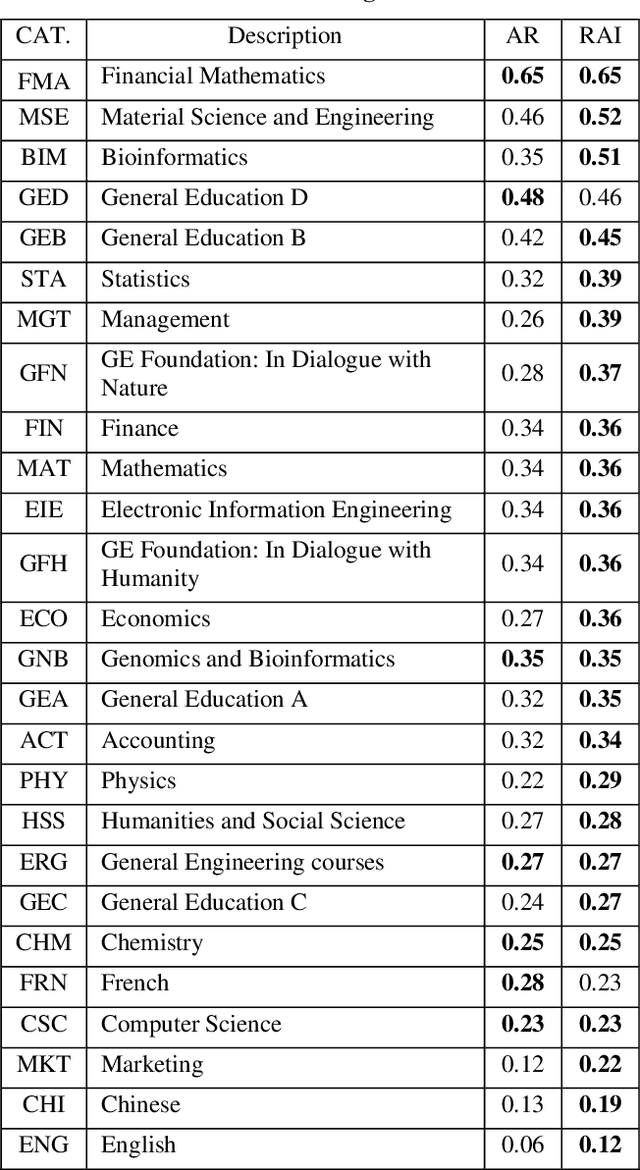
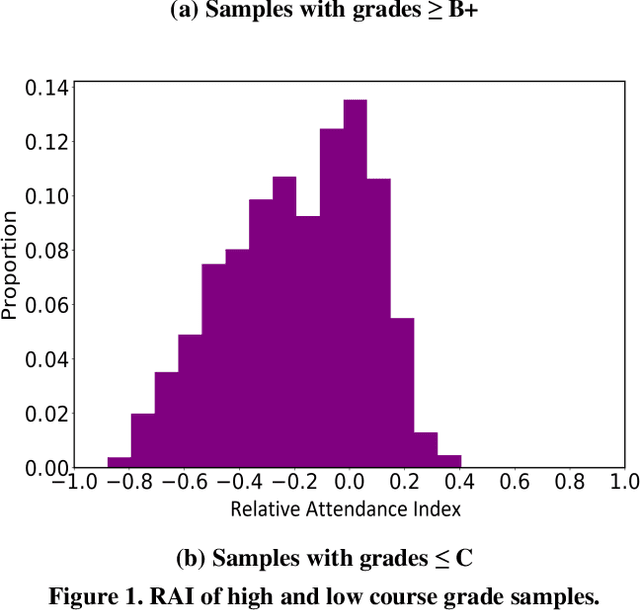
Attendance rate is an important indicator of students' study motivation, behavior and Psychological status; However, the heterogeneous nature of student attendance rates due to the course registration difference or the online/offline difference in a blended learning environment makes it challenging to compare attendance rates. In this paper, we propose a novel method called Relative Attendance Index (RAI) to measure attendance rates, which reflects students' efforts on attending courses. While traditional attendance focuses on the record of a single person or course, relative attendance emphasizes peer attendance information of relevant individuals or courses, making the comparisons of attendance more justified. Experimental results on real-life data show that RAI can indeed better reflect student engagement.