 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning-Based Energy-Aware Coverage Path Planning for Precision Agriculture
Jan 23, 2026Coverage Path Planning (CPP) is a fundamental capability for agricultural robots; however, existing solutions often overlook energy constraints, resulting in incomplete operations in large-scale or resource-limited environments. This paper proposes an energy-aware CPP framework grounded in Soft Actor-Critic (SAC) reinforcement learning, designed for grid-based environments with obstacles and charging stations. To enable robust and adaptive decision-making under energy limitations, the framework integrates Convolutional Neural Networks (CNNs) for spatial feature extraction and Long Short-Term Memory (LSTM) networks for temporal dynamics. A dedicated reward function is designed to jointly optimize coverage efficiency, energy consumption, and return-to-base constraints. Experimental results demonstrate that the proposed approach consistently achieves over 90% coverage while ensuring energy safety, outperforming traditional heuristic algorithms such as Rapidly-exploring Random Tree (RRT), Particle Swarm Optimization (PSO), and Ant Colony Optimization (ACO) baselines by 13.4-19.5% in coverage and reducing constraint violations by 59.9-88.3%. These findings validate the proposed SAC-based framework as an effective and scalable solution for energy-constrained CPP in agricultural robotics.
* Accepted by RACS '25: International Conference on Research in Adaptive and Convergent Systems, November 16-19, 2025, Ho Chi Minh, Vietnam. 10 pages, 5 figures
A Distributed Framework for Privacy-Enhanced Vision Transformers on the Edge
Dec 10, 2025Nowadays, visual intelligence tools have become ubiquitous, offering all kinds of convenience and possibilities. However, these tools have high computational requirements that exceed the capabilities of resource-constrained mobile and wearable devices. While offloading visual data to the cloud is a common solution, it introduces significant privacy vulnerabilities during transmission and server-side computation. To address this, we propose a novel distributed, hierarchical offloading framework for Vision Transformers (ViTs) that addresses these privacy challenges by design. Our approach uses a local trusted edge device, such as a mobile phone or an Nvidia Jetson, as the edge orchestrator. This orchestrator partitions the user's visual data into smaller portions and distributes them across multiple independent cloud servers. By design, no single external server possesses the complete image, preventing comprehensive data reconstruction. The final data merging and aggregation computation occurs exclusively on the user's trusted edge device. We apply our framework to the Segment Anything Model (SAM) as a practical case study, which demonstrates that our method substantially enhances content privacy over traditional cloud-based approaches. Evaluations show our framework maintains near-baseline segmentation performance while substantially reducing the risk of content reconstruction and user data exposure. Our framework provides a scalable, privacy-preserving solution for vision tasks in the edge-cloud continuum.
* 16 pages, 7 figures. Published in the Proceedings of the Tenth ACM/IEEE Symposium on Edge Computing (SEC '25), Dec 3-6, 2025, Washington, D.C., USA
D4C: Data-free Quantization for Contrastive Language-Image Pre-training Models
Nov 19, 2025Data-Free Quantization (DFQ) offers a practical solution for model compression without requiring access to real data, making it particularly attractive in privacy-sensitive scenarios. While DFQ has shown promise for unimodal models, its extension to Vision-Language Models such as Contrastive Language-Image Pre-training (CLIP) models remains underexplored. In this work, we reveal that directly applying existing DFQ techniques to CLIP results in substantial performance degradation due to two key limitations: insufficient semantic content and low intra-image diversity in synthesized samples. To tackle these challenges, we propose D4C, the first DFQ framework tailored for CLIP. D4C synthesizes semantically rich and structurally diverse pseudo images through three key components: (1) Prompt-Guided Semantic Injection aligns generated images with real-world semantics using text prompts; (2) Structural Contrastive Generation reproduces compositional structures of natural images by leveraging foreground-background contrastive synthesis; and (3) Perturbation-Aware Enhancement applies controlled perturbations to improve sample diversity and robustness. These components jointly empower D4C to synthesize images that are both semantically informative and structurally diverse, effectively bridging the performance gap of DFQ on CLIP. Extensive experiments validate the effectiveness of D4C, showing significant performance improvements on various bit-widths and models. For example, under the W4A8 setting with CLIP ResNet-50 and ViT-B/32, D4C achieves Top-1 accuracy improvement of 12.4% and 18.9% on CIFAR-10, 6.8% and 19.7% on CIFAR-100, and 1.4% and 5.7% on ImageNet-1K in zero-shot classification, respectively.
Towards Frequency-Based Explanation for Robust CNN
May 06, 2020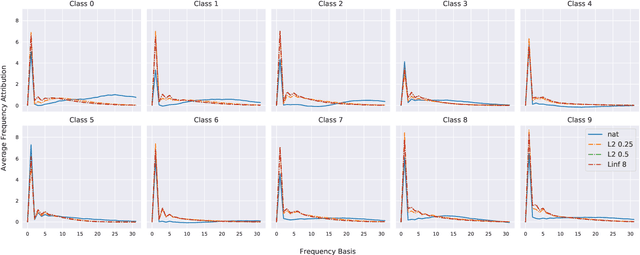
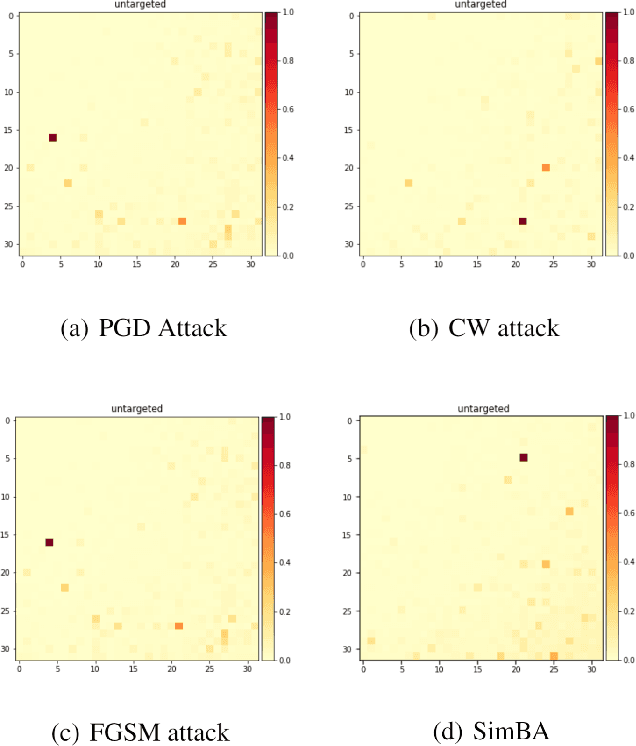
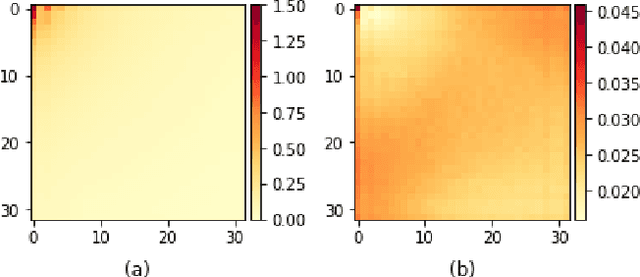
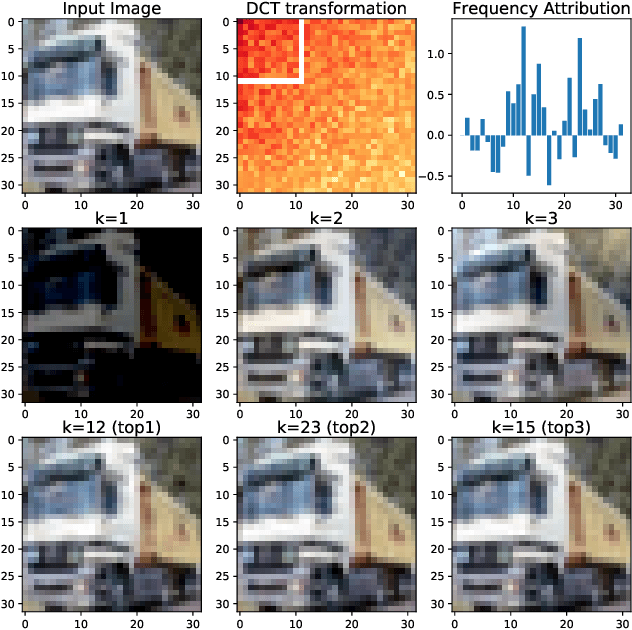
Current explanation techniques towards a transparent Convolutional Neural Network (CNN) mainly focuses on building connections between the human-understandable input features with models' prediction, overlooking an alternative representation of the input, the frequency components decomposition. In this work, we present an analysis of the connection between the distribution of frequency components in the input dataset and the reasoning process the model learns from the data. We further provide quantification analysis about the contribution of different frequency components toward the model's prediction. We show that the vulnerability of the model against tiny distortions is a result of the model is relying on the high-frequency features, the target features of the adversarial (black and white-box) attackers, to make the prediction. We further show that if the model develops stronger association between the low-frequency component with true labels, the model is more robust, which is the explanation of why adversarially trained models are more robust against tiny distortions.