 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Post-training of Speech Foundation Models for Robust Adaptation in Speech Deepfake Detection
Jun 24, 2026Large speech foundation models have shown strong potential for speech deepfake detection, but direct fine-tuning is limited by a mismatch between self-supervised pre-training objectives and spoof-specific artifacts. To address this, we propose a mix-frame post-training strategy to create localized spoof-oriented perturbations and use frame-level supervision to encourage the SSL model to learn local inconsistencies that are critical for robust spoof detection. On ASVspoof5, we achieve state-of-the-art EER 4.50% for a single model without data augmentation. On ASVspoof2021 LA/DF, it further achieves only 0.16\% absolute EER gap between LA and DF, indicating strong and balanced robustness across distinct distortion conditions. These results show that supervised post-training provides an effective and practical way to adapt speech foundation models for robust deepfake detection.
Quantizer-Aware Hierarchical Neural Codec Modeling for Speech Deepfake Detection
Mar 10, 2026Neural audio codecs discretize speech via residual vector quantization (RVQ), forming a coarse-to-fine hierarchy across quantizers. While codec models have been explored for representation learning, their discrete structure remains underutilized in speech deepfake detection. In particular, different quantization levels capture complementary acoustic cues, where early quantizers encode coarse structure and later quantizers refine residual details that reveal synthesis artifacts. Existing systems either rely on continuous encoder features or ignore this quantizer-level hierarchy. We propose a hierarchy-aware representation learning framework that models quantizer-level contributions through learnable global weighting, enabling structured codec representations aligned with forensic cues. Keeping the speech encoder backbone frozen and updating only 4.4% additional parameters, our method achieves relative EER reductions of 46.2% on ASVspoof 2019 and 13.9% on ASVspoof5 over strong baselines.
Towards Quantifying and Reducing Language Mismatch Effects in Cross-Lingual Speech Anti-Spoofing
Sep 12, 2024



The effects of language mismatch impact speech anti-spoofing systems, while investigations and quantification of these effects remain limited. Existing anti-spoofing datasets are mainly in English, and the high cost of acquiring multilingual datasets hinders training language-independent models. We initiate this work by evaluating top-performing speech anti-spoofing systems that are trained on English data but tested on other languages, observing notable performance declines. We propose an innovative approach - Accent-based data expansion via TTS (ACCENT), which introduces diverse linguistic knowledge to monolingual-trained models, improving their cross-lingual capabilities. We conduct experiments on a large-scale dataset consisting of over 3 million samples, including 1.8 million training samples and nearly 1.2 million testing samples across 12 languages. The language mismatch effects are preliminarily quantified and remarkably reduced over 15% by applying the proposed ACCENT. This easily implementable method shows promise for multilingual and low-resource language scenarios.
FreeRide: Harvesting Bubbles in Pipeline Parallelism
Sep 11, 2024



The occurrence of bubbles in pipeline parallelism is an inherent limitation that can account for more than 40% of the large language model (LLM) training time and is one of the main reasons for the underutilization of GPU resources in LLM training. Harvesting these bubbles for GPU side tasks can increase resource utilization and reduce training costs but comes with challenges. First, because bubbles are discontinuous with various shapes, programming side tasks becomes difficult while requiring excessive engineering effort. Second, a side task can compete with pipeline training for GPU resources and incur significant overhead. To address these challenges, we propose FreeRide, a system designed to harvest bubbles in pipeline parallelism for side tasks. FreeRide provides programmers with interfaces to implement side tasks easily, manages bubbles and side tasks during pipeline training, and controls access to GPU resources by side tasks to reduce overhead. We demonstrate that FreeRide achieves 7.8% average cost savings with a negligible overhead of about 1% in training LLMs while serving model training, graph analytics, and image processing side tasks.
Speech Foundation Model Ensembles for the Controlled Singing Voice Deepfake Detection (CtrSVDD) Challenge 2024
Sep 03, 2024



This work details our approach to achieving a leading system with a 1.79% pooled equal error rate (EER) on the evaluation set of the Controlled Singing Voice Deepfake Detection (CtrSVDD). The rapid advancement of generative AI models presents significant challenges for detecting AI-generated deepfake singing voices, attracting increased research attention. The Singing Voice Deepfake Detection (SVDD) Challenge 2024 aims to address this complex task. In this work, we explore the ensemble methods, utilizing speech foundation models to develop robust singing voice anti-spoofing systems. We also introduce a novel Squeeze-and-Excitation Aggregation (SEA) method, which efficiently and effectively integrates representation features from the speech foundation models, surpassing the performance of our other individual systems. Evaluation results confirm the efficacy of our approach in detecting deepfake singing voices. The codes can be accessed at https://github.com/Anmol2059/SVDD2024.
Attentive Merging of Hidden Embeddings from Pre-trained Speech Model for Anti-spoofing Detection
Jun 12, 2024



Self-supervised learning (SSL) speech representation models, trained on large speech corpora, have demonstrated effectiveness in extracting hierarchical speech embeddings through multiple transformer layers. However, the behavior of these embeddings in specific tasks remains uncertain. This paper investigates the multi-layer behavior of the WavLM model in anti-spoofing and proposes an attentive merging method to leverage the hierarchical hidden embeddings. Results demonstrate the feasibility of fine-tuning WavLM to achieve the best equal error rate (EER) of 0.65%, 3.50%, and 3.19% on the ASVspoof 2019LA, 2021LA, and 2021DF evaluation sets, respectively. Notably, We find that the early hidden transformer layers of the WavLM large model contribute significantly to anti-spoofing task, enabling computational efficiency by utilizing a partial pre-trained model.
Multi-Tones' Phase Coding of Interaural Time Difference by Spiking Neural Network
Jul 07, 2020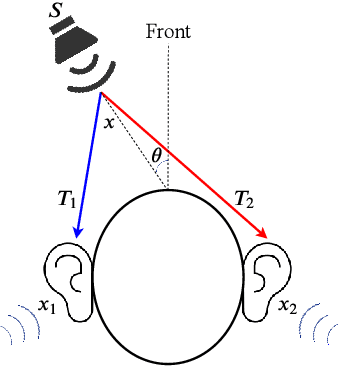
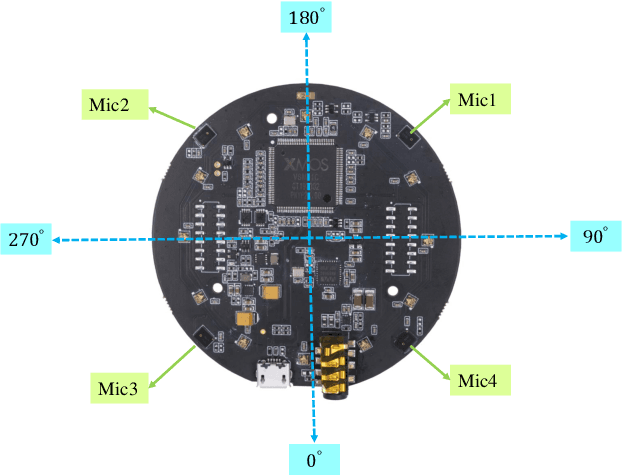

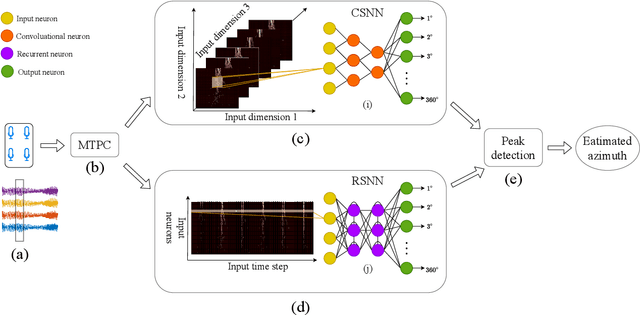
Inspired by the mammal's auditory localization pathway, in this paper we propose a pure spiking neural network (SNN) based computational model for precise sound localization in the noisy real-world environment, and implement this algorithm in a real-time robotic system with a microphone array. The key of this model relies on the MTPC scheme, which encodes the interaural time difference (ITD) cues into spike patterns. This scheme naturally follows the functional structures of the human auditory localization system, rather than artificially computing of time difference of arrival. Besides, it highlights the advantages of SNN, such as event-driven and power efficiency. The MTPC is pipelined with two different SNN architectures, the convolutional SNN and recurrent SNN, by which it shows the applicability to various SNNs. This proposal is evaluated by the microphone collected location-dependent acoustic data, in a real-world environment with noise, obstruction, reflection, or other affects. The experiment results show a mean error azimuth of 1~3 degrees, which surpasses the accuracy of the other biologically plausible neuromorphic approach for sound source localization.
Neural Population Coding for Effective Temporal Classification
Sep 26, 2019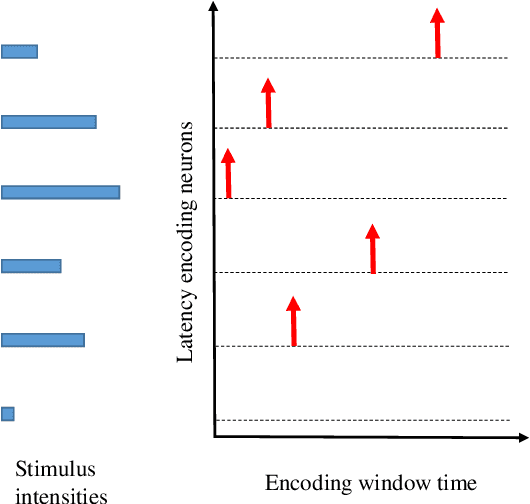
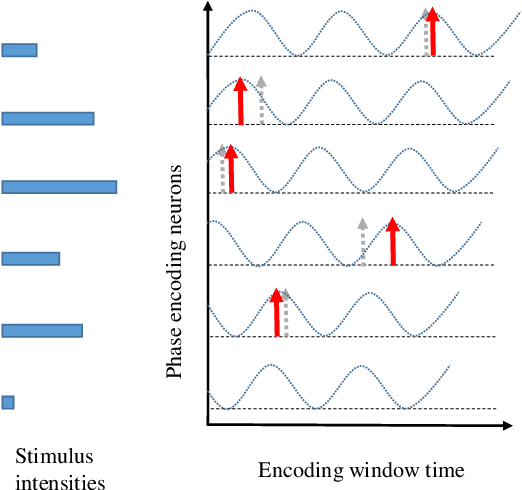
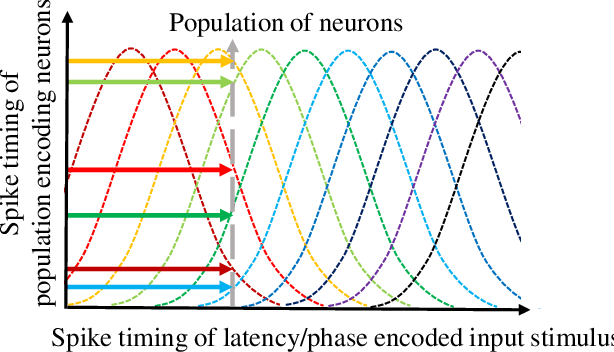
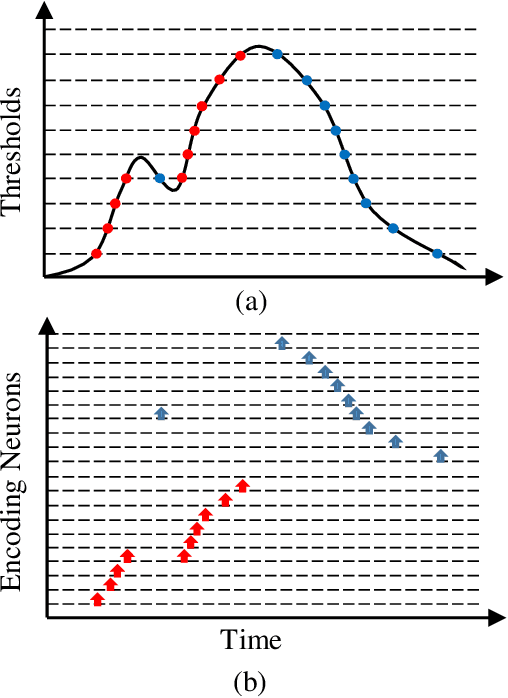
Neural encoding plays an important role in faithfully describing the temporally rich patterns, whose instances include human speech and environmental sounds. For tasks that involve classifying such spatio-temporal patterns with the Spiking Neural Networks (SNNs), how these patterns are encoded directly influence the difficulty of the task. In this paper, we compare several existing temporal and population coding schemes and evaluate them on both speech (TIDIGITS) and sound (RWCP) datasets. We show that, with population neural codings, the encoded patterns are linearly separable using the Support Vector Machine (SVM). We note that the population neural codings effectively project the temporal information onto the spatial domain, thus improving linear separability in the spatial dimension, achieving an accuracy of 95\% and 100\% for TIDIGITS and RWCP datasets classified using the SVM, respectively. This observation suggests that an effective neural coding scheme greatly simplifies the classification problem such that a simple linear classifier would suffice. The above datasets are then classified using the Tempotron, an SNN-based classifier. SNN classification results agree with the SVM findings that population neural codings help to improve classification accuracy. Hence, other than the learning algorithm, effective neural encoding is just as important as an SNN designed to recognize spatio-temporal patterns. It is an often neglected but powerful abstraction that deserves further study.
An efficient and perceptually motivated auditory neural encoding and decoding algorithm for spiking neural networks
Sep 04, 2019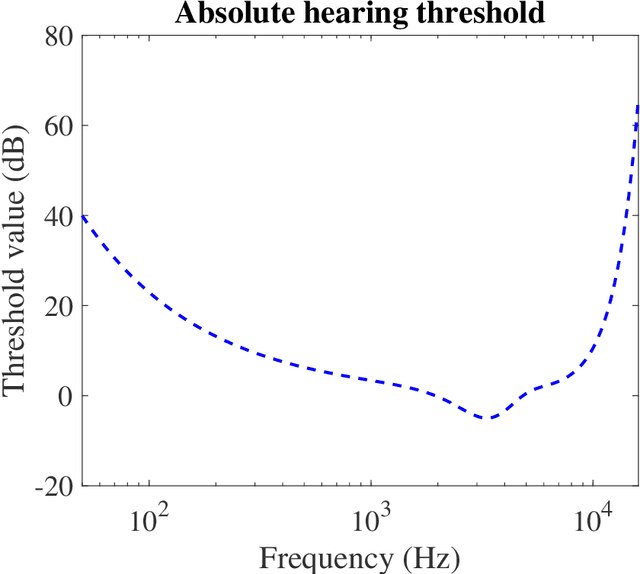
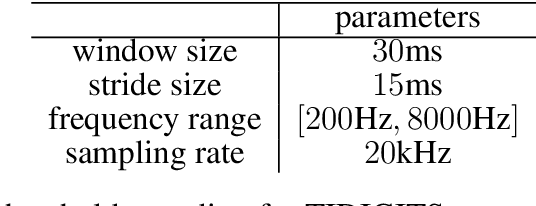
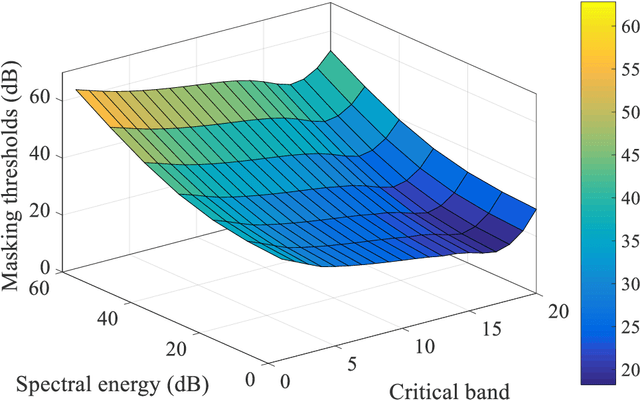
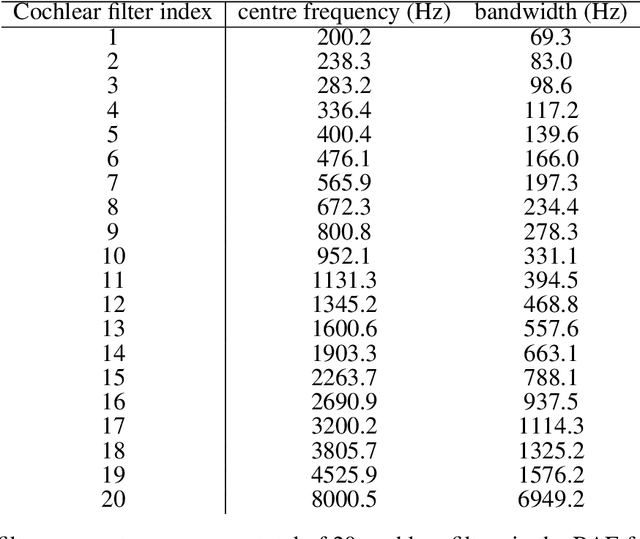
Auditory front-end is an integral part of a spiking neural network (SNN) when performing auditory cognitive tasks. It encodes the temporal dynamic stimulus, such as speech and audio, into an efficient, effective and reconstructable spike pattern to facilitate the subsequent processing. However, most of the auditory front-ends in current studies have not made use of recent findings in psychoacoustics and physiology concerning human listening. In this paper, we propose a neural encoding and decoding scheme that is optimized for speech processing. The neural encoding scheme, that we call Biologically plausible Auditory Encoding (BAE), emulates the functions of the perceptual components of the human auditory system, that include the cochlear filter bank, the inner hair cells, auditory masking effects from psychoacoustic models, and the spike neural encoding by the auditory nerve. We evaluate the perceptual quality of the BAE scheme using PESQ; the performance of the BAE based on speech recognition experiments. Finally, we also built and published two spike-version of speech datasets: the Spike-TIDIGITS and the Spike-TIMIT, for researchers to use and benchmarking of future SNN research.