 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Residual Stream Is All You Need: On the Redundancy of the KV Cache in Transformer Inference
Mar 20, 2026The key-value (KV) cache is widely treated as essential state in transformer inference, and a large body of work engineers policies to compress, evict, or approximate its entries. We prove that this state is entirely redundant: keys and values at every layer are deterministic projections of the residual stream, and recomputing them from a single residual vector per token incurs exactly zero reconstruction error, not approximately, but bit-identically. We verify this across six models from four architecture families (135M to 4B parameters). Cross-task residual patching at every layer produces D_KL = 0 between patched and original output distributions, confirming that the residual stream satisfies a Markov property and is the sole information-carrying state. Removing the cache entirely and recomputing from scratch yields token-identical output under greedy decoding on all models tested. We build on this result with KV-Direct, a bounded-memory inference scheme that checkpoints residual vectors (5 KB per token on Gemma 3-4B) instead of full KV pairs (136 KB), recomputing keys and values on demand. Over 20 conversation turns, KV-Direct holds peak memory at 42 MB while the standard cache grows past 103 MB. Against five eviction baselines (H2O, StreamingLLM, SnapKV, TOVA, window-only), KV-Direct maintains 100% token match at every cache budget; all baselines degrade to 5-28%. A per-operation latency analysis shows recomputation runs up to 5x faster than reading cached tensors at moderate batch sizes. Code is available at https://github.com/Kaleemullahqasim/KV-Direct.
VERIFY-RL: Verifiable Recursive Decomposition for Reinforcement Learning in Mathematical Reasoning
Feb 07, 2026Training language models to solve complex mathematical problems benefits from curriculum learning progressively training on simpler subproblems. However, existing decomposition methods are often heuristic, offering no guarantees that subproblems are simpler, that solving them aids the parent task, or that their relationships are mathematically grounded. We observe that symbolic differentiation provides a natural structure for verified decomposition: calculus rules explicitly define how expressions reduce to simpler components with provable properties. We introduce Verify-RL, a framework where every parent-child decomposition satisfies three verifiable conditions: strictly decreasing structural complexity, solution containment, and formal rule derivation. Unlike heuristic methods where a significant fraction of decompositions are invalid our properties admit automatic verification through symbolic computation, achieving "verification by construction" Experiments demonstrate that eliminating invalid decompositions yields sizable gains, accuracy on the hardest problems more than doubles from 32% to 68%, with a 40% relative improvement overall.
Accelerating Training Speed of Tiny Recursive Models via Curriculum Guided Adaptive Recursion
Nov 11, 2025Recursive reasoning models achieve remarkable performance on complex reasoning tasks through iterative refinement, enabling tiny networks to match large language models thousands of times their size. However, training remains computationally expensive, prior work reporting approximately 36 GPU-hours per dataset, limiting broader adoption and research. We propose CGAR, a novel training methodology that applies curriculum learning to architectural depth rather than traditional data ordering. CGAR introduces two synergistic components: Progressive Depth Curriculum dynamically adjusts recursion depth from shallow to deep configurations during training, preventing early overfitting while reducing computational cost, and Hierarchical Supervision Weighting applies exponentially decaying importance to supervision steps, aligning loss weighting with observed gradient magnitude decay. On Sudoku-Extreme with 423,168 test puzzles, CGAR achieves 1.71x training speedup (10.93 to 6.38 hours, 42% cost reduction) with only 0.63% accuracy drop (86.65% to 86.02%). Systematic ablations reveal Progressive Depth Curriculum alone achieves 2.26x speedup with 85.47% accuracy, demonstrating a rare Pareto improvement where architectural curriculum simultaneously enhances training efficiency and solution quality. CGAR-trained models exhibit superior inference efficiency with 100% halting accuracy and 11% fewer reasoning steps. Our work demonstrates that principled curriculum on architectural depth enables efficient training of recursive reasoning models on modest hardware. Code and models: https://github.com/Kaleemullahqasim/CGAR and https://huggingface.co/Kaleemullah/trm-cgar-sudoku
Recursive Decomposition of Logical Thoughts: Framework for Superior Reasoning and Knowledge Propagation in Large Language Models
Jan 03, 2025



Enhancing the reasoning capabilities of Large Language Models remains a critical challenge in artificial intelligence. We introduce RDoLT, Recursive Decomposition of Logical Thought prompting, a novel framework that significantly boosts LLM reasoning performance. RDoLT is built on three key innovations: (1) recursively breaking down complex reasoning tasks into sub-tasks of progressive complexity; (2) employing an advanced selection and scoring mechanism to identify the most promising reasoning thoughts; and (3) integrating a knowledge propagation module that mimics human learning by keeping track of strong and weak thoughts for information propagation. Our approach was evaluated across multiple benchmarks, including GSM8K, SVAMP, MultiArith, LastLetterConcatenation, and Gaokao2023 Math. The results demonstrate that RDoLT consistently outperforms existing state-of-the-art techniques, achieving a 90.98 percent accuracy on GSM8K with ChatGPT-4, surpassing state-of-the-art techniques by 6.28 percent. Similar improvements were observed on other benchmarks, with accuracy gains ranging from 5.5 percent to 6.75 percent. These findings highlight RDoLT's potential to advance prompt engineering, offering a more effective and generalizable approach to complex reasoning tasks.
FreeRide: Harvesting Bubbles in Pipeline Parallelism
Sep 11, 2024



The occurrence of bubbles in pipeline parallelism is an inherent limitation that can account for more than 40% of the large language model (LLM) training time and is one of the main reasons for the underutilization of GPU resources in LLM training. Harvesting these bubbles for GPU side tasks can increase resource utilization and reduce training costs but comes with challenges. First, because bubbles are discontinuous with various shapes, programming side tasks becomes difficult while requiring excessive engineering effort. Second, a side task can compete with pipeline training for GPU resources and incur significant overhead. To address these challenges, we propose FreeRide, a system designed to harvest bubbles in pipeline parallelism for side tasks. FreeRide provides programmers with interfaces to implement side tasks easily, manages bubbles and side tasks during pipeline training, and controls access to GPU resources by side tasks to reduce overhead. We demonstrate that FreeRide achieves 7.8% average cost savings with a negligible overhead of about 1% in training LLMs while serving model training, graph analytics, and image processing side tasks.
Robustly Optimized Deep Feature Decoupling Network for Fatty Liver Diseases Detection
Jun 25, 2024Current medical image classification efforts mainly aim for higher average performance, often neglecting the balance between different classes. This can lead to significant differences in recognition accuracy between classes and obvious recognition weaknesses. Without the support of massive data, deep learning faces challenges in fine-grained classification of fatty liver. In this paper, we propose an innovative deep learning framework that combines feature decoupling and adaptive adversarial training. Firstly, we employ two iteratively compressed decouplers to supervised decouple common features and specific features related to fatty liver in abdominal ultrasound images. Subsequently, the decoupled features are concatenated with the original image after transforming the color space and are fed into the classifier. During adversarial training, we adaptively adjust the perturbation and balance the adversarial strength by the accuracy of each class. The model will eliminate recognition weaknesses by correctly classifying adversarial samples, thus improving recognition robustness. Finally, the accuracy of our method improved by 4.16%, achieving 82.95%. As demonstrated by extensive experiments, our method is a generalized learning framework that can be directly used to eliminate the recognition weaknesses of any classifier while improving its average performance. Code is available at https://github.com/HP-ML/MICCAI2024.
Random Euler Complex-Valued Nonlinear Filters
Jan 02, 2018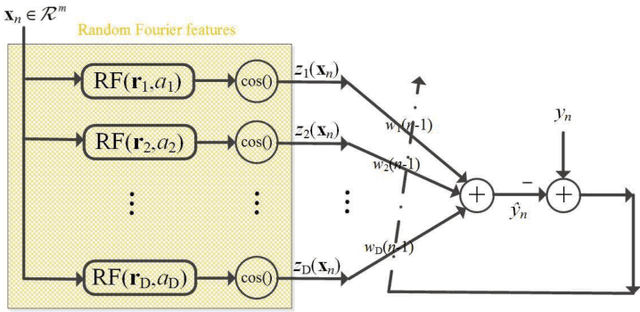
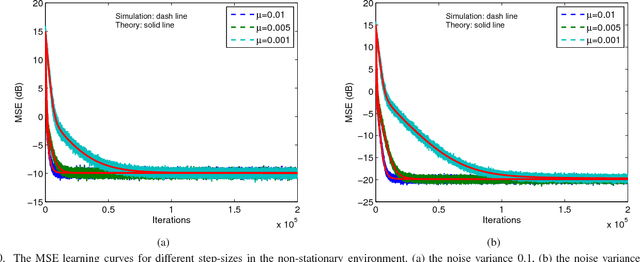
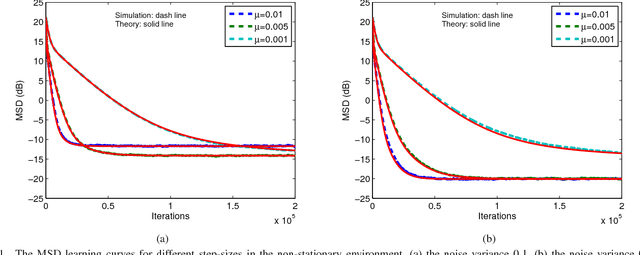
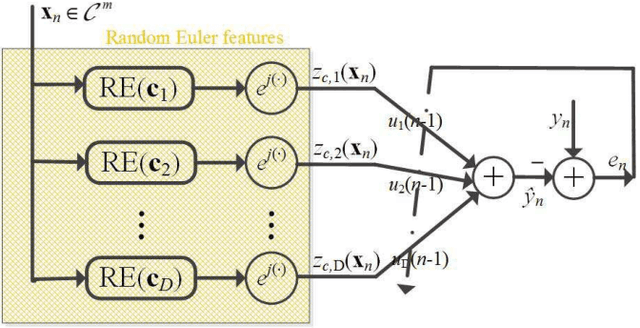
Over the last decade, both the neural network and kernel adaptive filter have successfully been used for nonlinear signal processing. However, they suffer from high computational cost caused by their complex/growing network structures. In this paper, we propose two random Euler filters for complex-valued nonlinear filtering problem, i.e., linear random Euler complex-valued filter (LRECF) and its widely-linear version (WLRECF), which possess a simple and fixed network structure. The transient and steady-state performances are studied in a non-stationary environment. The analytical minimum mean square error (MSE) and optimum step-size are derived. Finally, numerical simulations on complex-valued nonlinear system identification and nonlinear channel equalization are presented to show the effectiveness of the proposed methods.