 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Hypothesis Testing for Correlated Combinatorial Anomaly Detection
Jan 24, 2026We study the problem of identifying an anomalous subset of streams under correlated noise, motivated by monitoring and security in cyber-physical systems. This problem can be viewed as a form of combinatorial pure exploration, where each stream plays the role of an arm and measurements must be allocated sequentially under uncertainty. Existing combinatorial bandit and hypothesis testing methods typically assume independent observations and fail to exploit correlation for efficient measurement design. We propose ECC-AHT, an adaptive algorithm that selects continuous, constrained measurements to maximize Chernoff information between competing hypotheses, enabling active noise cancellation through differential sensing. ECC-AHT achieves optimal sample complexity guarantees and significantly outperforms state-of-the-art baselines in both synthetic and real-world correlated environments. The code is available on https://github.com/VincentdeCristo/ECC-AHT
EVM-Fusion: An Explainable Vision Mamba Architecture with Neural Algorithmic Fusion
May 26, 2025



Medical image classification is critical for clinical decision-making, yet demands for accuracy, interpretability, and generalizability remain challenging. This paper introduces EVM-Fusion, an Explainable Vision Mamba architecture featuring a novel Neural Algorithmic Fusion (NAF) mechanism for multi-organ medical image classification. EVM-Fusion leverages a multipath design, where DenseNet and U-Net based pathways, enhanced by Vision Mamba (Vim) modules, operate in parallel with a traditional feature pathway. These diverse features are dynamically integrated via a two-stage fusion process: cross-modal attention followed by the iterative NAF block, which learns an adaptive fusion algorithm. Intrinsic explainability is embedded through path-specific spatial attention, Vim {\Delta}-value maps, traditional feature SE-attention, and cross-modal attention weights. Experiments on a diverse 9-class multi-organ medical image dataset demonstrate EVM-Fusion's strong classification performance, achieving 99.75% test accuracy and provide multi-faceted insights into its decision-making process, highlighting its potential for trustworthy AI in medical diagnostics.
DeepMath-Creative: A Benchmark for Evaluating Mathematical Creativity of Large Language Models
May 13, 2025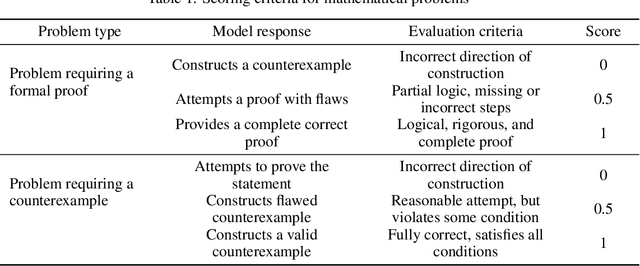
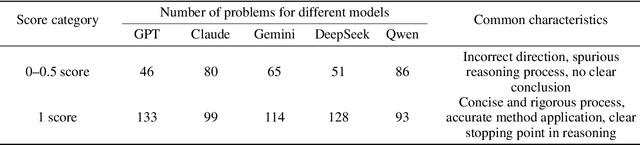
To advance the mathematical proficiency of large language models (LLMs), the DeepMath team has launched an open-source initiative aimed at developing an open mathematical LLM and systematically evaluating its mathematical creativity. This paper represents the initial contribution of this initiative. While recent developments in mathematical LLMs have predominantly emphasized reasoning skills, as evidenced by benchmarks on elementary to undergraduate-level mathematical tasks, the creative capabilities of these models have received comparatively little attention, and evaluation datasets remain scarce. To address this gap, we propose an evaluation criteria for mathematical creativity and introduce DeepMath-Creative, a novel, high-quality benchmark comprising constructive problems across algebra, geometry, analysis, and other domains. We conduct a systematic evaluation of mainstream LLMs' creative problem-solving abilities using this dataset. Experimental results show that even under lenient scoring criteria -- emphasizing core solution components and disregarding minor inaccuracies, such as small logical gaps, incomplete justifications, or redundant explanations -- the best-performing model, O3 Mini, achieves merely 70% accuracy, primarily on basic undergraduate-level constructive tasks. Performance declines sharply on more complex problems, with models failing to provide substantive strategies for open problems. These findings suggest that, although current LLMs display a degree of constructive proficiency on familiar and lower-difficulty problems, such performance is likely attributable to the recombination of memorized patterns rather than authentic creative insight or novel synthesis.
Use neural networks to recognize students' handwritten letters and incorrect symbols
Sep 12, 2023Correcting students' multiple-choice answers is a repetitive and mechanical task that can be considered an image multi-classification task. Assuming possible options are 'abcd' and the correct option is one of the four, some students may write incorrect symbols or options that do not exist. In this paper, five classifications were set up - four for possible correct options and one for other incorrect writing. This approach takes into account the possibility of non-standard writing options.