 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 3D Coarse-to-Fine Framework for Volumetric Medical Image Segmentation
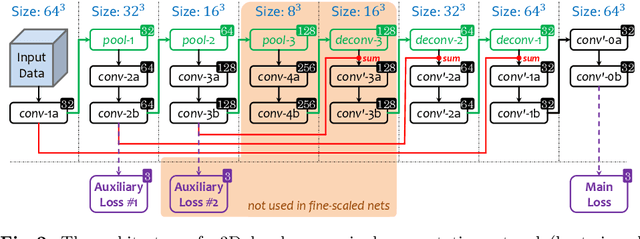
Aug 02, 2018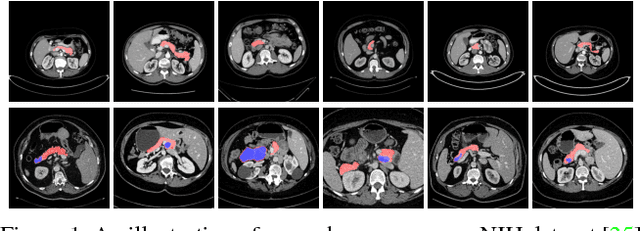


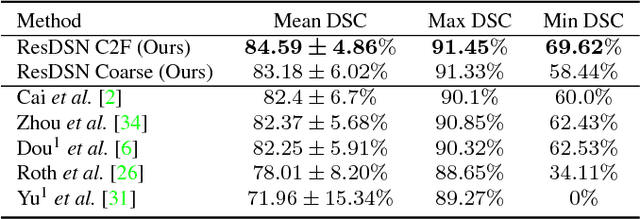
In this paper, we adopt 3D Convolutional Neural Networks to segment volumetric medical images. Although deep neural networks have been proven to be very effective on many 2D vision tasks, it is still challenging to apply them to 3D tasks due to the limited amount of annotated 3D data and limited computational resources. We propose a novel 3D-based coarse-to-fine framework to effectively and efficiently tackle these challenges. The proposed 3D-based framework outperforms the 2D counterpart to a large margin since it can leverage the rich spatial infor- mation along all three axes. We conduct experiments on two datasets which include healthy and pathological pancreases respectively, and achieve the current state-of-the-art in terms of Dice-S{\o}rensen Coefficient (DSC). On the NIH pancreas segmentation dataset, we outperform the previous best by an average of over 2%, and the worst case is improved by 7% to reach almost 70%, which indicates the reliability of our framework in clinical applications.
Multi-Scale Coarse-to-Fine Segmentation for Screening Pancreatic Ductal Adenocarcinoma
Jul 09, 2018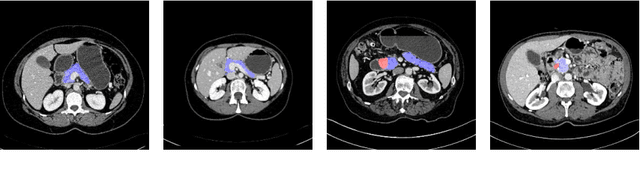

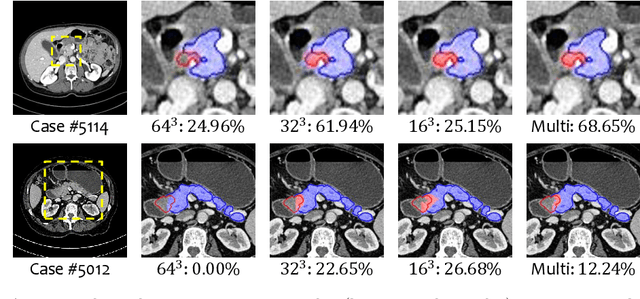
This paper proposes an intuitive approach to finding pancreatic ductal adenocarcinoma (PDAC), the most common type of pancreatic cancer, by checking abdominal CT scans. Our idea is named segmentation-for-classification (S4C), which classifies a volume by checking if at least a sufficient number of voxels is segmented as the tumor. In order to deal with tumors with different scales, we train volumetric segmentation networks with multi-scale inputs, and test them in a coarse-to-fine flowchart. A post-processing module is used to filter out outliers and reduce false alarms. We perform a case study on our dataset containing 439 CT scans, in which 136 cases were diagnosed with PDAC and 303 cases are normal. Our approach reports a sensitivity of 94.1% at a specificity of 98.5%, with an average tumor segmentation accuracy of 56.46% over all PDAC cases.
Bridging the Gap Between 2D and 3D Organ Segmentation with Volumetric Fusion Net
Jun 09, 2018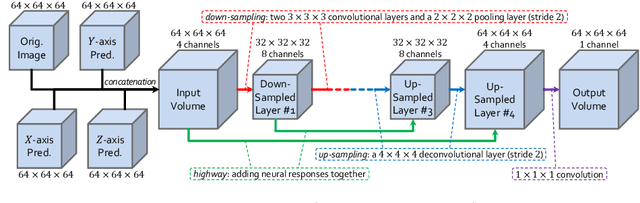
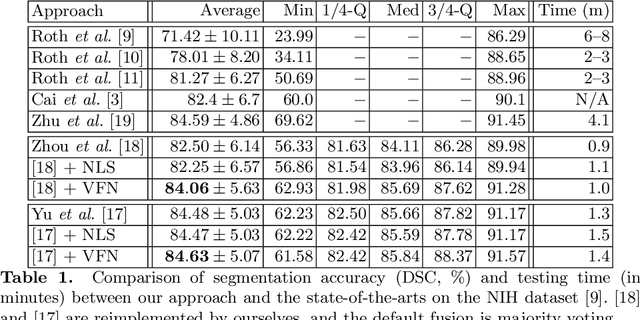

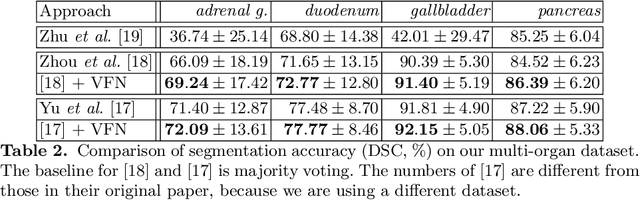
There has been a debate on whether to use 2D or 3D deep neural networks for volumetric organ segmentation. Both 2D and 3D models have their advantages and disadvantages. In this paper, we present an alternative framework, which trains 2D networks on different viewpoints for segmentation, and builds a 3D Volumetric Fusion Net (VFN) to fuse the 2D segmentation results. VFN is relatively shallow and contains much fewer parameters than most 3D networks, making our framework more efficient at integrating 3D information for segmentation. We train and test the segmentation and fusion modules individually, and propose a novel strategy, named cross-cross-augmentation, to make full use of the limited training data. We evaluate our framework on several challenging abdominal organs, and verify its superiority in segmentation accuracy and stability over existing 2D and 3D approaches.
Object Recognition with and without Objects
May 25, 2017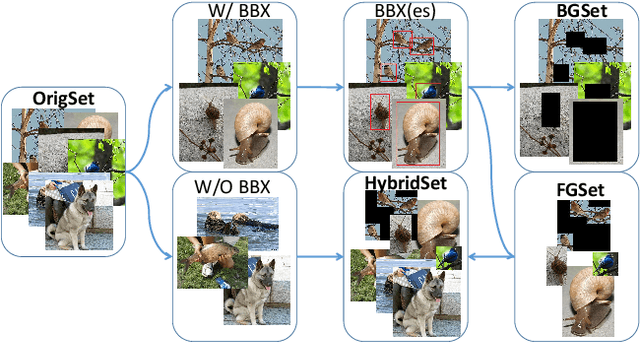

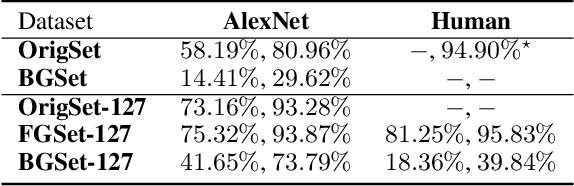
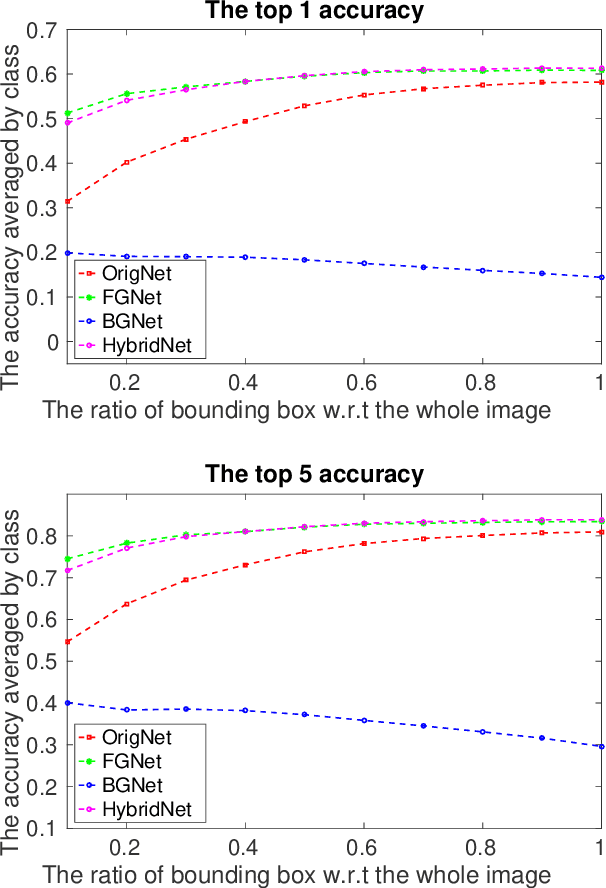
While recent deep neural networks have achieved a promising performance on object recognition, they rely implicitly on the visual contents of the whole image. In this paper, we train deep neural net- works on the foreground (object) and background (context) regions of images respectively. Consider- ing human recognition in the same situations, net- works trained on the pure background without ob- jects achieves highly reasonable recognition performance that beats humans by a large margin if only given context. However, humans still outperform networks with pure object available, which indicates networks and human beings have different mechanisms in understanding an image. Furthermore, we straightforwardly combine multiple trained networks to explore different visual cues learned by different networks. Experiments show that useful visual hints can be explicitly learned separately and then combined to achieve higher performance, which verifies the advantages of the proposed framework.
Bag Reference Vector for Multi-instance Learning
Dec 03, 2015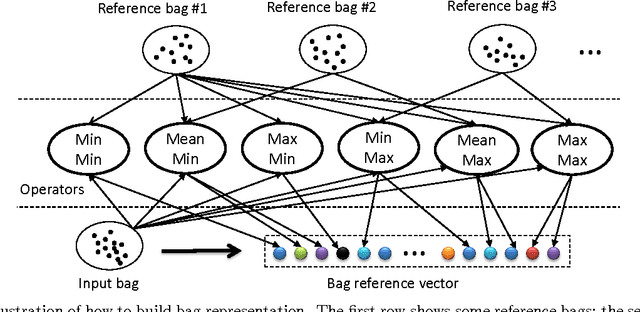
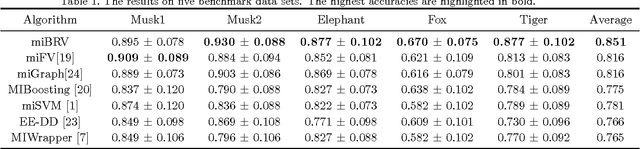
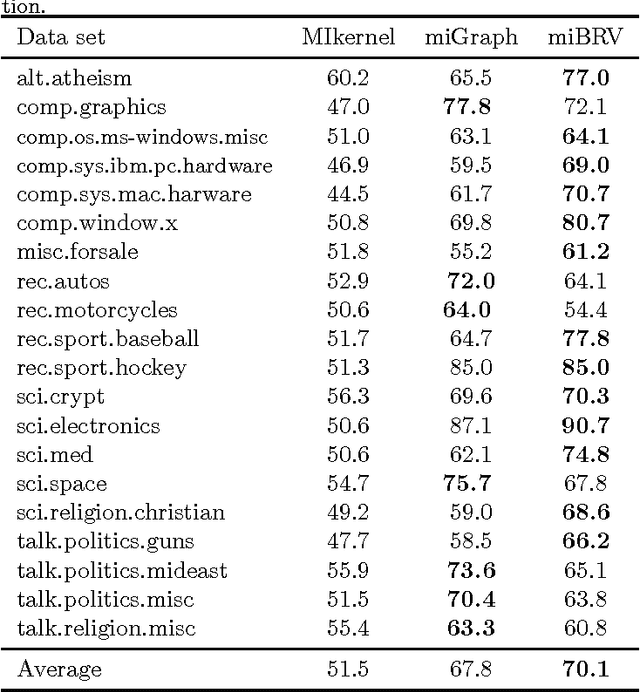
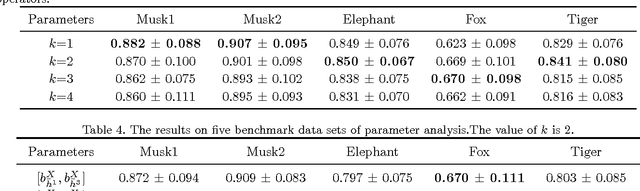
Multi-instance learning (MIL) has a wide range of applications due to its distinctive characteristics. Although many state-of-the-art algorithms have achieved decent performances, a plurality of existing methods solve the problem only in instance level rather than excavating relations among bags. In this paper, we propose an efficient algorithm to describe each bag by a corresponding feature vector via comparing it with other bags. In other words, the crucial information of a bag is extracted from the similarity between that bag and other reference bags. In addition, we apply extensions of Hausdorff distance to representing the similarity, to a certain extent, overcoming the key challenge of MIL problem, the ambiguity of instances' labels in positive bags. Experimental results on benchmarks and text categorization tasks show that the proposed method outperforms the previous state-of-the-art by a large margin.
Relaxed Multiple-Instance SVM with Application to Object Discovery
Oct 05, 2015

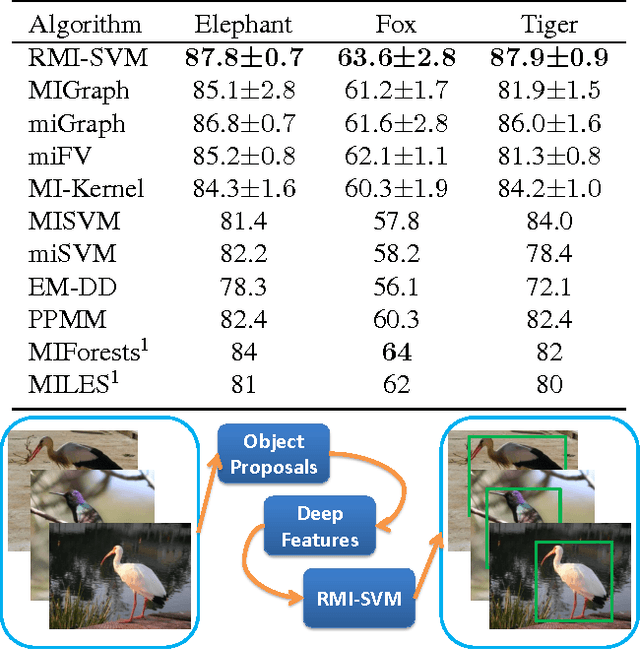
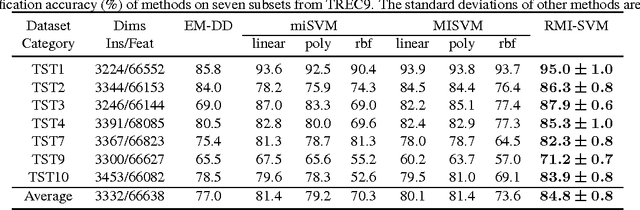
Multiple-instance learning (MIL) has served as an important tool for a wide range of vision applications, for instance, image classification, object detection, and visual tracking. In this paper, we propose a novel method to solve the classical MIL problem, named relaxed multiple-instance SVM (RMI-SVM). We treat the positiveness of instance as a continuous variable, use Noisy-OR model to enforce the MIL constraints, and jointly optimize the bag label and instance label in a unified framework. The optimization problem can be efficiently solved using stochastic gradient decent. The extensive experiments demonstrate that RMI-SVM consistently achieves superior performance on various benchmarks for MIL. Moreover, we simply applied RMI-SVM to a challenging vision task, common object discovery. The state-of-the-art results of object discovery on Pascal VOC datasets further confirm the advantages of the proposed method.
Deep Learning Representation using Autoencoder for 3D Shape Retrieval
Sep 25, 2014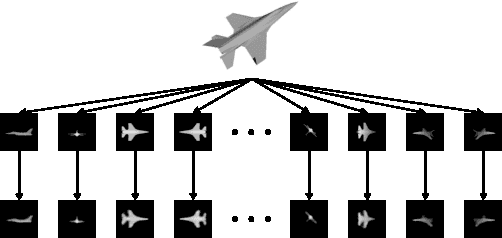
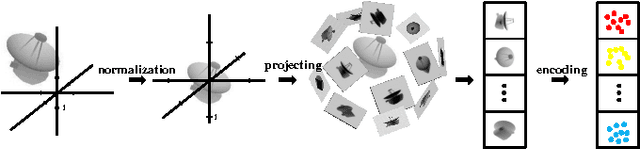
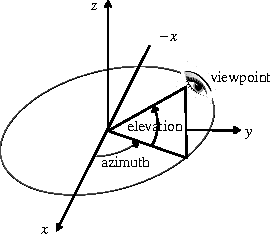
We study the problem of how to build a deep learning representation for 3D shape. Deep learning has shown to be very effective in variety of visual applications, such as image classification and object detection. However, it has not been successfully applied to 3D shape recognition. This is because 3D shape has complex structure in 3D space and there are limited number of 3D shapes for feature learning. To address these problems, we project 3D shapes into 2D space and use autoencoder for feature learning on the 2D images. High accuracy 3D shape retrieval performance is obtained by aggregating the features learned on 2D images. In addition, we show the proposed deep learning feature is complementary to conventional local image descriptors. By combing the global deep learning representation and the local descriptor representation, our method can obtain the state-of-the-art performance on 3D shape retrieval benchmarks.