 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble of Deep Convolutional Neural Networks for Automatic Pavement Crack Detection and Measurement
Feb 08, 2020
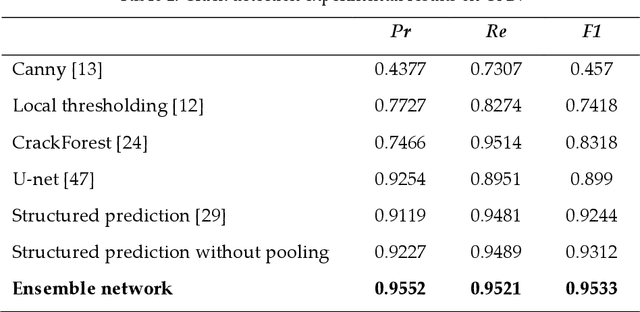
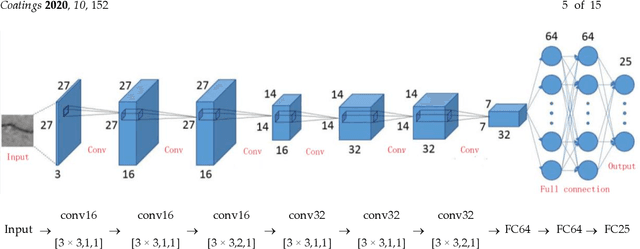
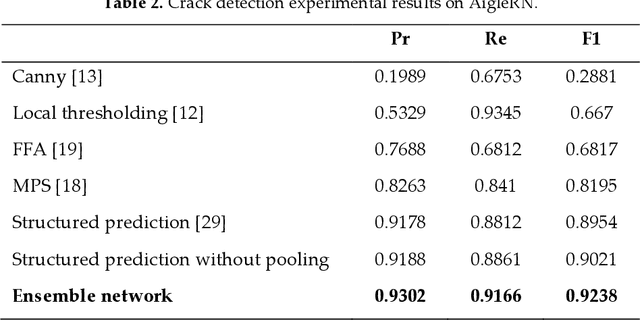
Automated pavement crack detection and measurement are important road issues. Agencies have to guarantee the improvement of road safety. Conventional crack detection and measurement algorithms can be extremely time-consuming and low efficiency. Therefore, recently, innovative algorithms have received increased attention from researchers. In this paper, we propose an ensemble of convolutional neural networks (without a pooling layer) based on probability fusion for automated pavement crack detection and measurement. Specifically, an ensemble of convolutional neural networks was employed to identify the structure of small cracks with raw images. Secondly, outputs of the individual convolutional neural network model for the ensemble were averaged to produce the final crack probability value of each pixel, which can obtain a predicted probability map. Finally, the predicted morphological features of the cracks were measured by using the skeleton extraction algorithm. To validate the proposed method, some experiments were performed on two public crack databases (CFD and AigleRN) and the results of the different state-of-the-art methods were compared. The experimental results show that the proposed method outperforms the other methods. For crack measurement, the crack length and width can be measure based on different crack types (complex, common, thin, and intersecting cracks.). The results show that the proposed algorithm can be effectively applied for crack measurement.
ENAS U-Net: Evolutionary Neural Architecture Search for Retinal Vessel Segmentation
Jan 18, 2020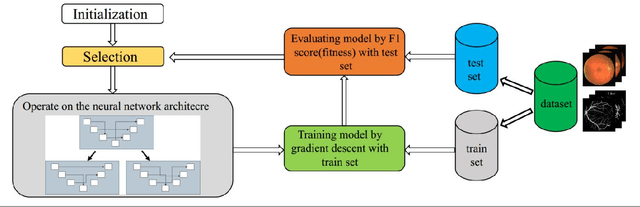

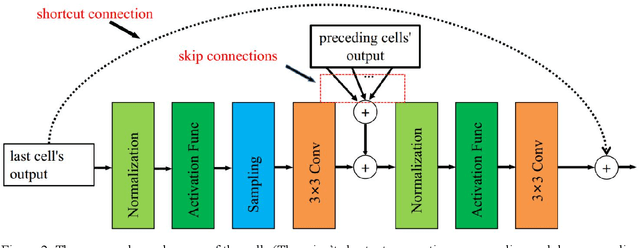

The accurate retina vessel segmentation (RVS) is of great significance to assist doctors in the diagnosis of ophthalmology diseases and other systemic diseases, and manually designing a valid neural network architecture for retinal vessel segmentation requires high expertise and a large workload. In order to further improve the performance of vessel segmentation and reduce the workload of manually designing neural network. We propose a specific search space based on encoder-decoder framework and apply neural architecture search (NAS) to retinal vessel segmentation. The search space is a macro-architecture search that involves some operations and adjustments to the entire network topology. For the architecture optimization, we adopt the modified evolutionary strategy which can evolve with limited computing resource to evolve the architectures. During the evolution, we select the elite architectures for the next generation evolution based on their performances. After the evolution, the searched model is evaluated on three mainstream datasets, namely DRIVE, STARE and CHASE_DB1. The searched model achieves top performance on all three datasets with fewer parameters (about 2.3M). Moreover, the results of cross-training between above three datasets show that the searched model is with considerable scalability, which indicates that the searched model is with potential for clinical disease diagnosis.
An Automatic Design Framework of Swarm Pattern Formation based on Multi-objective Genetic Programming
Nov 01, 2019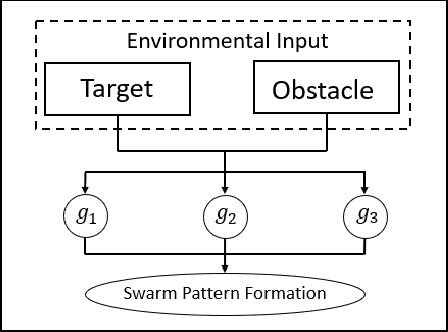
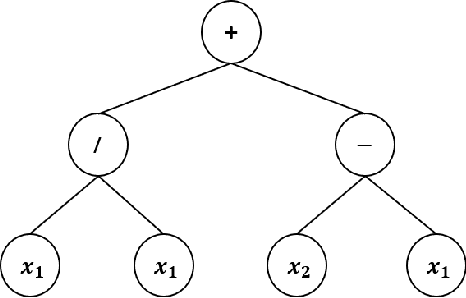
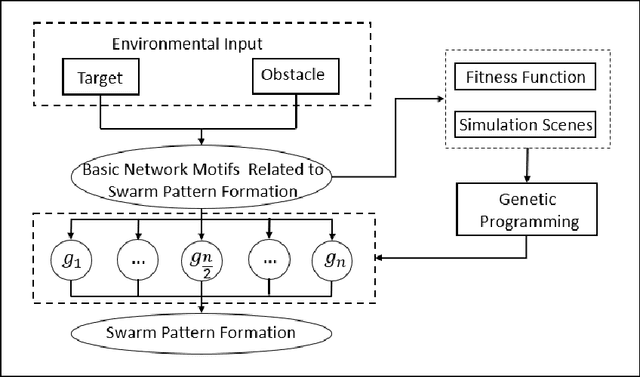
Most existing swarm pattern formation methods depend on a predefined gene regulatory network (GRN) structure that requires designers' priori knowledge, which is difficult to adapt to complex and changeable environments. To dynamically adapt to the complex and changeable environments, we propose an automatic design framework of swarm pattern formation based on multi-objective genetic programming. The proposed framework does not need to define the structure of the GRN-based model in advance, and it applies some basic network motifs to automatically structure the GRN-based model. In addition, a multi-objective genetic programming (MOGP) combines with NSGA-II, namely MOGP-NSGA-II, to balance the complexity and accuracy of the GRN-based model. In evolutionary process, an MOGP-NSGA-II and differential evolution (DE) are applied to optimize the structures and parameters of the GRN-based model in parallel. Simulation results demonstrate that the proposed framework can effectively evolve some novel GRN-based models, and these GRN-based models not only have a simpler structure and a better performance, but also are robust to the complex and changeable environments.
Accurate Retinal Vessel Segmentation via Octave Convolution Neural Network
Aug 11, 2019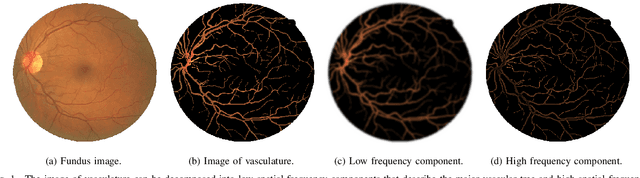
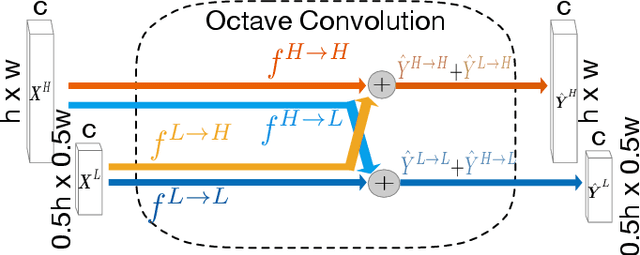
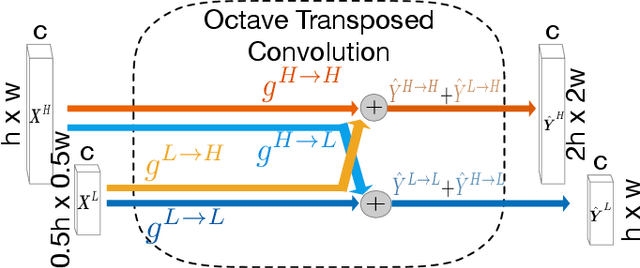
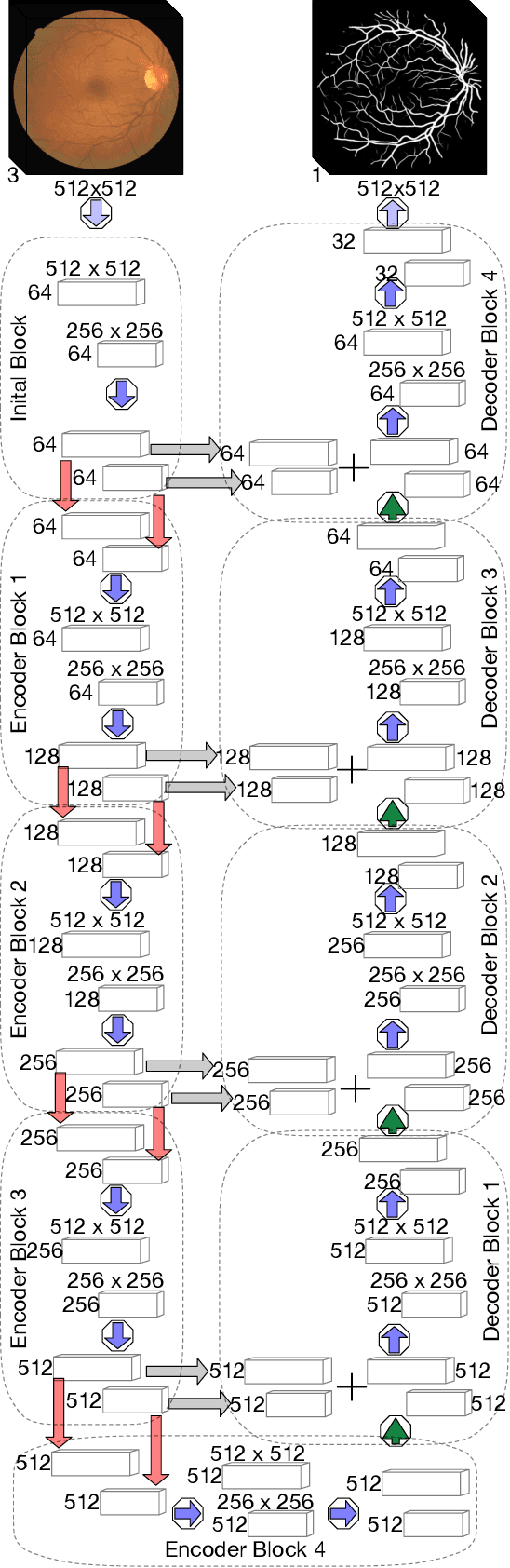
Retinal vessel segmentation is a crucial step in diagnosing and screening various diseases, including diabetes, ophthalmologic diseases, and cardiovascular diseases. In this paper, we propose an effective and efficient method for vessel segmentation in color fundus images using encoder-decoder based octave convolution network. Compared with other convolution networks utilizing vanilla convolution for feature extraction, the proposed method adopts octave convolution for learning multiple-spatial-frequency features, thus can better capture retinal vasculatures with varying sizes and shapes. It is demonstrated that the feature maps of low-frequency kernels respond mainly to the major vascular tree, whereas the high-frequency feature maps can better capture the fine details of thin vessels. To provide the network the capability of learning how to decode multifrequency features, we extend octave convolution and propose a new operation named octave transposed convolution. A novel architecture of convolutional neural network is proposed based on the encoder-decoder architecture of UNet, which can generate high resolution vessel segmentation in one single forward feeding. The proposed method is evaluated on four publicly available datasets, including DRIVE, STARE, CHASE_DB1, and HRF. Extensive experimental results demonstrate that the proposed approach achieves better or comparable performance to the state-of-the-art methods with fast processing speed.
Automated Steel Bar Counting and Center Localization with Convolutional Neural Networks
Jun 03, 2019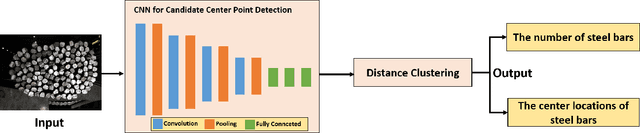
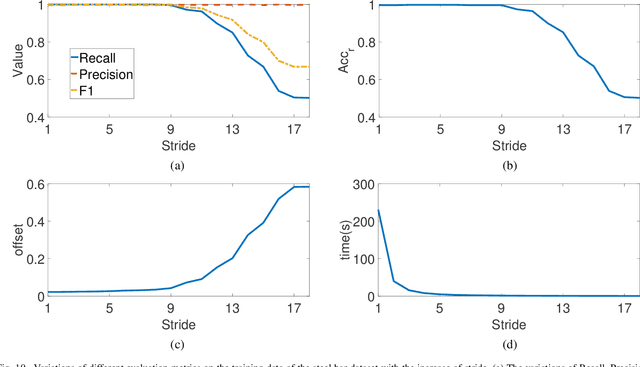
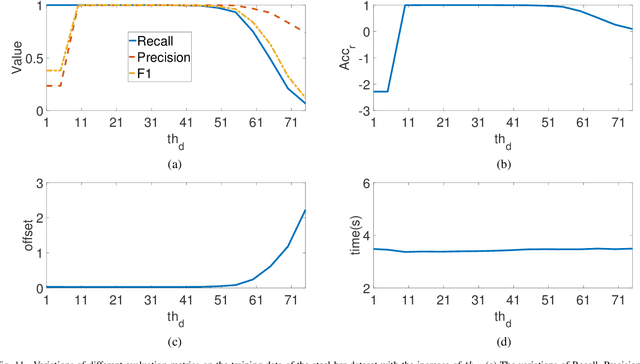

Automated steel bar counting and center localization plays an important role in the factory automation of steel bars. Traditional methods only focus on steel bar counting and their performances are often limited by complex industrial environments. Convolutional neural network (CNN), which has great capability to deal with complex tasks in challenging environments, is applied in this work. A framework called CNN-DC is proposed to achieve automated steel bar counting and center localization simultaneously. The proposed framework CNN-DC first detects the candidate center points with a deep CNN. Then an effective clustering algorithm named as Distance Clustering(DC) is proposed to cluster the candidate center points and locate the true centers of steel bars. The proposed CNN-DC can achieve 99.26% accuracy for steel bar counting and 4.1% center offset for center localization on the established steel bar dataset, which demonstrates that the proposed CNN-DC can perform well on automated steel bar counting and center localization. Code is made publicly available at: https://github.com/BenzhangQiu/Steel-bar-Detection.
Push and Pull Search Embedded in an M2M Framework for Solving Constrained Multi-objective Optimization Problems
Jun 02, 2019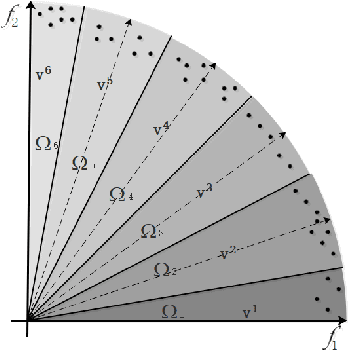
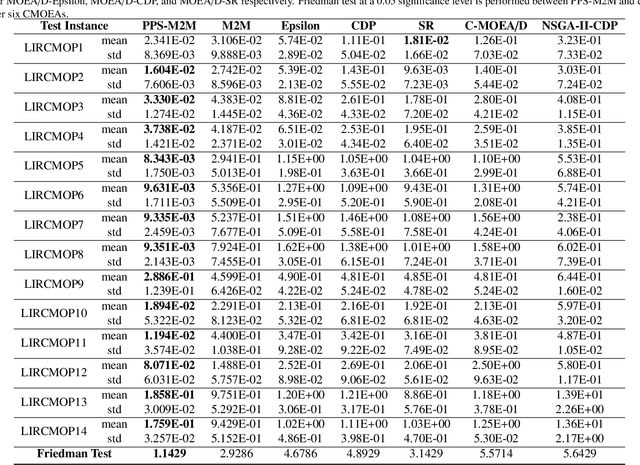

In dealing with constrained multi-objective optimization problems (CMOPs), a key issue of multi-objective evolutionary algorithms (MOEAs) is to balance the convergence and diversity of working populations.
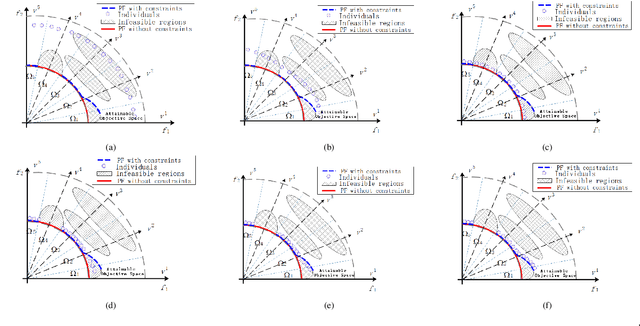
Embedding Push and Pull Search in the Framework of Differential Evolution for Solving Constrained Single-objective Optimization Problems
Dec 16, 2018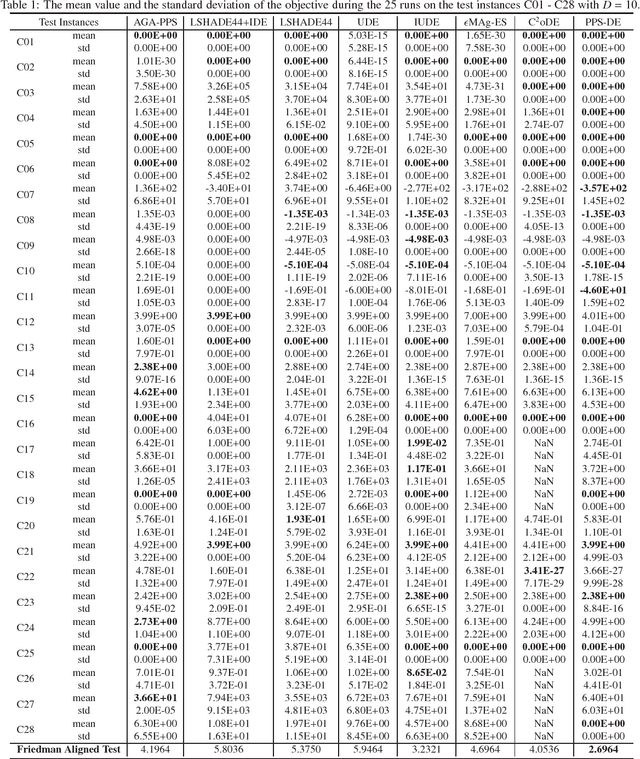
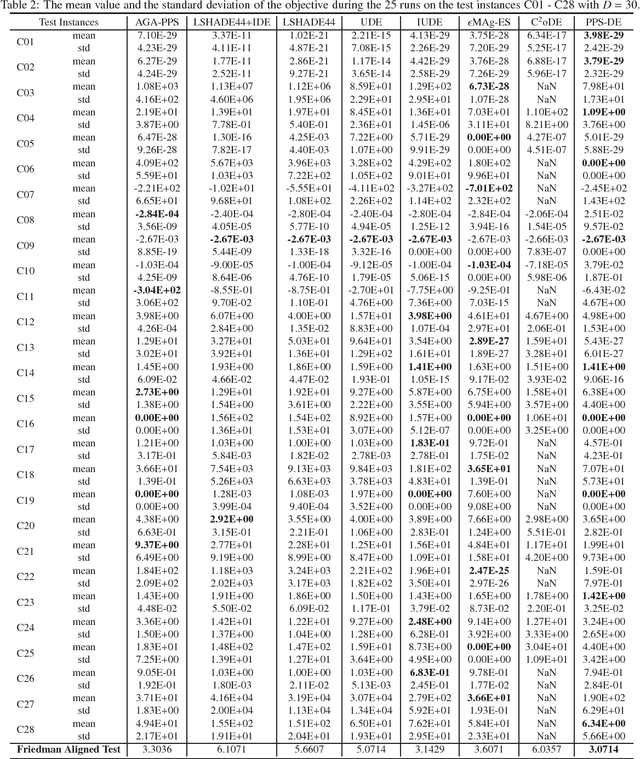
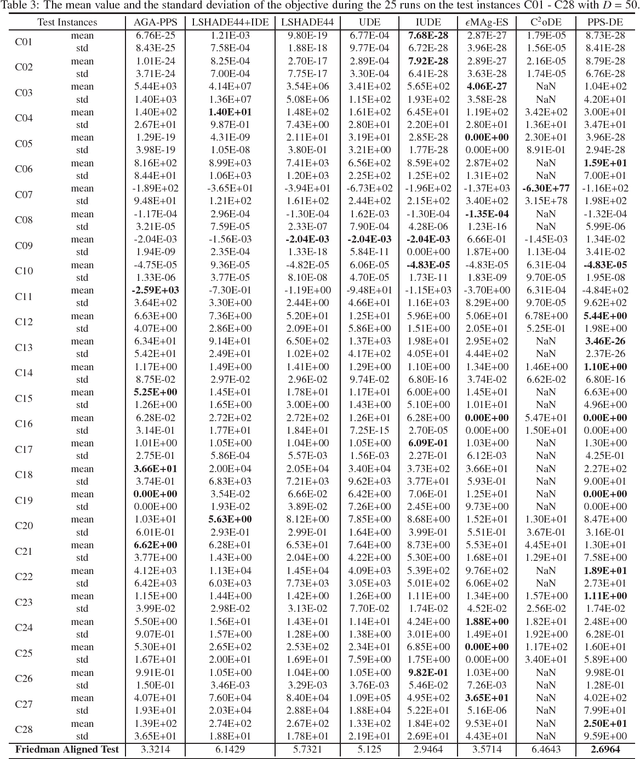
This paper proposes a push and pull search method in the framework of differential evolution (PPS-DE) to solve constrained single-objective optimization problems (CSOPs). More specifically, two sub-populations, including the top and bottom sub-populations, are collaborated with each other to search global optimal solutions efficiently. The top sub-population adopts the pull and pull search (PPS) mechanism to deal with constraints, while the bottom sub-population use the superiority of feasible solutions (SF) technique to deal with constraints. In the top sub-population, the search process is divided into two different stages --- push and pull stages.An adaptive DE variant with three trial vector generation strategies is employed in the proposed PPS-DE. In the top sub-population, all the three trial vector generation strategies are used to generate offsprings, just like in CoDE. In the bottom sub-population, a strategy adaptation, in which the trial vector generation strategies are periodically self-adapted by learning from their experiences in generating promising solutions in the top sub-population, is used to choose a suitable trial vector generation strategy to generate one offspring. Furthermore, a parameter adaptation strategy from LSHADE44 is employed in both sup-populations to generate scale factor $F$ and crossover rate $CR$ for each trial vector generation strategy. Twenty-eight CSOPs with 10-, 30-, and 50-dimensional decision variables provided in the CEC2018 competition on real parameter single objective optimization are optimized by the proposed PPS-DE. The experimental results demonstrate that the proposed PPS-DE has the best performance compared with the other seven state-of-the-art algorithms, including AGA-PPS, LSHADE44, LSHADE44+IDE, UDE, IUDE, $\epsilon$MAg-ES and C$^2$oDE.
Automated Strabismus Detection based on Deep neural networks for Telemedicine Applications
Sep 30, 2018
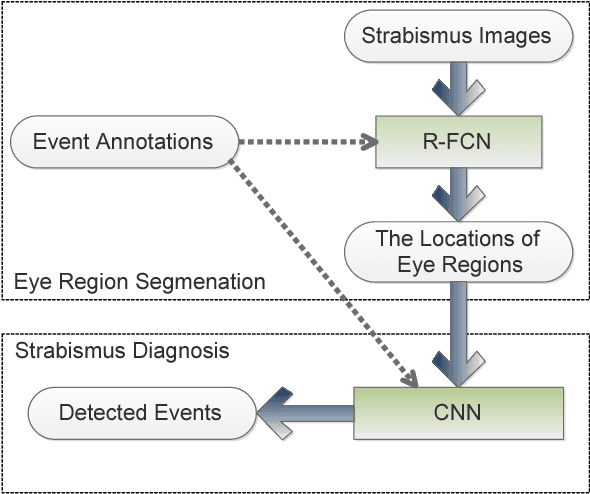
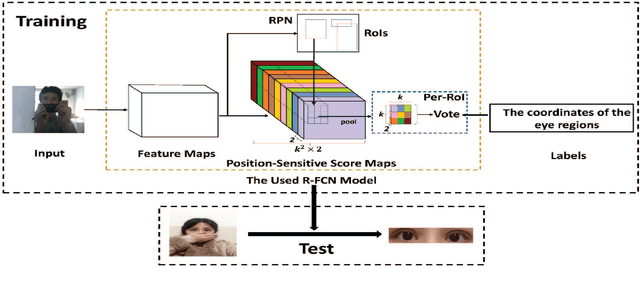

Strabismus is one of the most influential ophthalmologic diseases in humans life. Timely detection of strabismus contributes to its prognosis and treatment. Telemedicine, which has great potential to alleviate the growing demand of the diagnosis of ophthalmologic diseases, is an effective method to achieve timely strabismus detection. In addition, deep neural networks are beneficial to achieve fully automated strabismus detection. In this paper, a tele strabismus dataset is founded by the ophthalmologists. Then a new algorithm based on deep neural networks is proposed to achieve automated strabismus detection on the founded tele strabismus dataset. The proposed algorithm consists of two stages. In the first stage, R-FCN is applied to perform eye region segmentation. In the second stage, a deep convolutional neural networks is built and trained in order to classify the segmented eye regions as strabismus or normal. The experimental results on the founded tele strabismus dataset shows that the proposed method can have a good performance on automated strabismus detection for telemedicine application. Code is made publicly available at: https://github.com/jieWeiLu/Strabismus-Detection-for-Telemedicine-Application
MOEA/D with Angle-based Constrained Dominance Principle for Constrained Multi-objective Optimization Problems
Feb 10, 2018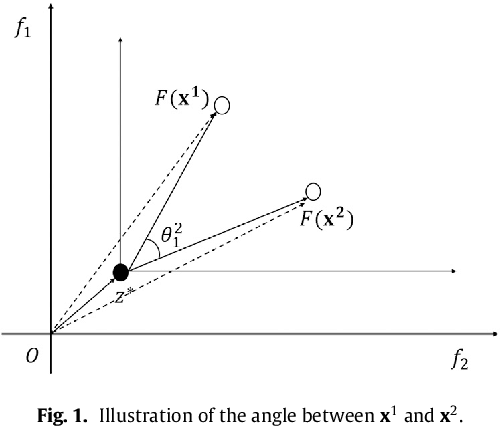
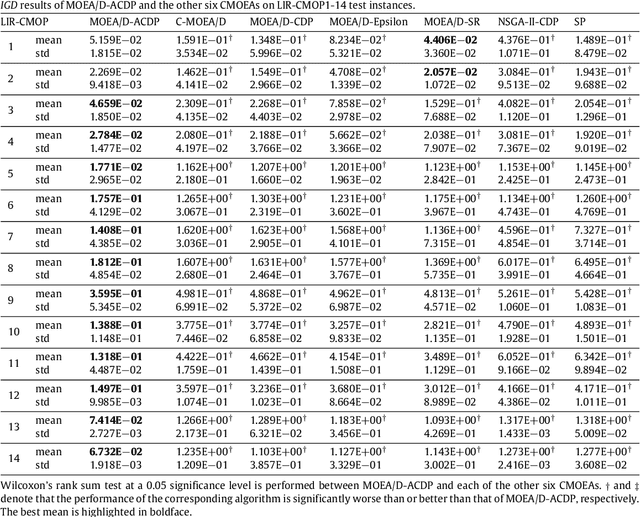
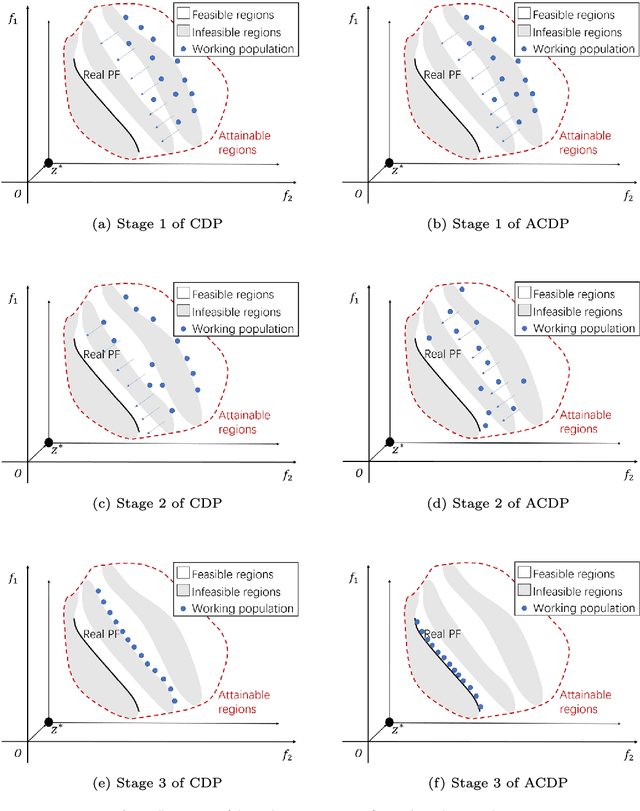
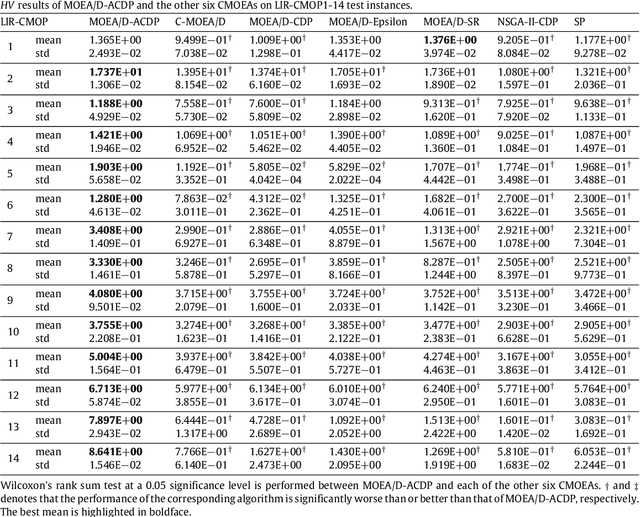
This paper proposes a novel constraint-handling mechanism named angle-based constrained dominance principle (ACDP) embedded in a decomposition-based multi-objective evolutionary algorithm (MOEA/D) to solve constrained multi-objective optimization problems (CMOPs). To maintain the diversity of the working population, ACDP utilizes the information of the angle of solutions to adjust the dominance relation of solutions during the evolutionary process. This paper uses 14 benchmark instances to evaluate the performance of the MOEA/D with ACDP (MOEA/D-ACDP). Additionally, an engineering optimization problem (which is I-beam optimization problem) is optimized. The proposed MOEA/D-ACDP, and four other decomposition-based CMOEAs, including C-MOEA/D, MOEA/D-CDP, MOEA/D-Epsilon and MOEA/D-SR are tested by the above benchmarks and the engineering application. The experimental results manifest that MOEA/D-ACDP is significantly better than the other four CMOEAs on these test instances and the real-world case, which indicates that ACDP is more effective for solving CMOPs.
Object Detection and Sorting by Using a Global Texture-Shape 3D Feature Descriptor
Feb 04, 2018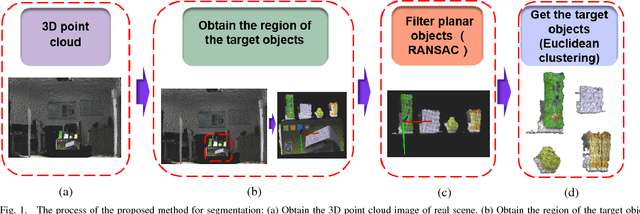



Object recognition and sorting plays a key role in robotic systems, especially for the autonomous robots to implement object sorting tasks in a warehouse. In this paper, we present a global texture-shape 3D feature descriptor which can be utilized in a sorting system, and this system can perform object sorting tasks well. Our proposed descriptor stems from the clustered viewpoint feature histogram (CVFH). As the CVFH feature descriptor relies on the geometrical information of the whole 3D object surface only, it can not perform well on the objects with similar geometrical information. Therefore, we extend the CVFH descriptor with texture information to generate a new global 3D feature descriptor. Then this proposed descriptor is tested for sorting 3D objects by using multi-class support vector machines (SVM). It is also evaluated by a public 3D image dataset and real scenes. The results of evaluation show that our proposed descriptor have a good performance for object recognition compared to the CVFH. Then we leverage this proposed descriptor in the proposed sorting system, showing that the proposed descriptor helps the sorting system implement the object detection, the object recognition and object grasping tasks well.