 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Tuning
May 10, 2023Fine-tuning visual models has been widely shown promising performance on many downstream visual tasks. With the surprising development of pre-trained visual foundation models, visual tuning jumped out of the standard modus operandi that fine-tunes the whole pre-trained model or just the fully connected layer. Instead, recent advances can achieve superior performance than full-tuning the whole pre-trained parameters by updating far fewer parameters, enabling edge devices and downstream applications to reuse the increasingly large foundation models deployed on the cloud. With the aim of helping researchers get the full picture and future directions of visual tuning, this survey characterizes a large and thoughtful selection of recent works, providing a systematic and comprehensive overview of existing work and models. Specifically, it provides a detailed background of visual tuning and categorizes recent visual tuning techniques into five groups: prompt tuning, adapter tuning, parameter tuning, and remapping tuning. Meanwhile, it offers some exciting research directions for prospective pre-training and various interactions in visual tuning.
LION: Implicit Vision Prompt Tuning
Mar 17, 2023Despite recent competitive performance across a range of vision tasks, vision Transformers still have an issue of heavy computational costs. Recently, vision prompt learning has provided an economic solution to this problem without fine-tuning the whole large-scale models. However, the efficiency of existing models are still far from satisfactory due to insertion of extensive prompts blocks and trick prompt designs. In this paper, we propose an efficient vision model named impLicit vIsion prOmpt tuNing (LION), which is motivated by deep implicit models with stable memory costs for various complex tasks. In particular, we merely insect two equilibrium implicit layers in two ends of the pre-trained main backbone with parameters in the backbone frozen. Moreover, we prune the parameters in these two layers according to lottery hypothesis. The performance obtained by our LION are promising on a wide range of datasets. In particular, our LION reduces up to 11.5% of training parameter numbers while obtaining higher performance compared with the state-of-the-art baseline VPT, especially under challenging scenes. Furthermore, we find that our proposed LION had a good generalization performance, making it an easy way to boost transfer learning in the future.
A Message Passing Perspective on Learning Dynamics of Contrastive Learning
Mar 08, 2023


In recent years, contrastive learning achieves impressive results on self-supervised visual representation learning, but there still lacks a rigorous understanding of its learning dynamics. In this paper, we show that if we cast a contrastive objective equivalently into the feature space, then its learning dynamics admits an interpretable form. Specifically, we show that its gradient descent corresponds to a specific message passing scheme on the corresponding augmentation graph. Based on this perspective, we theoretically characterize how contrastive learning gradually learns discriminative features with the alignment update and the uniformity update. Meanwhile, this perspective also establishes an intriguing connection between contrastive learning and Message Passing Graph Neural Networks (MP-GNNs). This connection not only provides a unified understanding of many techniques independently developed in each community, but also enables us to borrow techniques from MP-GNNs to design new contrastive learning variants, such as graph attention, graph rewiring, jumpy knowledge techniques, etc. We believe that our message passing perspective not only provides a new theoretical understanding of contrastive learning dynamics, but also bridges the two seemingly independent areas together, which could inspire more interleaving studies to benefit from each other. The code is available at https://github.com/PKU-ML/Message-Passing-Contrastive-Learning.
Towards Memory- and Time-Efficient Backpropagation for Training Spiking Neural Networks
Mar 07, 2023



Spiking Neural Networks (SNNs) are promising energy-efficient models for neuromorphic computing. For training the non-differentiable SNN models, the backpropagation through time (BPTT) with surrogate gradients (SG) method has achieved high performance. However, this method suffers from considerable memory cost and training time during training. In this paper, we propose the Spatial Learning Through Time (SLTT) method that can achieve high performance while greatly improving training efficiency compared with BPTT. First, we show that the backpropagation of SNNs through the temporal domain contributes just a little to the final calculated gradients. Thus, we propose to ignore the unimportant routes in the computational graph during backpropagation. The proposed method reduces the number of scalar multiplications and achieves a small memory occupation that is independent of the total time steps. Furthermore, we propose a variant of SLTT, called SLTT-K, that allows backpropagation only at K time steps, then the required number of scalar multiplications is further reduced and is independent of the total time steps. Experiments on both static and neuromorphic datasets demonstrate superior training efficiency and performance of our SLTT. In particular, our method achieves state-of-the-art accuracy on ImageNet, while the memory cost and training time are reduced by more than 70% and 50%, respectively, compared with BPTT.
Provable Particle-based Primal-Dual Algorithm for Mixed Nash Equilibrium
Mar 02, 2023We consider the general nonconvex nonconcave minimax problem over continuous variables. A major challenge for this problem is that a saddle point may not exist. In order to resolve this difficulty, we consider the related problem of finding a Mixed Nash Equilibrium, which is a randomized strategy represented by probability distributions over the continuous variables. We propose a Particle-based Primal-Dual Algorithm (PPDA) for a weakly entropy-regularized min-max optimization procedure over the probability distributions, which employs the stochastic movements of particles to represent the updates of random strategies for the mixed Nash Equilibrium. A rigorous convergence analysis of the proposed algorithm is provided. Compared to previous works that try to update particle weights without movements, PPDA is the first implementable particle-based algorithm with non-asymptotic quantitative convergence results, running time, and sample complexity guarantees. Our framework gives new insights into the design of particle-based algorithms for continuous min-max optimization in the general nonconvex nonconcave setting.
Neural Collapse Inspired Feature-Classifier Alignment for Few-Shot Class Incremental Learning
Feb 06, 2023



Few-shot class-incremental learning (FSCIL) has been a challenging problem as only a few training samples are accessible for each novel class in the new sessions. Finetuning the backbone or adjusting the classifier prototypes trained in the prior sessions would inevitably cause a misalignment between the feature and classifier of old classes, which explains the well-known catastrophic forgetting problem. In this paper, we deal with this misalignment dilemma in FSCIL inspired by the recently discovered phenomenon named neural collapse, which reveals that the last-layer features of the same class will collapse into a vertex, and the vertices of all classes are aligned with the classifier prototypes, which are formed as a simplex equiangular tight frame (ETF). It corresponds to an optimal geometric structure for classification due to the maximized Fisher Discriminant Ratio. We propose a neural collapse inspired framework for FSCIL. A group of classifier prototypes are pre-assigned as a simplex ETF for the whole label space, including the base session and all the incremental sessions. During training, the classifier prototypes are not learnable, and we adopt a novel loss function that drives the features into their corresponding prototypes. Theoretical analysis shows that our method holds the neural collapse optimality and does not break the feature-classifier alignment in an incremental fashion. Experiments on the miniImageNet, CUB-200, and CIFAR-100 datasets demonstrate that our proposed framework outperforms the state-of-the-art performances. Code address: https://github.com/NeuralCollapseApplications/FSCIL
SPIDE: A Purely Spike-based Method for Training Feedback Spiking Neural Networks
Feb 01, 2023



Spiking neural networks (SNNs) with event-based computation are promising brain-inspired models for energy-efficient applications on neuromorphic hardware. However, most supervised SNN training methods, such as conversion from artificial neural networks or direct training with surrogate gradients, require complex computation rather than spike-based operations of spiking neurons during training. In this paper, we study spike-based implicit differentiation on the equilibrium state (SPIDE) that extends the recently proposed training method, implicit differentiation on the equilibrium state (IDE), for supervised learning with purely spike-based computation, which demonstrates the potential for energy-efficient training of SNNs. Specifically, we introduce ternary spiking neuron couples and prove that implicit differentiation can be solved by spikes based on this design, so the whole training procedure, including both forward and backward passes, is made as event-driven spike computation, and weights are updated locally with two-stage average firing rates. Then we propose to modify the reset membrane potential to reduce the approximation error of spikes. With these key components, we can train SNNs with flexible structures in a small number of time steps and with firing sparsity during training, and the theoretical estimation of energy costs demonstrates the potential for high efficiency. Meanwhile, experiments show that even with these constraints, our trained models can still achieve competitive results on MNIST, CIFAR-10, CIFAR-100, and CIFAR10-DVS. Our code is available at https://github.com/pkuxmq/SPIDE-FSNN.
PanopticPartFormer++: A Unified and Decoupled View for Panoptic Part Segmentation
Jan 03, 2023



Panoptic Part Segmentation (PPS) unifies panoptic segmentation and part segmentation into one task. Previous works utilize separated approaches to handle thing, stuff, and part predictions without shared computation and task association. We aim to unify these tasks at the architectural level, designing the first end-to-end unified framework named Panoptic-PartFormer. Moreover, we find the previous metric PartPQ biases to PQ. To handle both issues, we make the following contributions: Firstly, we design a meta-architecture that decouples part feature and things/stuff feature, respectively. We model things, stuff, and parts as object queries and directly learn to optimize all three forms of prediction as a unified mask prediction and classification problem. We term our model as Panoptic-PartFormer. Secondly, we propose a new metric Part-Whole Quality (PWQ) to better measure such task from both pixel-region and part-whole perspectives. It can also decouple the error for part segmentation and panoptic segmentation. Thirdly, inspired by Mask2Former, based on our meta-architecture, we propose Panoptic-PartFormer++ and design a new part-whole cross attention scheme to further boost part segmentation qualities. We design a new part-whole interaction method using masked cross attention. Finally, the extensive ablation studies and analysis demonstrate the effectiveness of both Panoptic-PartFormer and Panoptic-PartFormer++. Compared with previous Panoptic-PartFormer, our Panoptic-PartFormer++ achieves 2% PartPQ and 3% PWQ improvements on the Cityscapes PPS dataset and 5% PartPQ on the Pascal Context PPS dataset. On both datasets, Panoptic-PartFormer++ achieves new state-of-the-art results with a significant cost drop of 70% on GFlops and 50% on parameters. Our models can serve as a strong baseline and aid future research in PPS. Code will be available.
Towards Theoretically Inspired Neural Initialization Optimization
Oct 12, 2022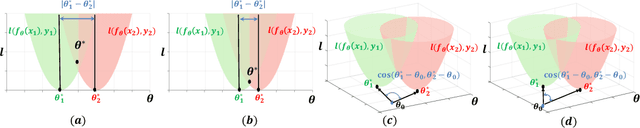
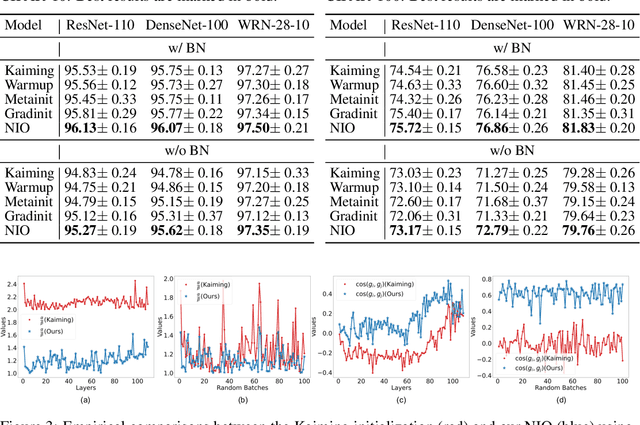


Automated machine learning has been widely explored to reduce human efforts in designing neural architectures and looking for proper hyperparameters. In the domain of neural initialization, however, similar automated techniques have rarely been studied. Most existing initialization methods are handcrafted and highly dependent on specific architectures. In this paper, we propose a differentiable quantity, named GradCosine, with theoretical insights to evaluate the initial state of a neural network. Specifically, GradCosine is the cosine similarity of sample-wise gradients with respect to the initialized parameters. By analyzing the sample-wise optimization landscape, we show that both the training and test performance of a network can be improved by maximizing GradCosine under gradient norm constraint. Based on this observation, we further propose the neural initialization optimization (NIO) algorithm. Generalized from the sample-wise analysis into the real batch setting, NIO is able to automatically look for a better initialization with negligible cost compared with the training time. With NIO, we improve the classification performance of a variety of neural architectures on CIFAR-10, CIFAR-100, and ImageNet. Moreover, we find that our method can even help to train large vision Transformer architecture without warmup.
Invertible Rescaling Network and Its Extensions
Oct 09, 2022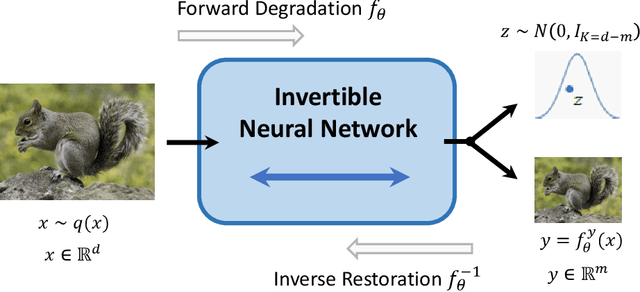
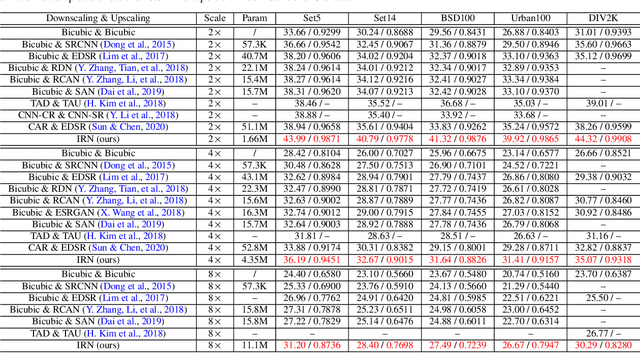
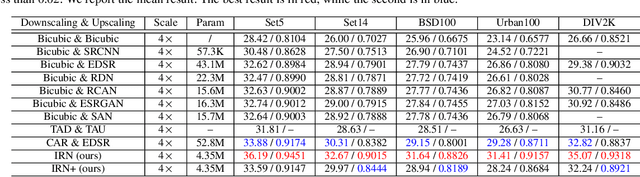
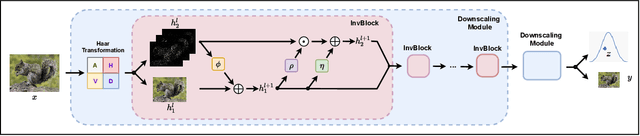
Image rescaling is a commonly used bidirectional operation, which first downscales high-resolution images to fit various display screens or to be storage- and bandwidth-friendly, and afterward upscales the corresponding low-resolution images to recover the original resolution or the details in the zoom-in images. However, the non-injective downscaling mapping discards high-frequency contents, leading to the ill-posed problem for the inverse restoration task. This can be abstracted as a general image degradation-restoration problem with information loss. In this work, we propose a novel invertible framework to handle this general problem, which models the bidirectional degradation and restoration from a new perspective, i.e. invertible bijective transformation. The invertibility enables the framework to model the information loss of pre-degradation in the form of distribution, which could mitigate the ill-posed problem during post-restoration. To be specific, we develop invertible models to generate valid degraded images and meanwhile transform the distribution of lost contents to the fixed distribution of a latent variable during the forward degradation. Then restoration is made tractable by applying the inverse transformation on the generated degraded image together with a randomly-drawn latent variable. We start from image rescaling and instantiate the model as Invertible Rescaling Network (IRN), which can be easily extended to the similar decolorization-colorization task. We further propose to combine the invertible framework with existing degradation methods such as image compression for wider applications. Experimental results demonstrate the significant improvement of our model over existing methods in terms of both quantitative and qualitative evaluations of upscaling and colorizing reconstruction from downscaled and decolorized images, and rate-distortion of image compression.