 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Large Language Models Possess Sensitive to Sentiment?
Sep 04, 2024Large Language Models (LLMs) have recently displayed their extraordinary capabilities in language understanding. However, how to comprehensively assess the sentiment capabilities of LLMs continues to be a challenge. This paper investigates the ability of LLMs to detect and react to sentiment in text modal. As the integration of LLMs into diverse applications is on the rise, it becomes highly critical to comprehend their sensitivity to emotional tone, as it can influence the user experience and the efficacy of sentiment-driven tasks. We conduct a series of experiments to evaluate the performance of several prominent LLMs in identifying and responding appropriately to sentiments like positive, negative, and neutral emotions. The models' outputs are analyzed across various sentiment benchmarks, and their responses are compared with human evaluations. Our discoveries indicate that although LLMs show a basic sensitivity to sentiment, there are substantial variations in their accuracy and consistency, emphasizing the requirement for further enhancements in their training processes to better capture subtle emotional cues. Take an example in our findings, in some cases, the models might wrongly classify a strongly positive sentiment as neutral, or fail to recognize sarcasm or irony in the text. Such misclassifications highlight the complexity of sentiment analysis and the areas where the models need to be refined. Another aspect is that different LLMs might perform differently on the same set of data, depending on their architecture and training datasets. This variance calls for a more in-depth study of the factors that contribute to the performance differences and how they can be optimized.
How Privacy-Savvy Are Large Language Models? A Case Study on Compliance and Privacy Technical Review
Sep 04, 2024



The recent advances in large language models (LLMs) have significantly expanded their applications across various fields such as language generation, summarization, and complex question answering. However, their application to privacy compliance and technical privacy reviews remains under-explored, raising critical concerns about their ability to adhere to global privacy standards and protect sensitive user data. This paper seeks to address this gap by providing a comprehensive case study evaluating LLMs' performance in privacy-related tasks such as privacy information extraction (PIE), legal and regulatory key point detection (KPD), and question answering (QA) with respect to privacy policies and data protection regulations. We introduce a Privacy Technical Review (PTR) framework, highlighting its role in mitigating privacy risks during the software development life-cycle. Through an empirical assessment, we investigate the capacity of several prominent LLMs, including BERT, GPT-3.5, GPT-4, and custom models, in executing privacy compliance checks and technical privacy reviews. Our experiments benchmark the models across multiple dimensions, focusing on their precision, recall, and F1-scores in extracting privacy-sensitive information and detecting key regulatory compliance points. While LLMs show promise in automating privacy reviews and identifying regulatory discrepancies, significant gaps persist in their ability to fully comply with evolving legal standards. We provide actionable recommendations for enhancing LLMs' capabilities in privacy compliance, emphasizing the need for robust model improvements and better integration with legal and regulatory requirements. This study underscores the growing importance of developing privacy-aware LLMs that can both support businesses in compliance efforts and safeguard user privacy rights.
Observation of Aerosolization-induced Morphological Changes in Viral Capsids
Jul 16, 2024



Single-stranded RNA viruses co-assemble their capsid with the genome and variations in capsid structures can have significant functional relevance. In particular, viruses need to respond to a dehydrating environment to prevent genomic degradation and remain active upon rehydration. Theoretical work has predicted low-energy buckling transitions in icosahedral capsids which could protect the virus from further dehydration. However, there has been no direct experimental evidence, nor molecular mechanism, for such behaviour. Here we observe this transition using X-ray single particle imaging of MS2 bacteriophages after aerosolization. Using a combination of machine learning tools, we classify hundreds of thousands of single particle diffraction patterns to learn the structural landscape of the capsid morphology as a function of time spent in the aerosol phase. We found a previously unreported compact conformation as well as intermediate structures which suggest an incoherent buckling transition which does not preserve icosahedral symmetry. Finally, we propose a mechanism of this buckling, where a single 19-residue loop is destabilised, leading to the large observed morphology change. Our results provide experimental evidence for a mechanism by which viral capsids protect themselves from dehydration. In the process, these findings also demonstrate the power of single particle X-ray imaging and machine learning methods in studying biomolecular structural dynamics.
Reconfigurable Robot Identification from Motion Data
Mar 15, 2024



Integrating Large Language Models (VLMs) and Vision-Language Models (VLMs) with robotic systems enables robots to process and understand complex natural language instructions and visual information. However, a fundamental challenge remains: for robots to fully capitalize on these advancements, they must have a deep understanding of their physical embodiment. The gap between AI models cognitive capabilities and the understanding of physical embodiment leads to the following question: Can a robot autonomously understand and adapt to its physical form and functionalities through interaction with its environment? This question underscores the transition towards developing self-modeling robots without reliance on external sensory or pre-programmed knowledge about their structure. Here, we propose a meta self modeling that can deduce robot morphology through proprioception (the internal sense of position and movement). Our study introduces a 12 DoF reconfigurable legged robot, accompanied by a diverse dataset of 200k unique configurations, to systematically investigate the relationship between robotic motion and robot morphology. Utilizing a deep neural network model comprising a robot signature encoder and a configuration decoder, we demonstrate the capability of our system to accurately predict robot configurations from proprioceptive signals. This research contributes to the field of robotic self-modeling, aiming to enhance understanding of their physical embodiment and adaptability in real world scenarios.
Unsupervised learning approaches to characterize heterogeneous samples using X-ray single particle imaging
Sep 13, 2021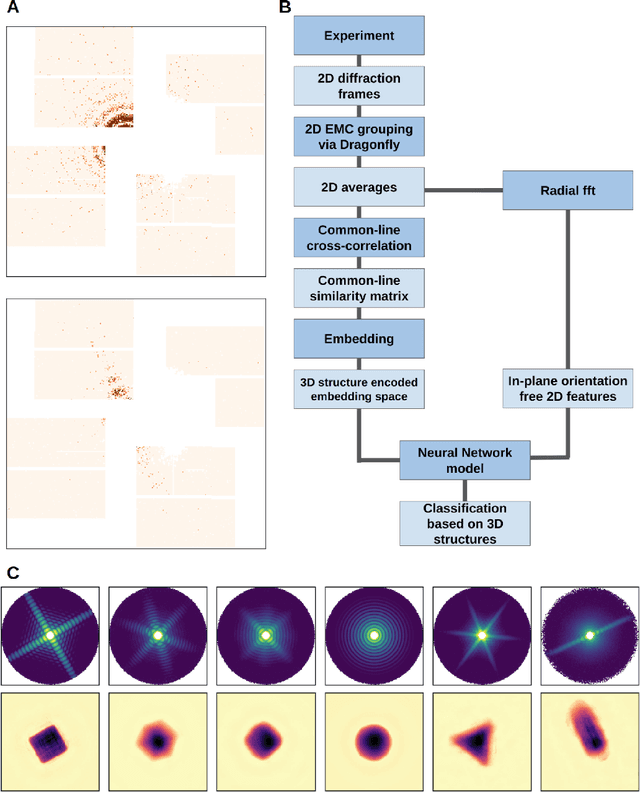
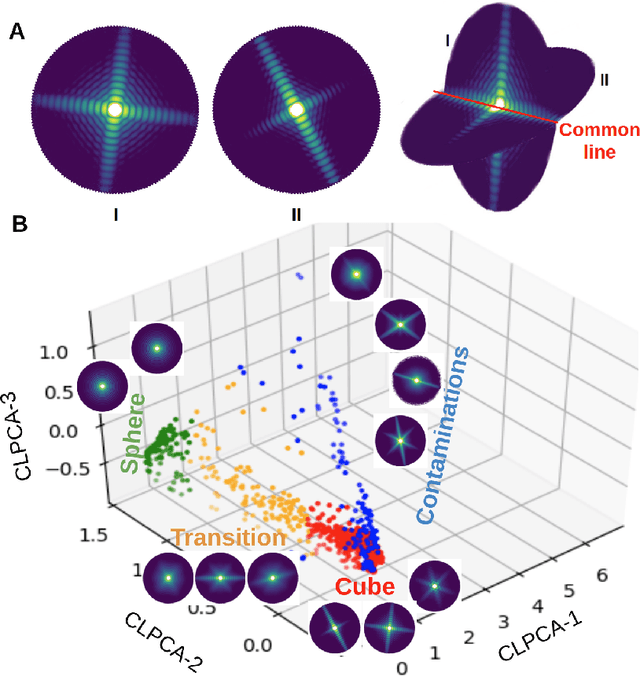
One of the outstanding analytical problems in X-ray single particle imaging (SPI) is the classification of structural heterogeneity, which is especially difficult given the low signal-to-noise ratios of individual patterns and that even identical objects can yield patterns that vary greatly when orientation is taken into consideration. We propose two methods which explicitly account for this orientation-induced variation and can robustly determine the structural landscape of a sample ensemble. The first, termed common-line principal component analysis (PCA) provides a rough classification which is essentially parameter-free and can be run automatically on any SPI dataset. The second method, utilizing variation auto-encoders (VAEs) can generate 3D structures of the objects at any point in the structural landscape. We implement both these methods in combination with the noise-tolerant expand-maximize-compress (EMC) algorithm and demonstrate its utility by applying it to an experimental dataset from gold nanoparticles with only a few thousand photons per pattern and recover both discrete structural classes as well as continuous deformations. These developments diverge from previous approaches of extracting reproducible subsets of patterns from a dataset and open up the possibility to move beyond studying homogeneous sample sets and study open questions on topics such as nanocrystal growth and dynamics as well as phase transitions which have not been externally triggered.
FreeLabel: A Publicly Available Annotation Tool based on Freehand Traces
Mar 11, 2019

Large-scale annotation of image segmentation datasets is often prohibitively expensive, as it usually requires a huge number of worker hours to obtain high-quality results. Abundant and reliable data has been, however, crucial for the advances on image understanding tasks achieved by deep learning models. In this paper, we introduce FreeLabel, an intuitive open-source web interface that allows users to obtain high-quality segmentation masks with just a few freehand scribbles, in a matter of seconds. The efficacy of FreeLabel is quantitatively demonstrated by experimental results on the PASCAL dataset as well as on a dataset from the agricultural domain. Designed to benefit the computer vision community, FreeLabel can be used for both crowdsourced or private annotation and has a modular structure that can be easily adapted for any image dataset.
* Accepted and presented at 2019 IEEE Winter Conference on Applications of Computer Vision (WACV). 10 pages