 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Linear Contextual Bandits with Graph-Structured Side Observations
Dec 28, 2020
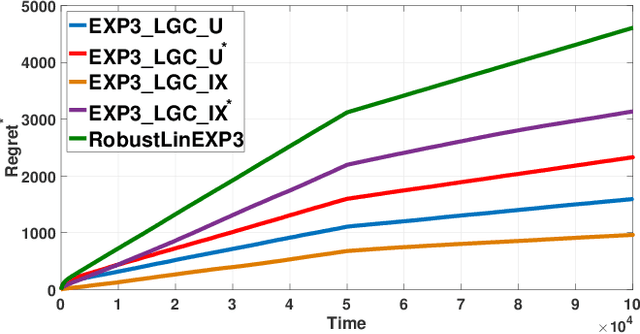
This paper studies the adversarial graphical contextual bandits, a variant of adversarial multi-armed bandits that leverage two categories of the most common side information: \emph{contexts} and \emph{side observations}. In this setting, a learning agent repeatedly chooses from a set of $K$ actions after being presented with a $d$-dimensional context vector. The agent not only incurs and observes the loss of the chosen action, but also observes the losses of its neighboring actions in the observation structures, which are encoded as a series of feedback graphs. This setting models a variety of applications in social networks, where both contexts and graph-structured side observations are available. Two efficient algorithms are developed based on \texttt{EXP3}. Under mild conditions, our analysis shows that for undirected feedback graphs the first algorithm, \texttt{EXP3-LGC-U}, achieves the regret of order $\mathcal{O}(\sqrt{(K+\alpha(G)d)T\log{K}})$ over the time horizon $T$, where $\alpha(G)$ is the average \emph{independence number} of the feedback graphs. A slightly weaker result is presented for the directed graph setting as well. The second algorithm, \texttt{EXP3-LGC-IX}, is developed for a special class of problems, for which the regret is reduced to $\mathcal{O}(\sqrt{\alpha(G)dT\log{K}\log(KT)})$ for both directed as well as undirected feedback graphs. Numerical tests corroborate the efficiency of proposed algorithms.
Enhancing Parameter-Free Frank Wolfe with an Extra Subproblem
Dec 09, 2020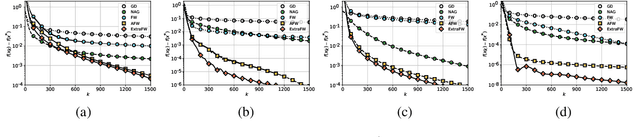

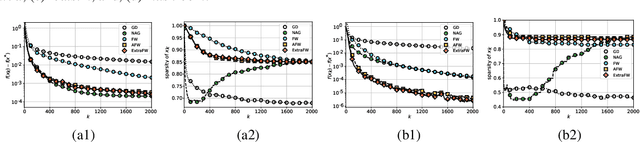
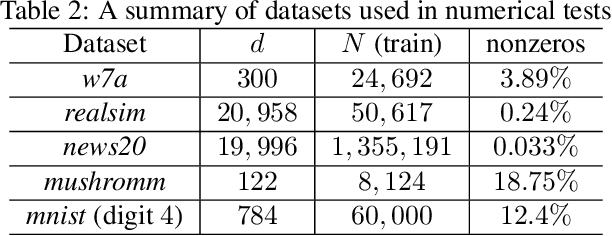
Aiming at convex optimization under structural constraints, this work introduces and analyzes a variant of the Frank Wolfe (FW) algorithm termed ExtraFW. The distinct feature of ExtraFW is the pair of gradients leveraged per iteration, thanks to which the decision variable is updated in a prediction-correction (PC) format. Relying on no problem dependent parameters in the step sizes, the convergence rate of ExtraFW for general convex problems is shown to be ${\cal O}(\frac{1}{k})$, which is optimal in the sense of matching the lower bound on the number of solved FW subproblems. However, the merit of ExtraFW is its faster rate ${\cal O}\big(\frac{1}{k^2} \big)$ on a class of machine learning problems. Compared with other parameter-free FW variants that have faster rates on the same problems, ExtraFW has improved rates and fine-grained analysis thanks to its PC update. Numerical tests on binary classification with different sparsity-promoting constraints demonstrate that the empirical performance of ExtraFW is significantly better than FW, and even faster than Nesterov's accelerated gradient on certain datasets. For matrix completion, ExtraFW enjoys smaller optimality gap, and lower rank than FW.
Deep Learning for Cardiologist-level Myocardial Infarction Detection in Electrocardiograms
Dec 16, 2019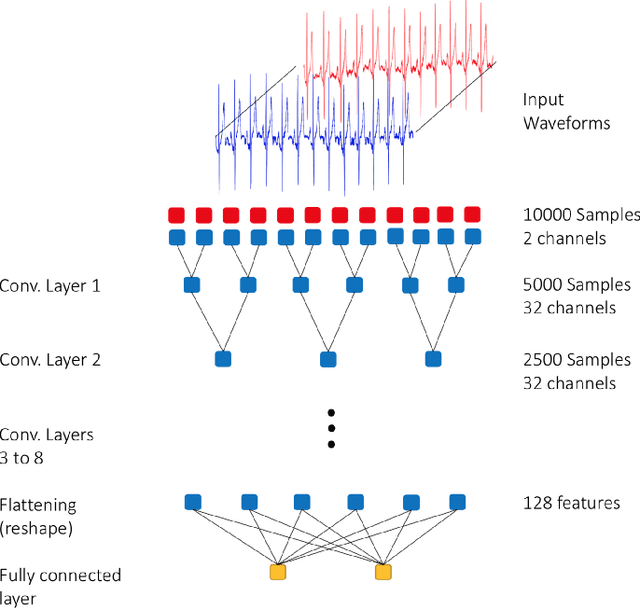
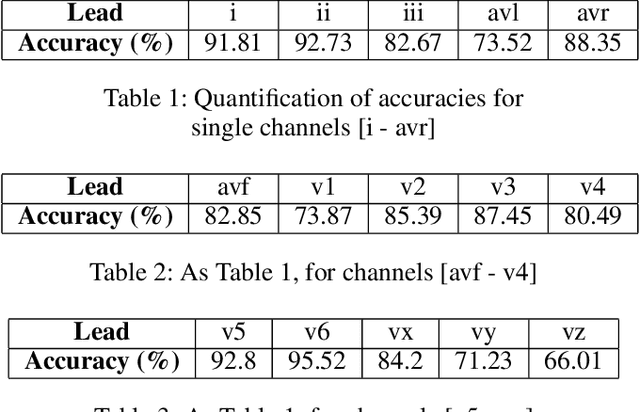
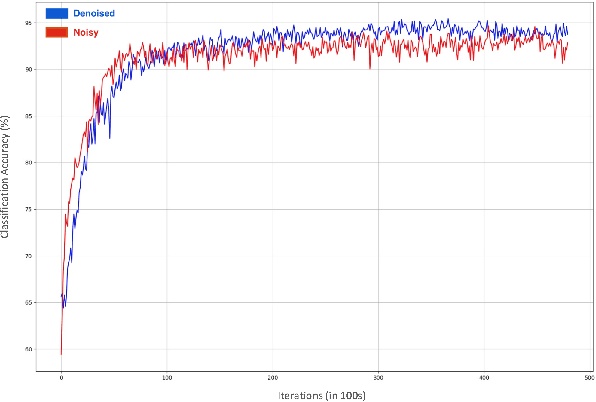
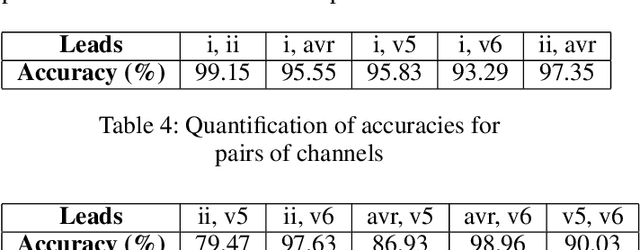
Heart disease is the leading cause of death worldwide. Amongst patients with cardiovascular diseases, myocardial infarction is the main cause of death. In order to provide adequate healthcare support to patients who may experience this clinical event, it is essential to gather supportive evidence in a timely manner to help secure a correct diagnosis. In this article, we study the feasibility of using deep learning to identify suggestive electrocardiographic (ECG) changes that may correctly classify heart conditions using the Physikalisch-Technische Bundesanstalt (PTB) database. As part of this study, we systematically quantify the contribution of each ECG lead to correctly tell apart a healthy from an unhealthy heart. For such a study we fine-tune the ConvNetQuake neural network model, which was originally designed to identify earthquakes. Our findings indicate that out of 15 ECG leads, data from the v6 and vz leads are critical to correctly identify myocardial infarction. Based on these findings, we modify ConvNetQuake to simultaneously take in raw ECG data from leads v6 and vz, achieving $99.43\%$ classification accuracy, which represents cardiologist-level performance level for myocardial infarction detection after feeding only 10 seconds of raw ECG data to our neural network model. This approach differs from others in the community in that the ECG data fed into the neural network model does not require any kind of manual feature extraction or pre-processing.
Enabling real-time multi-messenger astrophysics discoveries with deep learning
Nov 26, 2019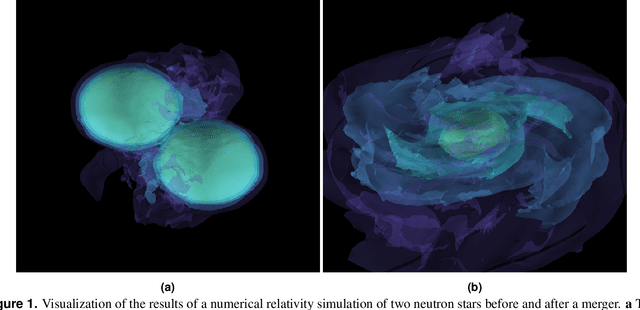
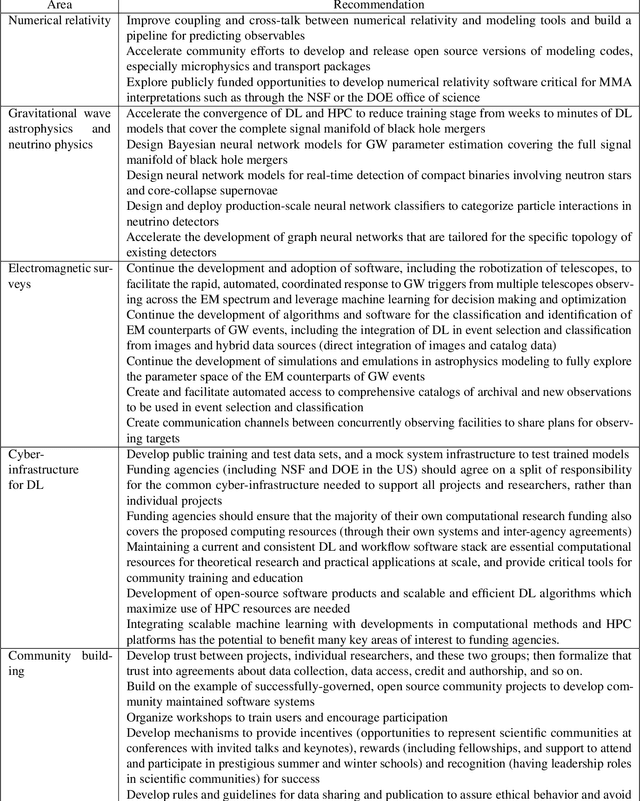
Multi-messenger astrophysics is a fast-growing, interdisciplinary field that combines data, which vary in volume and speed of data processing, from many different instruments that probe the Universe using different cosmic messengers: electromagnetic waves, cosmic rays, gravitational waves and neutrinos. In this Expert Recommendation, we review the key challenges of real-time observations of gravitational wave sources and their electromagnetic and astroparticle counterparts, and make a number of recommendations to maximize their potential for scientific discovery. These recommendations refer to the design of scalable and computationally efficient machine learning algorithms; the cyber-infrastructure to numerically simulate astrophysical sources, and to process and interpret multi-messenger astrophysics data; the management of gravitational wave detections to trigger real-time alerts for electromagnetic and astroparticle follow-ups; a vision to harness future developments of machine learning and cyber-infrastructure resources to cope with the big-data requirements; and the need to build a community of experts to realize the goals of multi-messenger astrophysics.
* Invited Expert Recommendation for Nature Reviews Physics. The art work produced by E. A. Huerta and Shawn Rosofsky for this article was used by Carl Conway to design the cover of the October 2019 issue of Nature Reviews Physics
Be Aware of Non-Stationarity: Nearly Optimal Algorithms for Piecewise-Stationary Cascading Bandits
Oct 07, 2019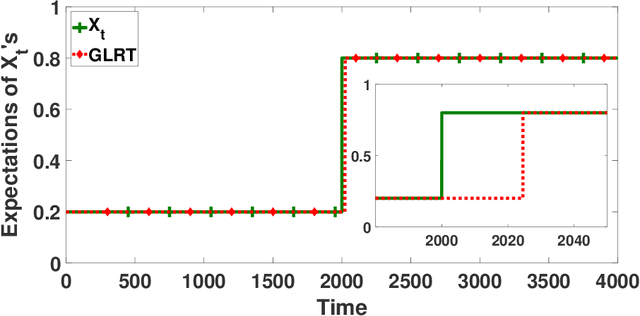
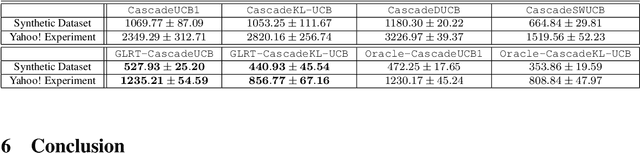
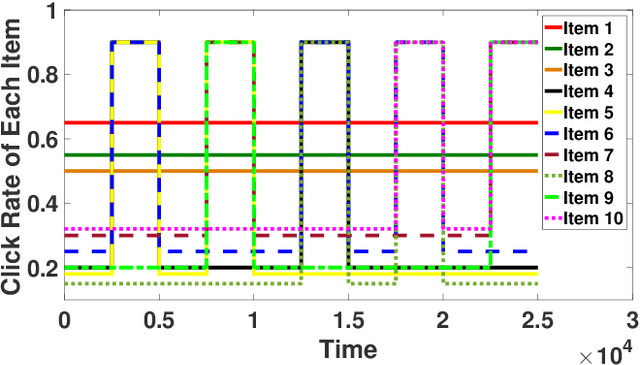

Cascading bandit (CB) is a variant of both the multi-armed bandit (MAB) and the cascade model (CM), where a learning agent aims to maximize the total reward by recommending $K$ out of $L$ items to a user. We focus on a common real-world scenario where the user's preference can change in a piecewise-stationary manner. Two efficient algorithms, \texttt{GLRT-CascadeUCB} and \texttt{GLRT-CascadeKL-UCB}, are developed. The key idea behind the proposed algorithms is incorporating an almost parameter-free change-point detector, the Generalized Likelihood Ratio Test (GLRT), within classical upper confidence bound (UCB) based algorithms. Gap-dependent regret upper bounds of the proposed algorithms are derived, both on the order of $\mathcal{O}(\sqrt{NLT\log{T}})$, where $N$ is the number of piecewise-stationary segments, and $T$ is the time horizon. We also derive a minimax lower bound on the order of $\mathcal{O}(\sqrt{NLT})$ for piecewise-stationary CB, showing that our proposed algorithms are optimal up to a poly-logarithmic factor $\sqrt{\log T}$. Lastly, we present numerical experiments on both synthetic and real-world datasets to show that \texttt{GLRT-CascadeUCB} and \texttt{GLRT-CascadeKL-UCB} outperform state-of-the-art algorithms in the literature.
Unsupervised Co-Learning on $\mathcal{G}$-Manifolds Across Irreducible Representations
Jun 29, 2019


We introduce a novel co-learning paradigm for manifolds naturally equipped with a group action, motivated by recent developments on learning a manifold from attached fibre bundle structures. We utilize a representation theoretic mechanism that canonically associates multiple independent vector bundles over a common base manifold, which provides multiple views for the geometry of the underlying manifold. The consistency across these fibre bundles provide a common base for performing unsupervised manifold co-learning through the redundancy created artificially across irreducible representations of the transformation group. We demonstrate the efficacy of the proposed algorithmic paradigm through drastically improved robust nearest neighbor search and community detection on rotation-invariant cryo-electron microscopy image analysis.
Multi-Frequency Vector Diffusion Maps
Jun 06, 2019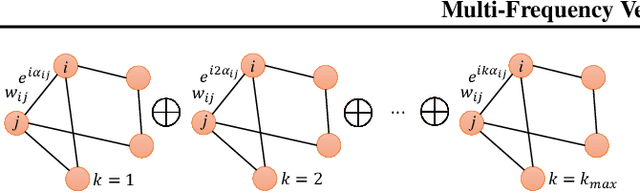
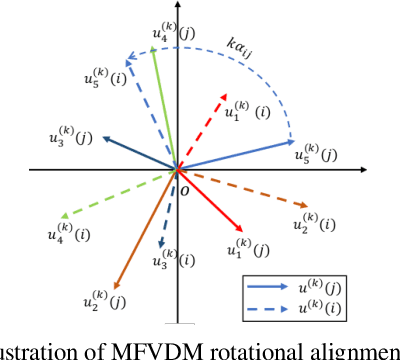
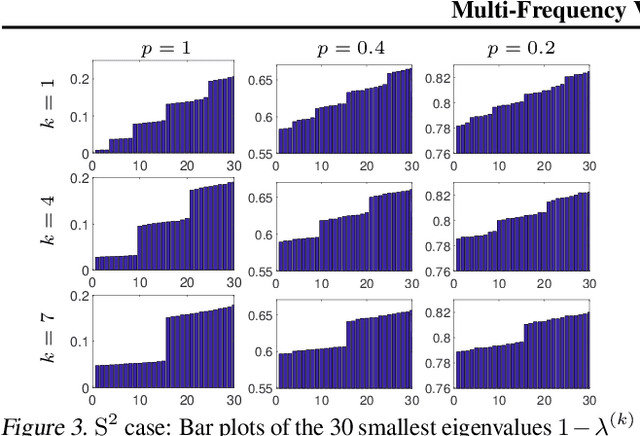
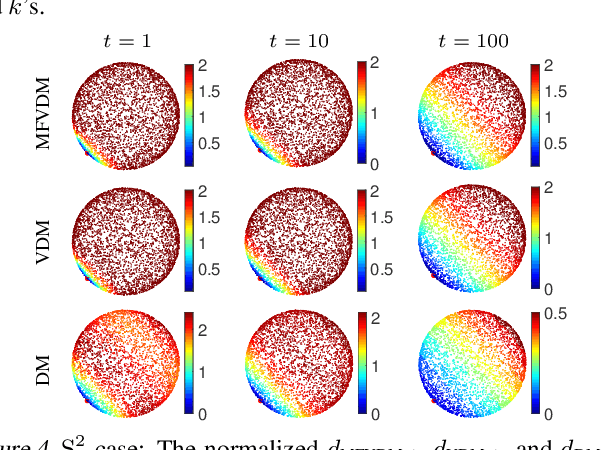
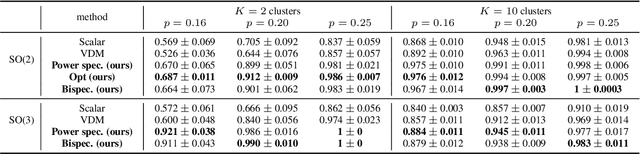
We introduce multi-frequency vector diffusion maps (MFVDM), a new framework for organizing and analyzing high dimensional datasets. The new method is a mathematical and algorithmic generalization of vector diffusion maps (VDM) and other non-linear dimensionality reduction methods. MFVDM combines different nonlinear embeddings of the data points defined with multiple unitary irreducible representations of the alignment group that connect two nodes in the graph. We illustrate the efficacy of MFVDM on synthetic data generated according to a random graph model and cryo-electron microscopy image dataset. The new method achieves better nearest neighbor search and alignment estimation than the state-of-the-arts VDM and diffusion maps (DM) on extremely noisy data.
Representation Theoretic Patterns in Multi-Frequency Class Averaging for Three-Dimensional Cryo-Electron Microscopy
May 31, 2019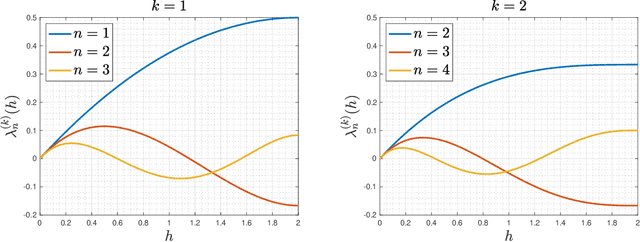
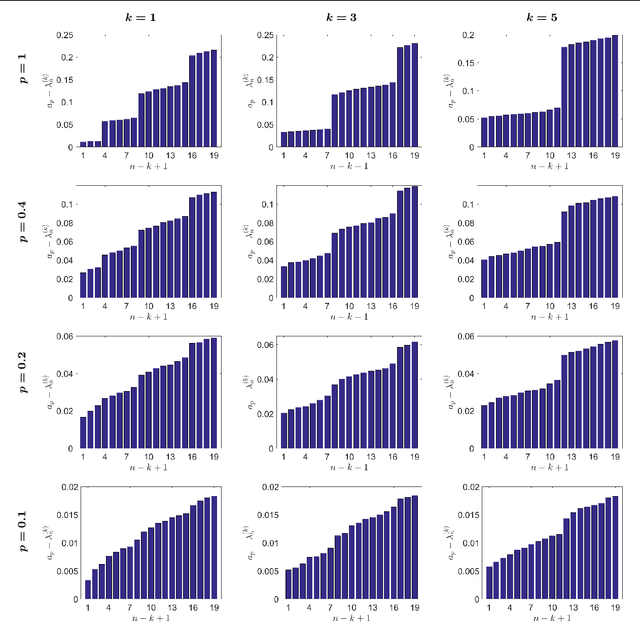
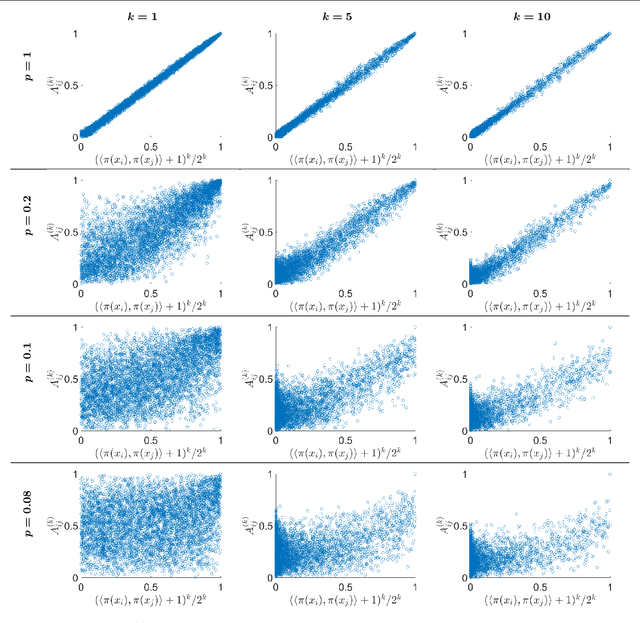
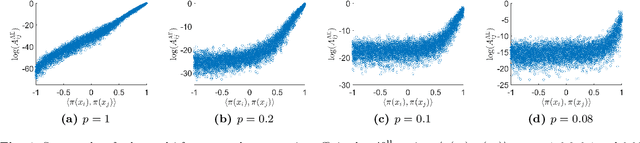
We develop in this paper a novel intrinsic classification algorithm -- multi-frequency class averaging (MFCA) -- for clustering noisy projection images obtained from three-dimensional cryo-electron microscopy (cryo-EM) by the similarity among their viewing directions. This new algorithm leverages multiple irreducible representations of the unitary group to introduce additional redundancy into the representation of the transport data, extending and outperforming the previous class averaging algorithm of Hadani and Singer [Foundations of Computational Mathematics, 11 (5), pp. 589--616 (2011)] that uses only a single representation. The formal algebraic model and representation theoretic patterns of the proposed MFCA algorithm extend the framework of Hadani and Singer to arbitrary irreducible representations of the unitary group. We conceptually establish the consistency and stability of MFCA by inspecting the spectral properties of a generalized localized parallel transport operator on the two-dimensional unit sphere through the lens of Wigner matrices. We demonstrate the efficacy of the proposed algorithm with numerical experiments.
Cryo-Electron Microscopy Image Analysis Using Multi-Frequency Vector Diffusion Maps
Apr 16, 2019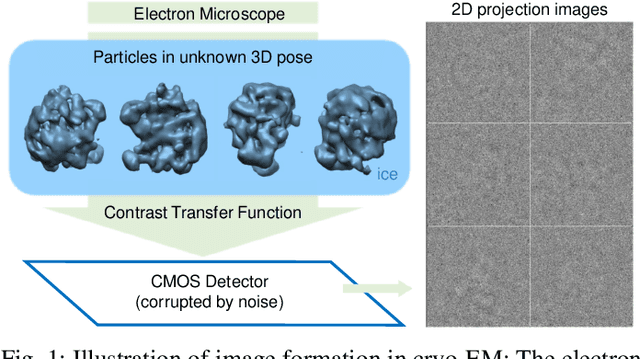
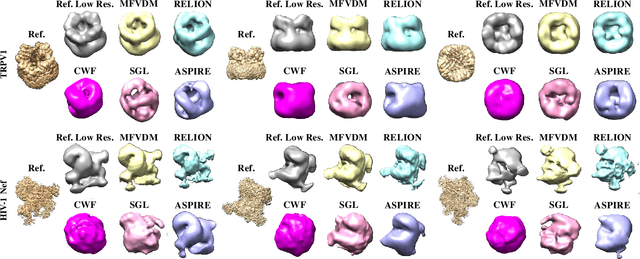
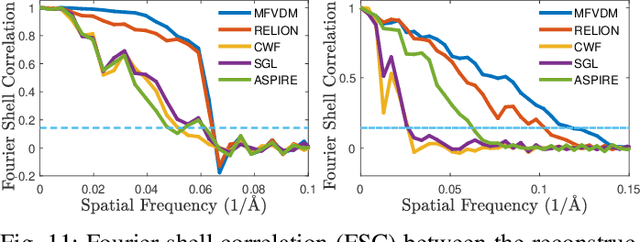

Cryo-electron microscopy (EM) single particle reconstruction is an entirely general technique for 3D structure determination of macromolecular complexes. However, because the images are taken at low electron dose, it is extremely hard to visualize the individual particle with low contrast and high noise level. In this paper, we propose a novel approach called multi-frequency vector diffusion maps (MFVDM) to improve the efficiency and accuracy of cryo-EM 2D image classification and denoising. This framework incorporates different irreducible representations of the estimated alignment between similar images. In addition, we propose a graph filtering scheme to denoise the images using the eigenvalues and eigenvectors of the MFVDM matrices. Through both simulated and publicly available real data, we demonstrate that our proposed method is efficient and robust to noise compared with the state-of-the-art cryo-EM 2D class averaging and image restoration algorithms.
Max-Sliced Wasserstein Distance and its use for GANs
Apr 11, 2019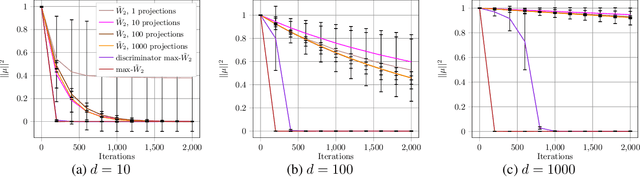

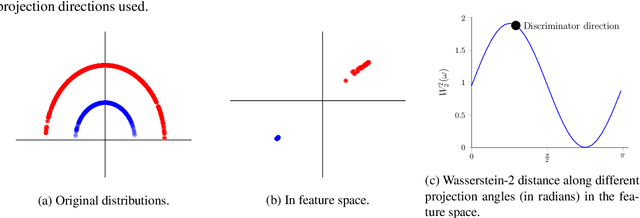

Generative adversarial nets (GANs) and variational auto-encoders have significantly improved our distribution modeling capabilities, showing promise for dataset augmentation, image-to-image translation and feature learning. However, to model high-dimensional distributions, sequential training and stacked architectures are common, increasing the number of tunable hyper-parameters as well as the training time. Nonetheless, the sample complexity of the distance metrics remains one of the factors affecting GAN training. We first show that the recently proposed sliced Wasserstein distance has compelling sample complexity properties when compared to the Wasserstein distance. To further improve the sliced Wasserstein distance we then analyze its `projection complexity' and develop the max-sliced Wasserstein distance which enjoys compelling sample complexity while reducing projection complexity, albeit necessitating a max estimation. We finally illustrate that the proposed distance trains GANs on high-dimensional images up to a resolution of 256x256 easily.