 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBe Aware of Non-Stationarity: Nearly Optimal Algorithms for Piecewise-Stationary Cascading Bandits
Paper and Code
Oct 07, 2019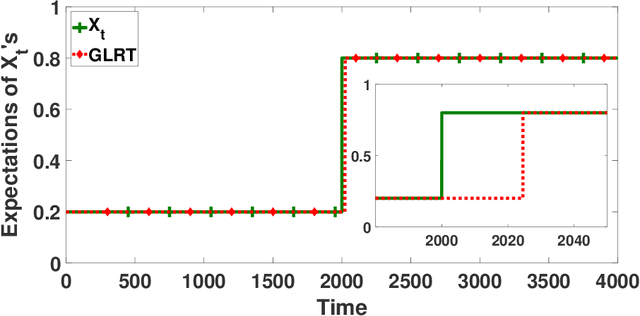
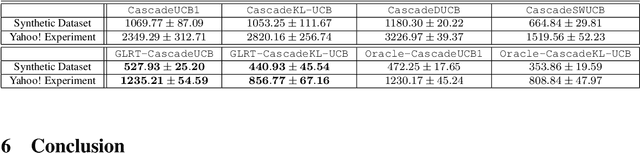
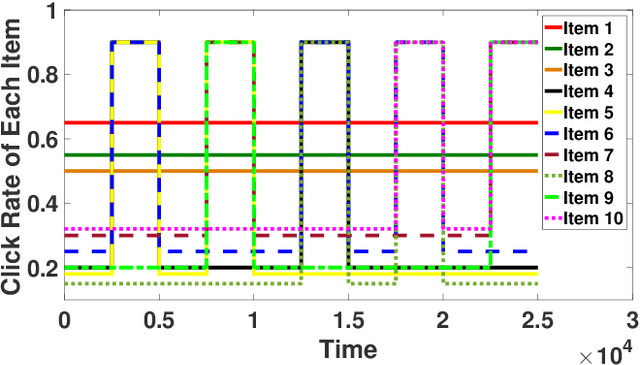

Cascading bandit (CB) is a variant of both the multi-armed bandit (MAB) and the cascade model (CM), where a learning agent aims to maximize the total reward by recommending $K$ out of $L$ items to a user. We focus on a common real-world scenario where the user's preference can change in a piecewise-stationary manner. Two efficient algorithms, \texttt{GLRT-CascadeUCB} and \texttt{GLRT-CascadeKL-UCB}, are developed. The key idea behind the proposed algorithms is incorporating an almost parameter-free change-point detector, the Generalized Likelihood Ratio Test (GLRT), within classical upper confidence bound (UCB) based algorithms. Gap-dependent regret upper bounds of the proposed algorithms are derived, both on the order of $\mathcal{O}(\sqrt{NLT\log{T}})$, where $N$ is the number of piecewise-stationary segments, and $T$ is the time horizon. We also derive a minimax lower bound on the order of $\mathcal{O}(\sqrt{NLT})$ for piecewise-stationary CB, showing that our proposed algorithms are optimal up to a poly-logarithmic factor $\sqrt{\log T}$. Lastly, we present numerical experiments on both synthetic and real-world datasets to show that \texttt{GLRT-CascadeUCB} and \texttt{GLRT-CascadeKL-UCB} outperform state-of-the-art algorithms in the literature.