 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaomi-Robotics-0: An Open-Sourced Vision-Language-Action Model with Real-Time Execution
Feb 13, 2026In this report, we introduce Xiaomi-Robotics-0, an advanced vision-language-action (VLA) model optimized for high performance and fast and smooth real-time execution. The key to our method lies in a carefully designed training recipe and deployment strategy. Xiaomi-Robotics-0 is first pre-trained on large-scale cross-embodiment robot trajectories and vision-language data, endowing it with broad and generalizable action-generation capabilities while avoiding catastrophic forgetting of the visual-semantic knowledge of the underlying pre-trained VLM. During post-training, we propose several techniques for training the VLA model for asynchronous execution to address the inference latency during real-robot rollouts. During deployment, we carefully align the timesteps of consecutive predicted action chunks to ensure continuous and seamless real-time rollouts. We evaluate Xiaomi-Robotics-0 extensively in simulation benchmarks and on two challenging real-robot tasks that require precise and dexterous bimanual manipulation. Results show that our method achieves state-of-the-art performance across all simulation benchmarks. Moreover, Xiaomi-Robotics-0 can roll out fast and smoothly on real robots using a consumer-grade GPU, achieving high success rates and throughput on both real-robot tasks. To facilitate future research, code and model checkpoints are open-sourced at https://xiaomi-robotics-0.github.io
FPC-VLA: A Vision-Language-Action Framework with a Supervisor for Failure Prediction and Correction
Sep 04, 2025



Robotic manipulation is a fundamental component of automation. However, traditional perception-planning pipelines often fall short in open-ended tasks due to limited flexibility, while the architecture of a single end-to-end Vision-Language-Action (VLA) offers promising capabilities but lacks crucial mechanisms for anticipating and recovering from failure. To address these challenges, we propose FPC-VLA, a dual-model framework that integrates VLA with a supervisor for failure prediction and correction. The supervisor evaluates action viability through vision-language queries and generates corrective strategies when risks arise, trained efficiently without manual labeling. A similarity-guided fusion module further refines actions by leveraging past predictions. Evaluation results on multiple simulation platforms (SIMPLER and LIBERO) and robot embodiments (WidowX, Google Robot, Franka) show that FPC-VLA outperforms state-of-the-art models in both zero-shot and fine-tuned settings. By activating the supervisor only at keyframes, our approach significantly increases task success rates with minimal impact on execution time. Successful real-world deployments on diverse, long-horizon tasks confirm FPC-VLA's strong generalization and practical utility for building more reliable autonomous systems.
Multi-Modal Fusion in Contact-Rich Precise Tasks via Hierarchical Policy Learning
Feb 17, 2022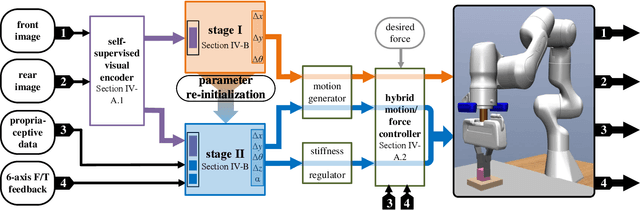

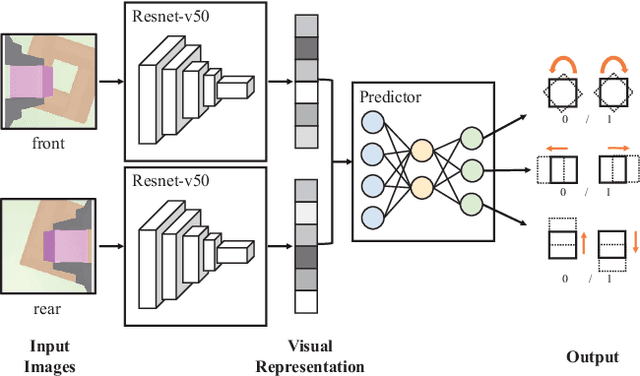
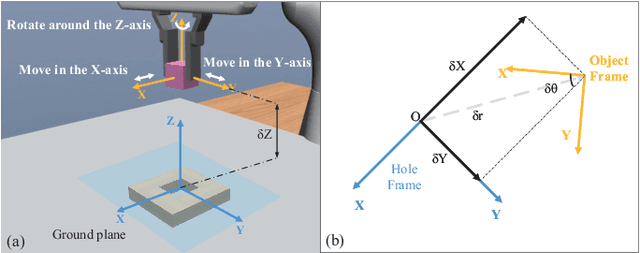
Combined visual and force feedback play an essential role in contact-rich robotic manipulation tasks. Current methods focus on developing the feedback control around a single modality while underrating the synergy of the sensors. Fusing different sensor modalities is necessary but remains challenging. A key challenge is to achieve an effective multi-modal and generalized control scheme to novel objects with precision. This paper proposes a practical multi-modal sensor fusion mechanism using hierarchical policy learning. To begin with, we use a self-supervised encoder that extracts multi-view visual features and a hybrid motion/force controller that regulates force behaviors. Next, the multi-modality fusion is simplified by hierarchical integration of the vision, force, and proprioceptive data in the reinforcement learning (RL) algorithm. Moreover, with hierarchical policy learning, the control scheme can exploit the visual feedback limits and explore the contribution of individual modality in precise tasks. Experiments indicate that robots with the control scheme could assemble objects with 0.25mm clearance in simulation. The system could be generalized to widely varied initial configurations and new shapes. Experiments validate that the simulated system can be robustly transferred to reality without fine-tuning.