 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Based Semi-Automatic Annotation for Scene Text Videos
Mar 29, 2021
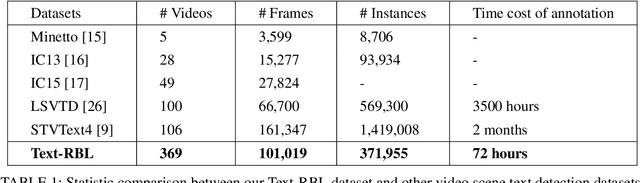

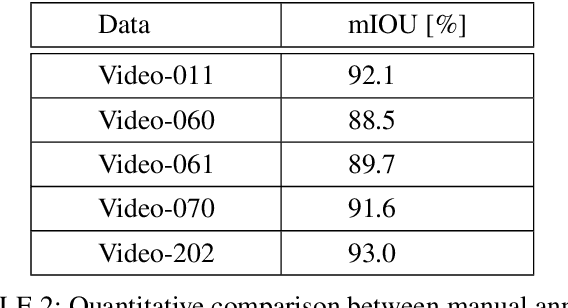
Recently, video scene text detection has received increasing attention due to its comprehensive applications. However, the lack of annotated scene text video datasets has become one of the most important problems, which hinders the development of video scene text detection. The existing scene text video datasets are not large-scale due to the expensive cost caused by manual labeling. In addition, the text instances in these datasets are too clear to be a challenge. To address the above issues, we propose a tracking based semi-automatic labeling strategy for scene text videos in this paper. We get semi-automatic scene text annotation by labeling manually for the first frame and tracking automatically for the subsequent frames, which avoid the huge cost of manual labeling. Moreover, a paired low-quality scene text video dataset named Text-RBL is proposed, consisting of raw videos, blurry videos, and low-resolution videos, labeled by the proposed convenient semi-automatic labeling strategy. Through an averaging operation and bicubic down-sampling operation over the raw videos, we can efficiently obtain blurry videos and low-resolution videos paired with raw videos separately. To verify the effectiveness of Text-RBL, we propose a baseline model combined with the text detector and tracker for video scene text detection. Moreover, a failure detection scheme is designed to alleviate the baseline model drift issue caused by complex scenes. Extensive experiments demonstrate that Text-RBL with paired low-quality videos labeled by the semi-automatic method can significantly improve the performance of the text detector in low-quality scenes.
Lipschitz Regularized CycleGAN for Improving Semantic Robustness in Unpaired Image-to-image Translation
Dec 09, 2020
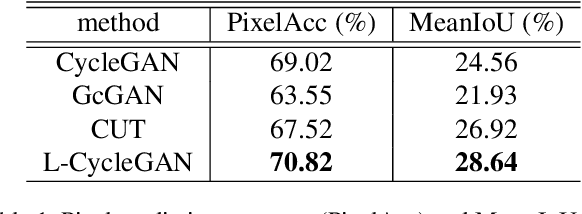

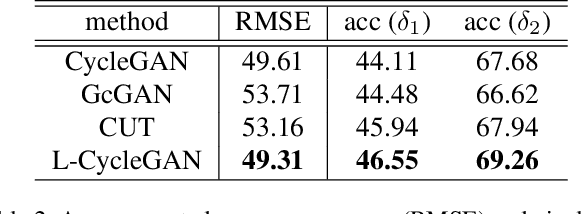
For unpaired image-to-image translation tasks, GAN-based approaches are susceptible to semantic flipping, i.e., contents are not preserved consistently. We argue that this is due to (1) the difference in semantic statistics between source and target domains and (2) the learned generators being non-robust. In this paper, we proposed a novel approach, Lipschitz regularized CycleGAN, for improving semantic robustness and thus alleviating the semantic flipping issue. During training, we add a gradient penalty loss to the generators, which encourages semantically consistent transformations. We evaluate our approach on multiple common datasets and compare with several existing GAN-based methods. Both quantitative and visual results suggest the effectiveness and advantage of our approach in producing robust transformations with fewer semantic flipping.
Refactoring Policy for Compositional Generalizability using Self-Supervised Object Proposals
Oct 26, 2020
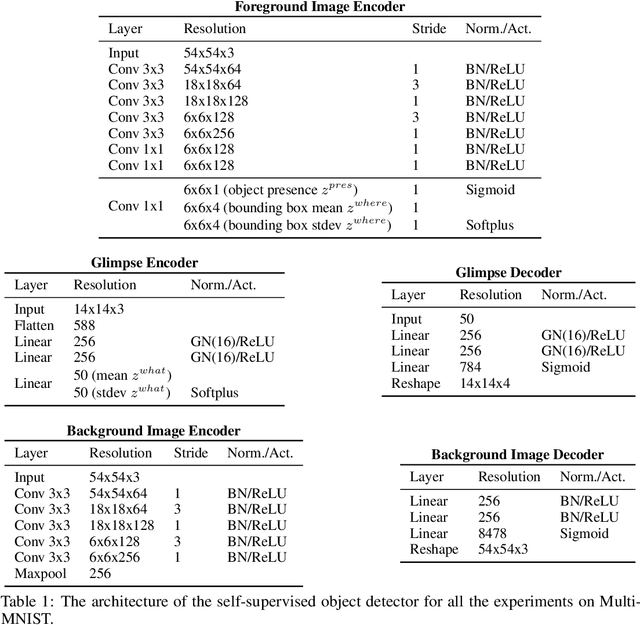


We study how to learn a policy with compositional generalizability. We propose a two-stage framework, which refactorizes a high-reward teacher policy into a generalizable student policy with strong inductive bias. Particularly, we implement an object-centric GNN-based student policy, whose input objects are learned from images through self-supervised learning. Empirically, we evaluate our approach on four difficult tasks that require compositional generalizability, and achieve superior performance compared to baselines.
One-pixel Signature: Characterizing CNN Models for Backdoor Detection
Aug 18, 2020

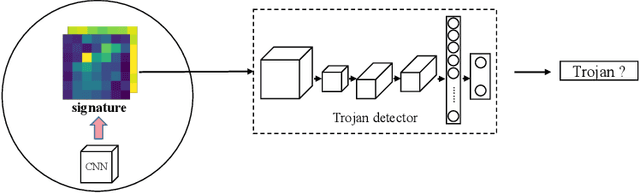
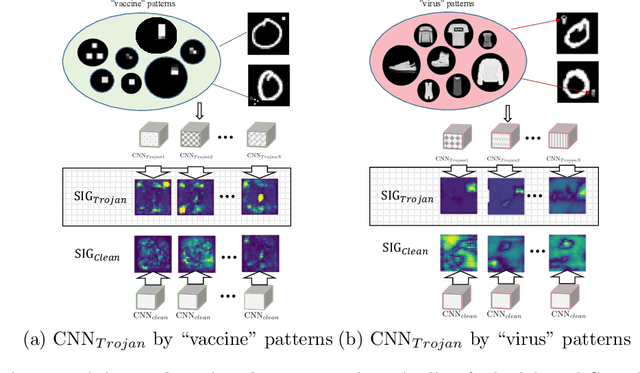
We tackle the convolution neural networks (CNNs) backdoor detection problem by proposing a new representation called one-pixel signature. Our task is to detect/classify if a CNN model has been maliciously inserted with an unknown Trojan trigger or not. Here, each CNN model is associated with a signature that is created by generating, pixel-by-pixel, an adversarial value that is the result of the largest change to the class prediction. The one-pixel signature is agnostic to the design choice of CNN architectures, and how they were trained. It can be computed efficiently for a black-box CNN model without accessing the network parameters. Our proposed one-pixel signature demonstrates a substantial improvement (by around 30% in the absolute detection accuracy) over the existing competing methods for backdoored CNN detection/classification. One-pixel signature is a general representation that can be used to characterize CNN models beyond backdoor detection.
Information-Theoretic Local Minima Characterization and Regularization
Nov 19, 2019



Recent advances in deep learning theory have evoked the study of generalizability across different local minima of deep neural networks (DNNs). While current work focused on either discovering properties of good local minima or developing regularization techniques to induce good local minima, no approach exists that can tackle both problems. We achieve these two goals successfully in a unified manner. Specifically, based on the Fisher information we propose a metric both strongly indicative of generalizability of local minima and effectively applied as a practical regularizer. We provide theoretical analysis including a generalization bound and empirically demonstrate the success of our approach in both capturing and improving the generalizability of DNNs. Experiments are performed on CIFAR-10 and CIFAR-100 for various network architectures.
Controllable Top-down Feature Transformer
Nov 04, 2018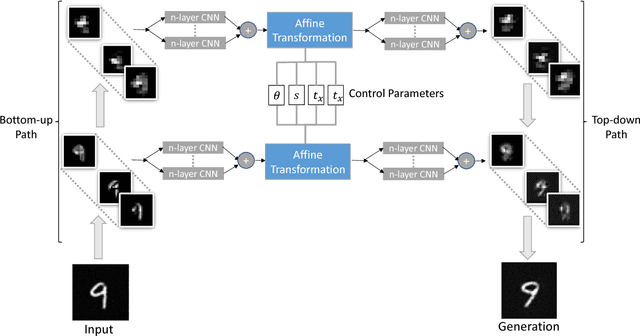
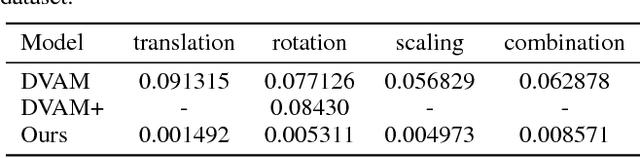
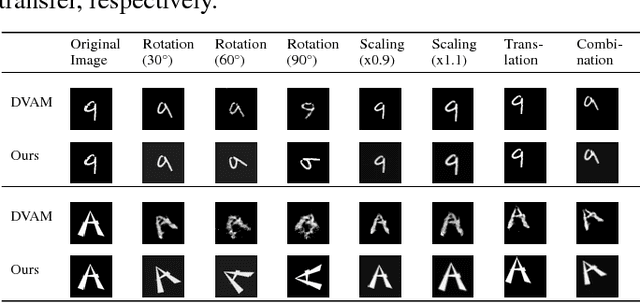

We study the intrinsic transformation of feature maps across convolutional network layers with explicit top-down control. To this end, we develop top-down feature transformer (TFT), under controllable parameters, that are able to account for the hidden layer transformation while maintaining the overall consistency across layers. The learned generators capture the underlying feature transformation processes that are independent of particular training images. Our proposed TFT framework brings insights to and helps the understanding of, an important problem of studying the CNN internal feature representation and transformation under the top-down processes. In the case of spatial transformations, we demonstrate the significant advantage of TFT over existing data-driven approaches in building data-independent transformations. We also show that it can be adopted in other applications such as data augmentation and image style transfer.