 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Long Short-Term Memory Networks for Sub-Character Representation Learning
Jan 04, 2018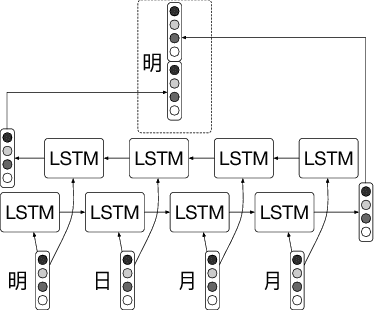
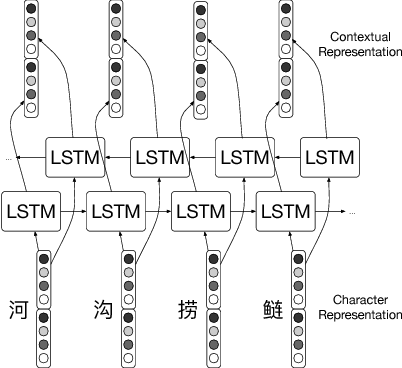
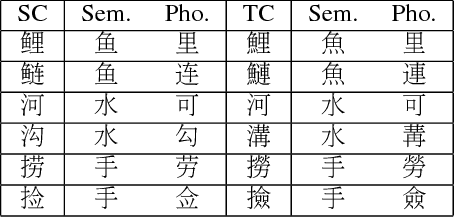
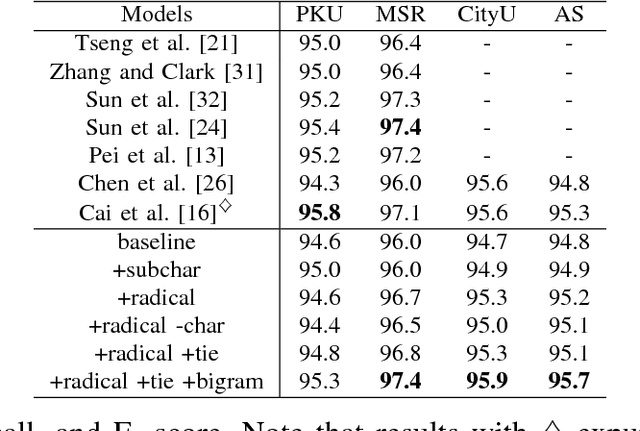
Characters have commonly been regarded as the minimal processing unit in Natural Language Processing (NLP). But many non-latin languages have hieroglyphic writing systems, involving a big alphabet with thousands or millions of characters. Each character is composed of even smaller parts, which are often ignored by the previous work. In this paper, we propose a novel architecture employing two stacked Long Short-Term Memory Networks (LSTMs) to learn sub-character level representation and capture deeper level of semantic meanings. To build a concrete study and substantiate the efficiency of our neural architecture, we take Chinese Word Segmentation as a research case example. Among those languages, Chinese is a typical case, for which every character contains several components called radicals. Our networks employ a shared radical level embedding to solve both Simplified and Traditional Chinese Word Segmentation, without extra Traditional to Simplified Chinese conversion, in such a highly end-to-end way the word segmentation can be significantly simplified compared to the previous work. Radical level embeddings can also capture deeper semantic meaning below character level and improve the system performance of learning. By tying radical and character embeddings together, the parameter count is reduced whereas semantic knowledge is shared and transferred between two levels, boosting the performance largely. On 3 out of 4 Bakeoff 2005 datasets, our method surpassed state-of-the-art results by up to 0.4%. Our results are reproducible, source codes and corpora are available on GitHub.
Scene Flow to Action Map: A New Representation for RGB-D based Action Recognition with Convolutional Neural Networks
Mar 27, 2017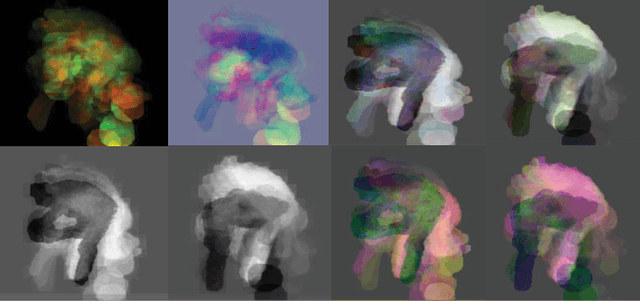
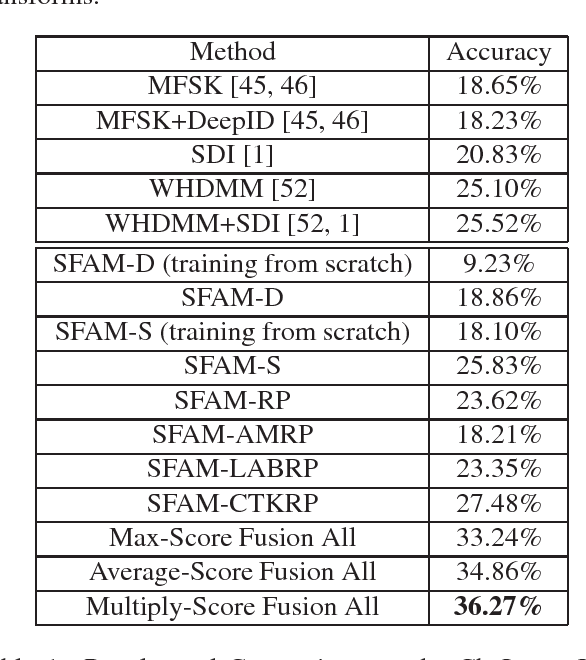

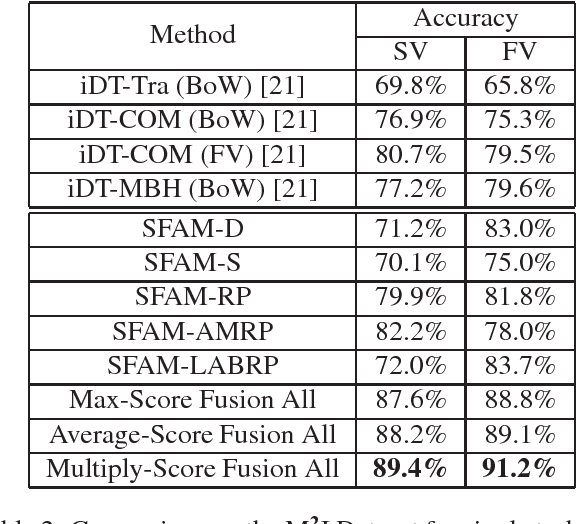
Scene flow describes the motion of 3D objects in real world and potentially could be the basis of a good feature for 3D action recognition. However, its use for action recognition, especially in the context of convolutional neural networks (ConvNets), has not been previously studied. In this paper, we propose the extraction and use of scene flow for action recognition from RGB-D data. Previous works have considered the depth and RGB modalities as separate channels and extract features for later fusion. We take a different approach and consider the modalities as one entity, thus allowing feature extraction for action recognition at the beginning. Two key questions about the use of scene flow for action recognition are addressed: how to organize the scene flow vectors and how to represent the long term dynamics of videos based on scene flow. In order to calculate the scene flow correctly on the available datasets, we propose an effective self-calibration method to align the RGB and depth data spatially without knowledge of the camera parameters. Based on the scene flow vectors, we propose a new representation, namely, Scene Flow to Action Map (SFAM), that describes several long term spatio-temporal dynamics for action recognition. We adopt a channel transform kernel to transform the scene flow vectors to an optimal color space analogous to RGB. This transformation takes better advantage of the trained ConvNets models over ImageNet. Experimental results indicate that this new representation can surpass the performance of state-of-the-art methods on two large public datasets.
Large-scale Isolated Gesture Recognition Using Convolutional Neural Networks
Jan 07, 2017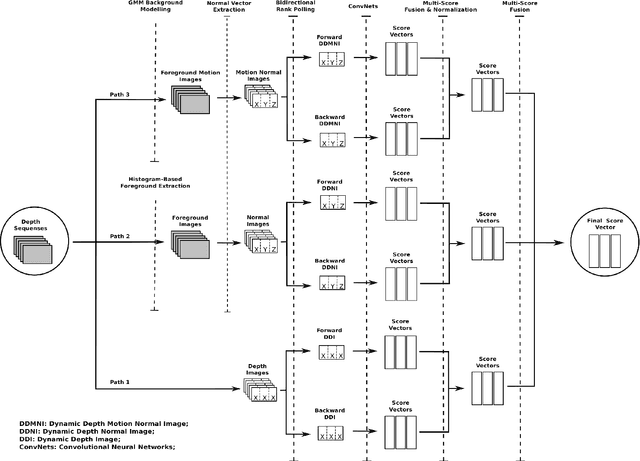


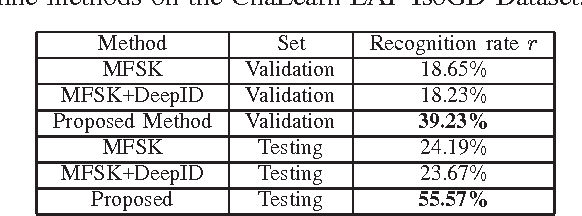
This paper proposes three simple, compact yet effective representations of depth sequences, referred to respectively as Dynamic Depth Images (DDI), Dynamic Depth Normal Images (DDNI) and Dynamic Depth Motion Normal Images (DDMNI). These dynamic images are constructed from a sequence of depth maps using bidirectional rank pooling to effectively capture the spatial-temporal information. Such image-based representations enable us to fine-tune the existing ConvNets models trained on image data for classification of depth sequences, without introducing large parameters to learn. Upon the proposed representations, a convolutional Neural networks (ConvNets) based method is developed for gesture recognition and evaluated on the Large-scale Isolated Gesture Recognition at the ChaLearn Looking at People (LAP) challenge 2016. The method achieved 55.57\% classification accuracy and ranked $2^{nd}$ place in this challenge but was very close to the best performance even though we only used depth data.
Large-scale Continuous Gesture Recognition Using Convolutional Neural Networks
Sep 12, 2016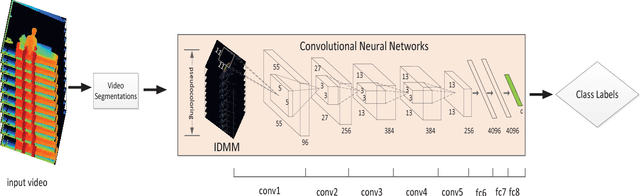


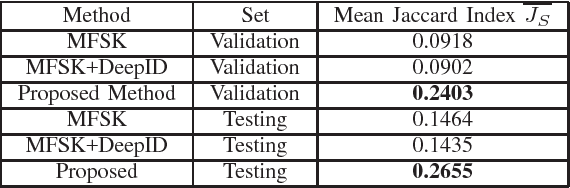
This paper addresses the problem of continuous gesture recognition from sequences of depth maps using convolutional neutral networks (ConvNets). The proposed method first segments individual gestures from a depth sequence based on quantity of movement (QOM). For each segmented gesture, an Improved Depth Motion Map (IDMM), which converts the depth sequence into one image, is constructed and fed to a ConvNet for recognition. The IDMM effectively encodes both spatial and temporal information and allows the fine-tuning with existing ConvNet models for classification without introducing millions of parameters to learn. The proposed method is evaluated on the Large-scale Continuous Gesture Recognition of the ChaLearn Looking at People (LAP) challenge 2016. It achieved the performance of 0.2655 (Mean Jaccard Index) and ranked $3^{rd}$ place in this challenge.
HEp-2 Cell Image Classification with Deep Convolutional Neural Networks
May 18, 2015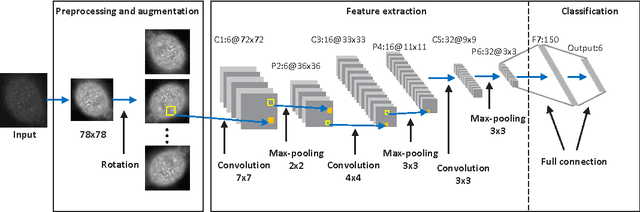
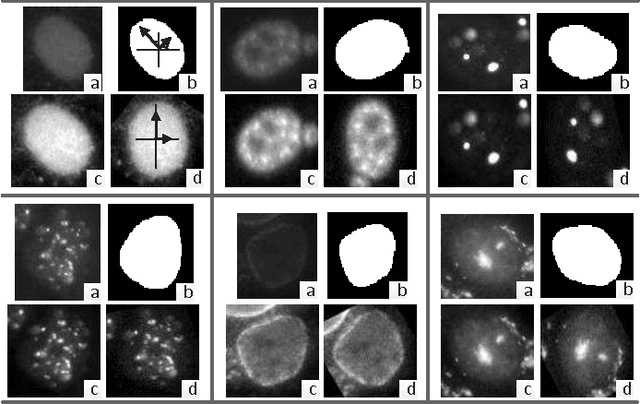

Efficient Human Epithelial-2 (HEp-2) cell image classification can facilitate the diagnosis of many autoimmune diseases. This paper presents an automatic framework for this classification task, by utilizing the deep convolutional neural networks (CNNs) which have recently attracted intensive attention in visual recognition. This paper elaborates the important components of this framework, discusses multiple key factors that impact the efficiency of training a deep CNN, and systematically compares this framework with the well-established image classification models in the literature. Experiments on benchmark datasets show that i) the proposed framework can effectively outperform existing models by properly applying data augmentation; ii) our CNN-based framework demonstrates excellent adaptability across different datasets, which is highly desirable for classification under varying laboratory settings. Our system is ranked high in the cell image classification competition hosted by ICPR 2014.
Deep Convolutional Neural Networks for Action Recognition Using Depth Map Sequences
Jan 20, 2015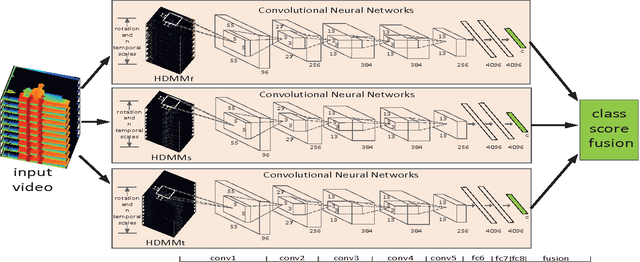
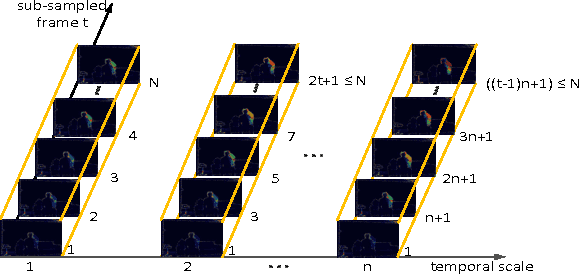
Recently, deep learning approach has achieved promising results in various fields of computer vision. In this paper, a new framework called Hierarchical Depth Motion Maps (HDMM) + 3 Channel Deep Convolutional Neural Networks (3ConvNets) is proposed for human action recognition using depth map sequences. Firstly, we rotate the original depth data in 3D pointclouds to mimic the rotation of cameras, so that our algorithms can handle view variant cases. Secondly, in order to effectively extract the body shape and motion information, we generate weighted depth motion maps (DMM) at several temporal scales, referred to as Hierarchical Depth Motion Maps (HDMM). Then, three channels of ConvNets are trained on the HDMMs from three projected orthogonal planes separately. The proposed algorithms are evaluated on MSRAction3D, MSRAction3DExt, UTKinect-Action and MSRDailyActivity3D datasets respectively. We also combine the last three datasets into a larger one (called Combined Dataset) and test the proposed method on it. The results show that our approach can achieve state-of-the-art results on the individual datasets and without dramatical performance degradation on the Combined Dataset.
Mining Mid-level Features for Action Recognition Based on Effective Skeleton Representation
Sep 14, 2014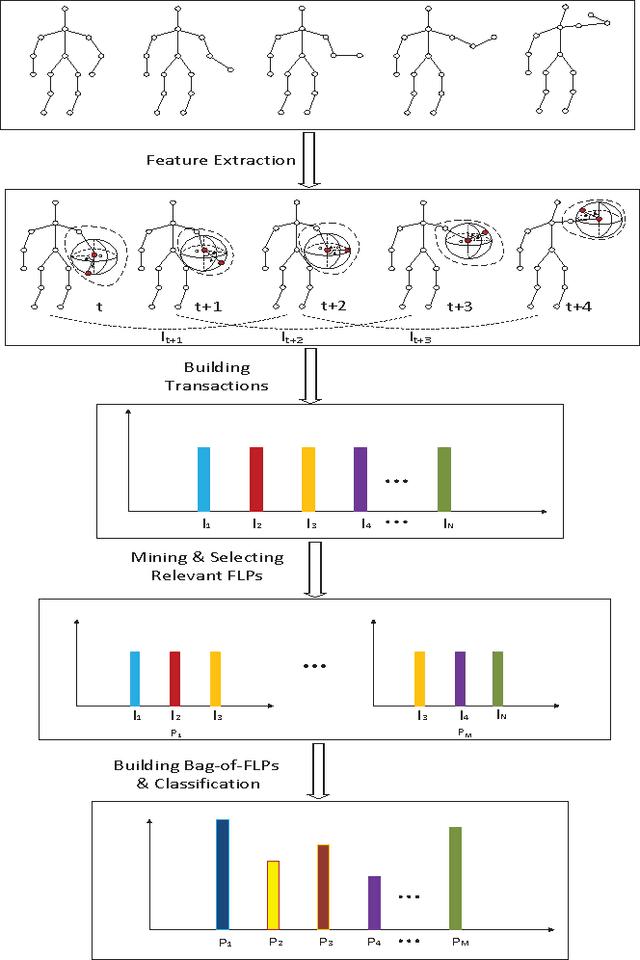
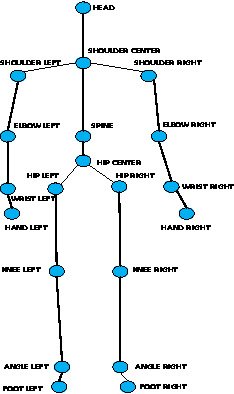

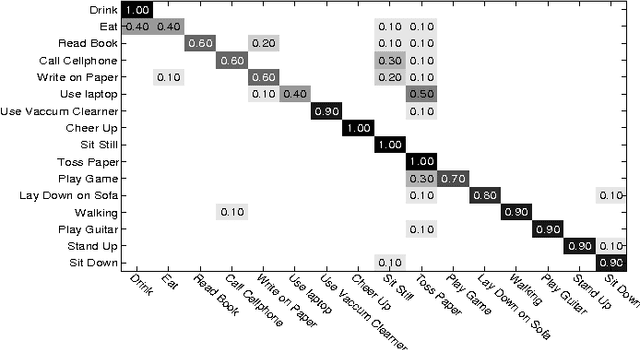
Recently, mid-level features have shown promising performance in computer vision. Mid-level features learned by incorporating class-level information are potentially more discriminative than traditional low-level local features. In this paper, an effective method is proposed to extract mid-level features from Kinect skeletons for 3D human action recognition. Firstly, the orientations of limbs connected by two skeleton joints are computed and each orientation is encoded into one of the 27 states indicating the spatial relationship of the joints. Secondly, limbs are combined into parts and the limb's states are mapped into part states. Finally, frequent pattern mining is employed to mine the most frequent and relevant (discriminative, representative and non-redundant) states of parts in continuous several frames. These parts are referred to as Frequent Local Parts or FLPs. The FLPs allow us to build powerful bag-of-FLP-based action representation. This new representation yields state-of-the-art results on MSR DailyActivity3D and MSR ActionPairs3D.