 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Model Attention Aligned with Human Attention? An Empirical Study on Large Language Models for Code Generation
Jun 02, 2023Large Language Models (LLMs) have been demonstrated effective for code generation. Due to the complexity and opacity of LLMs, little is known about how these models generate code. To deepen our understanding, we investigate whether LLMs attend to the same parts of a natural language description as human programmers during code generation. An analysis of five LLMs on a popular benchmark, HumanEval, revealed a consistent misalignment between LLMs' and programmers' attention. Furthermore, we found that there is no correlation between the code generation accuracy of LLMs and their alignment with human programmers. Through a quantitative experiment and a user study, we confirmed that, among twelve different attention computation methods, attention computed by the perturbation-based method is most aligned with human attention and is constantly favored by human programmers. Our findings highlight the need for human-aligned LLMs for better interpretability and programmer trust.
Towards Efficient Deep Hashing Retrieval: Condensing Your Data via Feature-Embedding Matching
May 29, 2023



The expenses involved in training state-of-the-art deep hashing retrieval models have witnessed an increase due to the adoption of more sophisticated models and large-scale datasets. Dataset Distillation (DD) or Dataset Condensation(DC) focuses on generating smaller synthetic dataset that retains the original information. Nevertheless, existing DD methods face challenges in maintaining a trade-off between accuracy and efficiency. And the state-of-the-art dataset distillation methods can not expand to all deep hashing retrieval methods. In this paper, we propose an efficient condensation framework that addresses these limitations by matching the feature-embedding between synthetic set and real set. Furthermore, we enhance the diversity of features by incorporating the strategies of early-stage augmented models and multi-formation. Extensive experiments provide compelling evidence of the remarkable superiority of our approach, both in terms of performance and efficiency, compared to state-of-the-art baseline methods.
DeepLens: Interactive Out-of-distribution Data Detection in NLP Models
Mar 02, 2023Machine Learning (ML) has been widely used in Natural Language Processing (NLP) applications. A fundamental assumption in ML is that training data and real-world data should follow a similar distribution. However, a deployed ML model may suffer from out-of-distribution (OOD) issues due to distribution shifts in the real-world data. Though many algorithms have been proposed to detect OOD data from text corpora, there is still a lack of interactive tool support for ML developers. In this work, we propose DeepLens, an interactive system that helps users detect and explore OOD issues in massive text corpora. Users can efficiently explore different OOD types in DeepLens with the help of a text clustering method. Users can also dig into a specific text by inspecting salient words highlighted through neuron activation analysis. In a within-subjects user study with 24 participants, participants using DeepLens were able to find nearly twice more types of OOD issues accurately with 22% more confidence compared with a variant of DeepLens that has no interaction or visualization support.
DeepSeer: Interactive RNN Explanation and Debugging via State Abstraction
Mar 02, 2023



Recurrent Neural Networks (RNNs) have been widely used in Natural Language Processing (NLP) tasks given its superior performance on processing sequential data. However, it is challenging to interpret and debug RNNs due to the inherent complexity and the lack of transparency of RNNs. While many explainable AI (XAI) techniques have been proposed for RNNs, most of them only support local explanations rather than global explanations. In this paper, we present DeepSeer, an interactive system that provides both global and local explanations of RNN behavior in multiple tightly-coordinated views for model understanding and debugging. The core of DeepSeer is a state abstraction method that bundles semantically similar hidden states in an RNN model and abstracts the model as a finite state machine. Users can explore the global model behavior by inspecting text patterns associated with each state and the transitions between states. Users can also dive into individual predictions by inspecting the state trace and intermediate prediction results of a given input. A between-subjects user study with 28 participants shows that, compared with a popular XAI technique, LIME, participants using DeepSeer made a deeper and more comprehensive assessment of RNN model behavior, identified the root causes of incorrect predictions more accurately, and came up with more actionable plans to improve the model performance.
An Exploratory Study of AI System Risk Assessment from the Lens of Data Distribution and Uncertainty
Dec 13, 2022Deep learning (DL) has become a driving force and has been widely adopted in many domains and applications with competitive performance. In practice, to solve the nontrivial and complicated tasks in real-world applications, DL is often not used standalone, but instead contributes as a piece of gadget of a larger complex AI system. Although there comes a fast increasing trend to study the quality issues of deep neural networks (DNNs) at the model level, few studies have been performed to investigate the quality of DNNs at both the unit level and the potential impacts on the system level. More importantly, it also lacks systematic investigation on how to perform the risk assessment for AI systems from unit level to system level. To bridge this gap, this paper initiates an early exploratory study of AI system risk assessment from both the data distribution and uncertainty angles to address these issues. We propose a general framework with an exploratory study for analyzing AI systems. After large-scale (700+ experimental configurations and 5000+ GPU hours) experiments and in-depth investigations, we reached a few key interesting findings that highlight the practical need and opportunities for more in-depth investigations into AI systems.
AI-driven Mobile Apps: an Explorative Study
Dec 03, 2022Recent years have witnessed an astonishing explosion in the evolution of mobile applications powered by AI technologies. The rapid growth of AI frameworks enables the transition of AI technologies to mobile devices, significantly prompting the adoption of AI apps (i.e., apps that integrate AI into their functions) among smartphone devices. In this paper, we conduct the most extensive empirical study on 56,682 published AI apps from three perspectives: dataset characteristics, development issues, and user feedback and privacy. To this end, we build an automated AI app identification tool, AI Discriminator, that detects eligible AI apps from 7,259,232 mobile apps. First, we carry out a dataset analysis, where we explore the AndroZoo large repository to identify AI apps and their core characteristics. Subsequently, we pinpoint key issues in AI app development (e.g., model protection). Finally, we focus on user reviews and user privacy protection. Our paper provides several notable findings. Some essential ones involve revealing the issue of insufficient model protection by presenting the lack of model encryption, and demonstrating the risk of user privacy data being leaked. We published our large-scale AI app datasets to inspire more future research.
Common Corruption Robustness of Point Cloud Detectors: Benchmark and Enhancement
Oct 12, 2022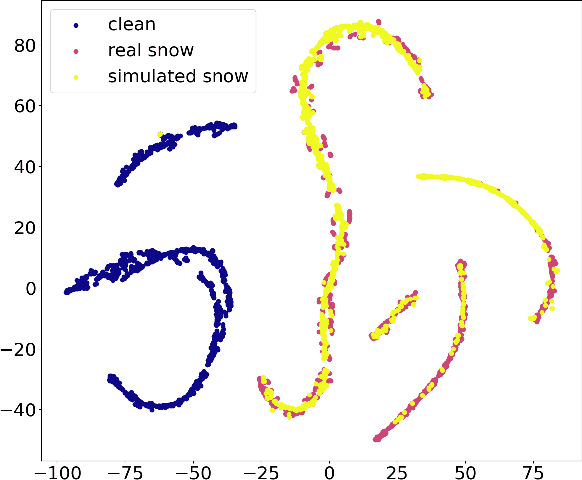
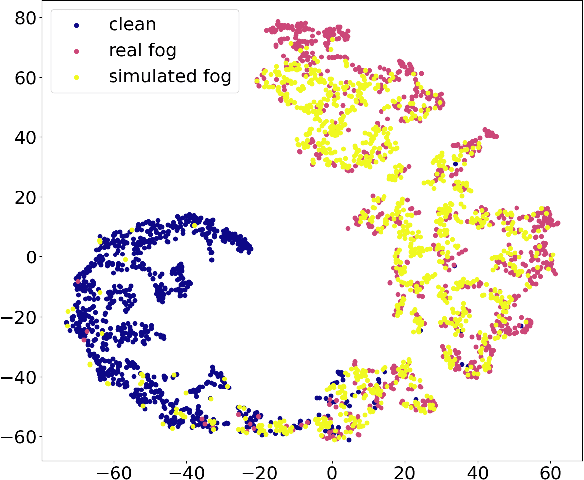
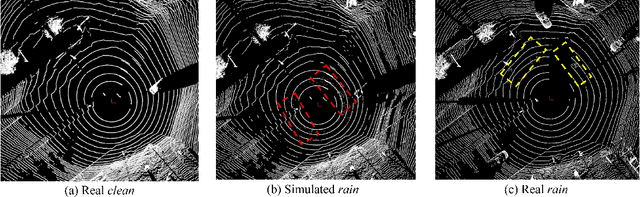
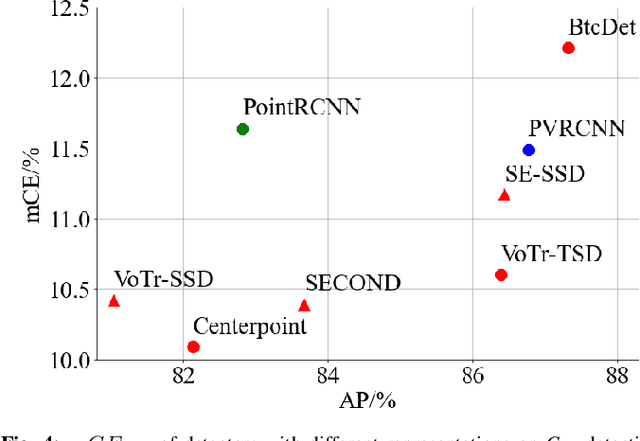
Object detection through LiDAR-based point cloud has recently been important in autonomous driving. Although achieving high accuracy on public benchmarks, the state-of-the-art detectors may still go wrong and cause a heavy loss due to the widespread corruptions in the real world like rain, snow, sensor noise, etc. Nevertheless, there is a lack of a large-scale dataset covering diverse scenes and realistic corruption types with different severities to develop practical and robust point cloud detectors, which is challenging due to the heavy collection costs. To alleviate the challenge and start the first step for robust point cloud detection, we propose the physical-aware simulation methods to generate degraded point clouds under different real-world common corruptions. Then, for the first attempt, we construct a benchmark based on the physical-aware common corruptions for point cloud detectors, which contains a total of 1,122,150 examples covering 7,481 scenes, 25 common corruption types, and 6 severities. With such a novel benchmark, we conduct extensive empirical studies on 8 state-of-the-art detectors that contain 6 different detection frameworks. Thus we get several insight observations revealing the vulnerabilities of the detectors and indicating the enhancement directions. Moreover, we further study the effectiveness of existing robustness enhancement methods based on data augmentation and data denoising. The benchmark can potentially be a new platform for evaluating point cloud detectors, opening a door for developing novel robustness enhancement methods.
Rethinking Unsupervised Domain Adaptation for Semantic Segmentation
Jun 30, 2022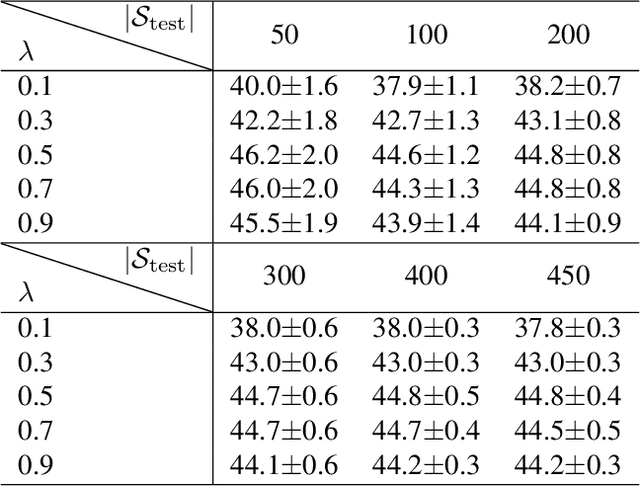
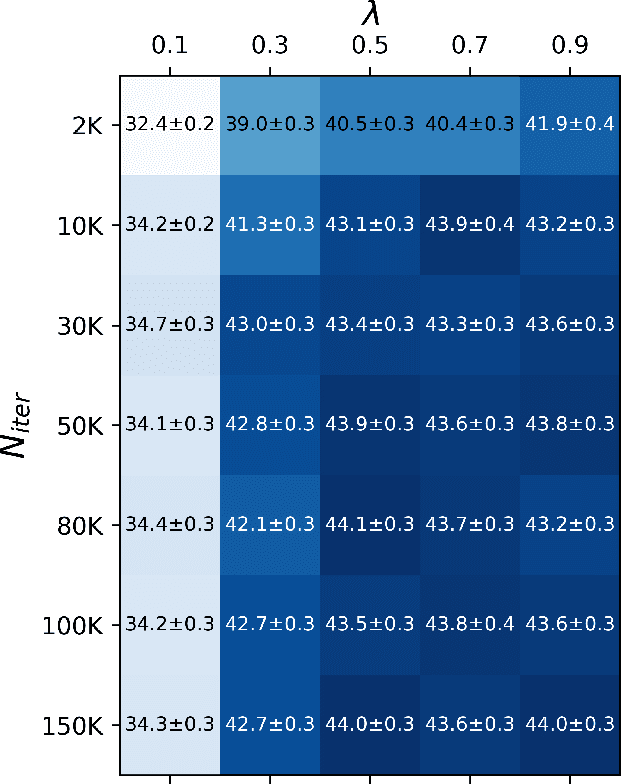
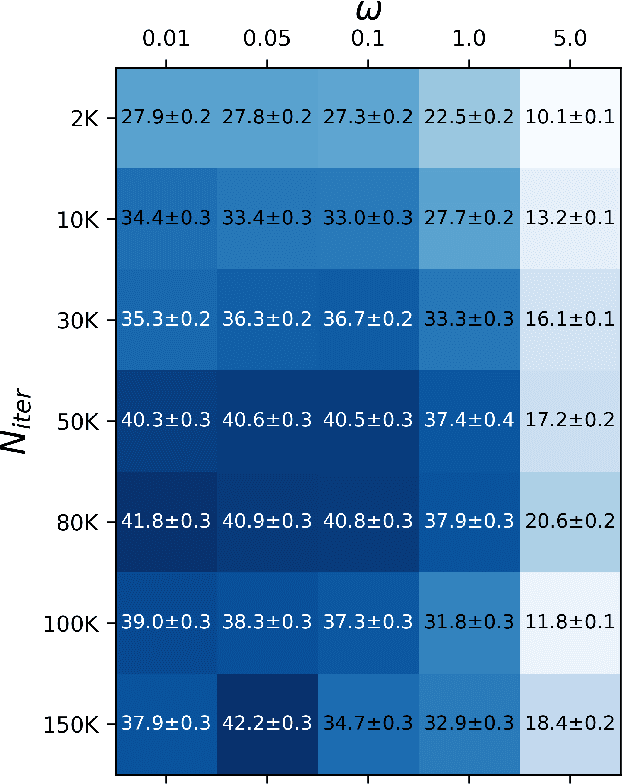
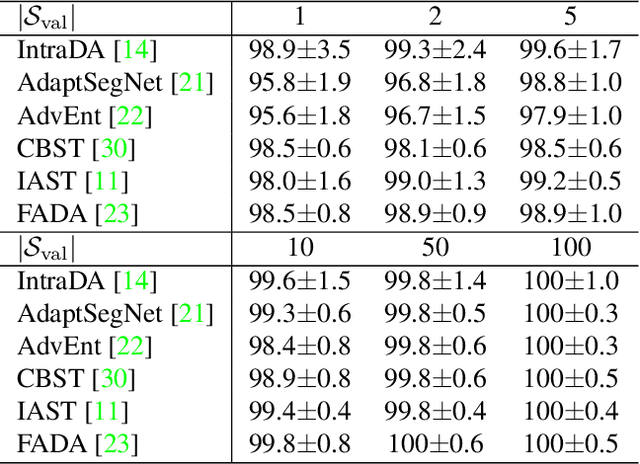
Unsupervised domain adaptation (UDA) adapts a model trained on one domain to a novel domain using only unlabeled data. So many studies have been conducted, especially for semantic segmentation due to its high annotation cost. The existing studies stick to the basic assumption that no labeled sample is available for the new domain. However, this assumption has several issues. First, it is pretty unrealistic, considering the standard practice of ML to confirm the model's performance before its deployment; the confirmation needs labeled data. Second, any UDA method will have a few hyper-parameters, needing a certain amount of labeled data. To rectify this misalignment with reality, we rethink UDA from a data-centric point of view. Specifically, we start with the assumption that we do have access to a minimum level of labeled data. Then, we ask how many labeled samples are necessary for finding satisfactory hyper-parameters of existing UDA methods. How well does it work if we use the same data to train the model, e.g., finetuning? We conduct experiments to answer these questions with popular scenarios, {GTA5, SYNTHIA}$\rightarrow$Cityscapes. Our findings are as follows: i) for some UDA methods, good hyper-parameters can be found with only a few labeled samples (i.e., images), e.g., five, but this does not apply to others, and ii) finetuning outperforms most existing UDA methods with only ten labeled images.
ArchRepair: Block-Level Architecture-Oriented Repairing for Deep Neural Networks
Dec 11, 2021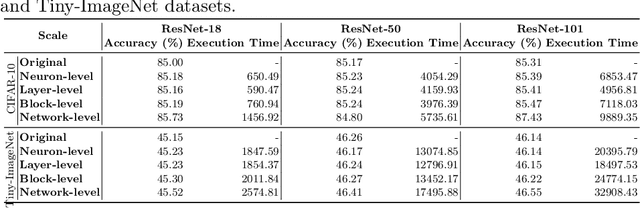
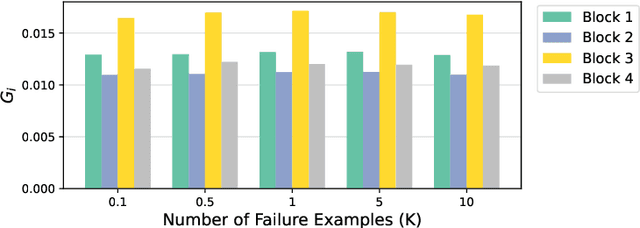
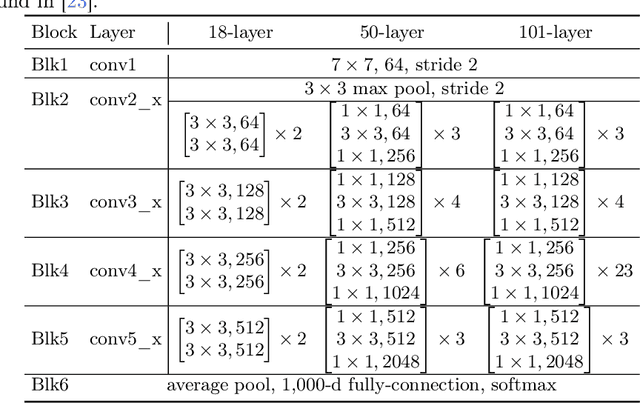
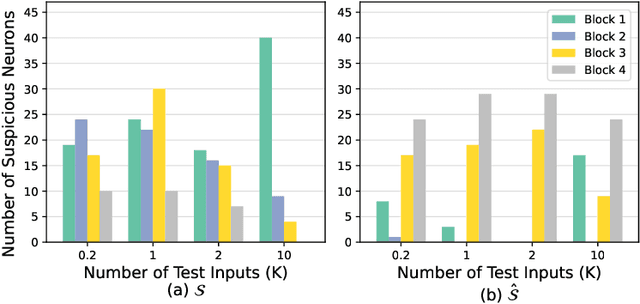
Over the past few years, deep neural networks (DNNs) have achieved tremendous success and have been continuously applied in many application domains. However, during the practical deployment in the industrial tasks, DNNs are found to be erroneous-prone due to various reasons such as overfitting, lacking robustness to real-world corruptions during practical usage. To address these challenges, many recent attempts have been made to repair DNNs for version updates under practical operational contexts by updating weights (i.e., network parameters) through retraining, fine-tuning, or direct weight fixing at a neural level. In this work, as the first attempt, we initiate to repair DNNs by jointly optimizing the architecture and weights at a higher (i.e., block) level. We first perform empirical studies to investigate the limitation of whole network-level and layer-level repairing, which motivates us to explore a novel repairing direction for DNN repair at the block level. To this end, we first propose adversarial-aware spectrum analysis for vulnerable block localization that considers the neurons' status and weights' gradients in blocks during the forward and backward processes, which enables more accurate candidate block localization for repairing even under a few examples. Then, we further propose the architecture-oriented search-based repairing that relaxes the targeted block to a continuous repairing search space at higher deep feature levels. By jointly optimizing the architecture and weights in that space, we can identify a much better block architecture. We implement our proposed repairing techniques as a tool, named ArchRepair, and conduct extensive experiments to validate the proposed method. The results show that our method can not only repair but also enhance accuracy & robustness, outperforming the state-of-the-art DNN repair techniques.
Improved Few-shot Segmentation by Redefinition of the Roles of Multi-level CNN Features
Sep 15, 2021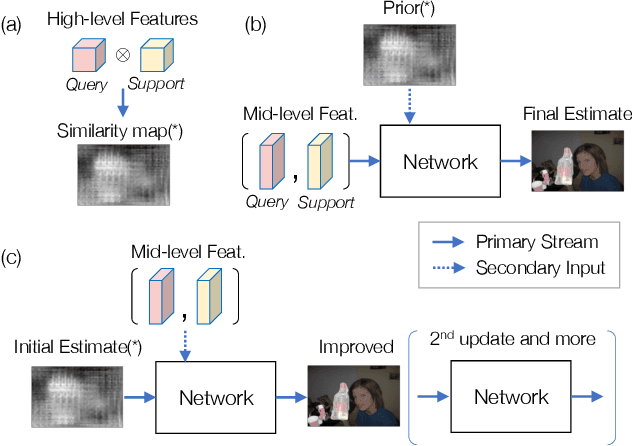

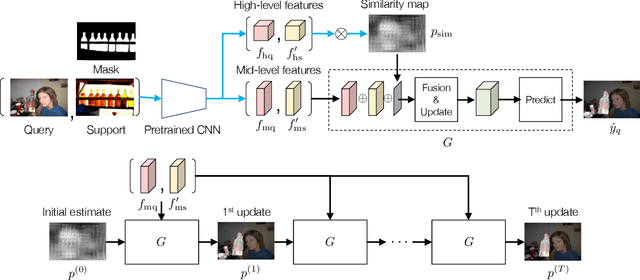
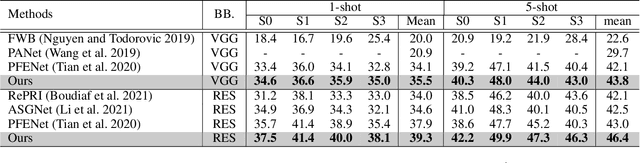
This study is concerned with few-shot segmentation, i.e., segmenting the region of an unseen object class in a query image, given support image(s) of its instances. The current methods rely on the pretrained CNN features of the support and query images. The key to good performance depends on the proper fusion of their mid-level and high-level features; the former contains shape-oriented information, while the latter has class-oriented information. Current state-of-the-art methods follow the approach of Tian et al., which gives the mid-level features the primary role and the high-level features the secondary role. In this paper, we reinterpret this widely employed approach by redifining the roles of the multi-level features; we swap the primary and secondary roles. Specifically, we regard that the current methods improve the initial estimate generated from the high-level features using the mid-level features. This reinterpretation suggests a new application of the current methods: to apply the same network multiple times to iteratively update the estimate of the object's region, starting from its initial estimate. Our experiments show that this method is effective and has updated the previous state-of-the-art on COCO-20$^i$ in the 1-shot and 5-shot settings and on PASCAL-5$^i$ in the 1-shot setting.