 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
May 12, 2026Recent large vision-language models (VLMs) remain fundamentally constrained by a persistent dichotomy: understanding and generation are treated as distinct problems, leading to fragmented architectures, cascaded pipelines, and misaligned representation spaces. We argue that this divide is not merely an engineering artifact, but a structural limitation that hinders the emergence of native multimodal intelligence. Hence, we introduce SenseNova-U1, a native unified multimodal paradigm built upon NEO-unify, in which understanding and generation evolve as synergistic views of a single underlying process. We launch two native unified variants, SenseNova-U1-8B-MoT and SenseNova-U1-A3B-MoT, built on dense (8B) and mixture-of-experts (30B-A3B) understanding baselines, respectively. Designed from first principles, they rival top-tier understanding-only VLMs across text understanding, vision-language perception, knowledge reasoning, agentic decision-making, and spatial intelligence. Meanwhile, they deliver strong semantic consistency and visual fidelity, excelling in conventional or knowledge-intensive any-to-image (X2I) synthesis, complex text-rich infographic generation, and interleaved vision-language generation, with or without think patterns. Beyond performance, we show detailed model design, data preprocessing, pre-/post-training, and inference strategies to support community research. Last but not least, preliminary evidence demonstrates that our models extend beyond perception and generation, performing strongly in vision-language-action (VLA) and world model (WM) scenarios. This points toward a broader roadmap where models do not translate between modalities, but think and act across them in a native manner. Multimodal AI is no longer about connecting separate systems, but about building a unified one and trusting the necessary capabilities to emerge from within.
Semi-supervised 3D Object Detection via Adaptive Pseudo-Labeling
Aug 15, 2021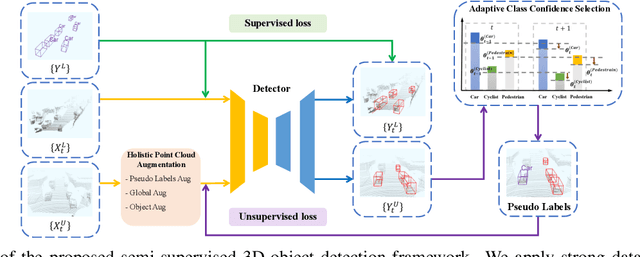
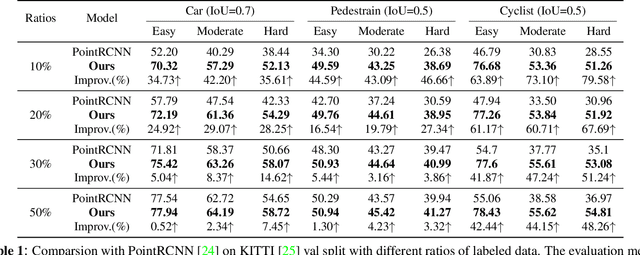
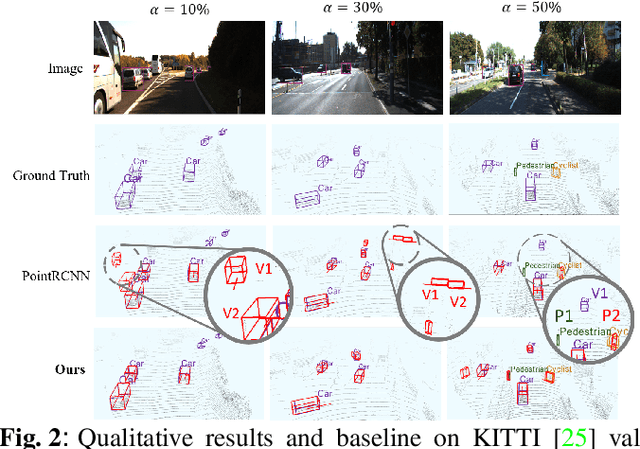
3D object detection is an important task in computer vision. Most existing methods require a large number of high-quality 3D annotations, which are expensive to collect. Especially for outdoor scenes, the problem becomes more severe due to the sparseness of the point cloud and the complexity of urban scenes. Semi-supervised learning is a promising technique to mitigate the data annotation issue. Inspired by this, we propose a novel semi-supervised framework based on pseudo-labeling for outdoor 3D object detection tasks. We design the Adaptive Class Confidence Selection module (ACCS) to generate high-quality pseudo-labels. Besides, we propose Holistic Point Cloud Augmentation (HPCA) for unlabeled data to improve robustness. Experiments on the KITTI benchmark demonstrate the effectiveness of our method.