 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniEdit: Building Image Editing Generalist Models Through Specialist Supervision
Nov 11, 2024



Instruction-guided image editing methods have demonstrated significant potential by training diffusion models on automatically synthesized or manually annotated image editing pairs. However, these methods remain far from practical, real-life applications. We identify three primary challenges contributing to this gap. Firstly, existing models have limited editing skills due to the biased synthesis process. Secondly, these methods are trained with datasets with a high volume of noise and artifacts. This is due to the application of simple filtering methods like CLIP-score. Thirdly, all these datasets are restricted to a single low resolution and fixed aspect ratio, limiting the versatility to handle real-world use cases. In this paper, we present \omniedit, which is an omnipotent editor to handle seven different image editing tasks with any aspect ratio seamlessly. Our contribution is in four folds: (1) \omniedit is trained by utilizing the supervision from seven different specialist models to ensure task coverage. (2) we utilize importance sampling based on the scores provided by large multimodal models (like GPT-4o) instead of CLIP-score to improve the data quality. (3) we propose a new editing architecture called EditNet to greatly boost the editing success rate, (4) we provide images with different aspect ratios to ensure that our model can handle any image in the wild. We have curated a test set containing images of different aspect ratios, accompanied by diverse instructions to cover different tasks. Both automatic evaluation and human evaluations demonstrate that \omniedit can significantly outperform all the existing models. Our code, dataset and model will be available at \url{https://tiger-ai-lab.github.io/OmniEdit/}
Everything Everywhere All at Once: LLMs can In-Context Learn Multiple Tasks in Superposition
Oct 08, 2024



Large Language Models (LLMs) have demonstrated remarkable in-context learning (ICL) capabilities. In this study, we explore a surprising phenomenon related to ICL: LLMs can perform multiple, computationally distinct ICL tasks simultaneously, during a single inference call, a capability we term "task superposition". We provide empirical evidence of this phenomenon across various LLM families and scales and show that this phenomenon emerges even if we train the model to in-context learn one task at a time. We offer theoretical explanations that this capability is well within the expressive power of transformers. We also explore how LLMs internally compose task vectors during superposition. Furthermore, we show that larger models can solve more ICL tasks in parallel, and better calibrate their output distribution. Our findings offer insights into the latent capabilities of LLMs, further substantiate the perspective of "LLMs as superposition of simulators", and raise questions about the mechanisms enabling simultaneous task execution.
From Artificial Needles to Real Haystacks: Improving Retrieval Capabilities in LLMs by Finetuning on Synthetic Data
Jun 27, 2024



Recent studies have shown that Large Language Models (LLMs) struggle to accurately retrieve information and maintain reasoning capabilities when processing long-context inputs. To address these limitations, we propose a finetuning approach utilizing a carefully designed synthetic dataset comprising numerical key-value retrieval tasks. Our experiments on models like GPT-3.5 Turbo and Mistral 7B demonstrate that finetuning LLMs on this dataset significantly improves LLMs' information retrieval and reasoning capabilities in longer-context settings. We present an analysis of the finetuned models, illustrating the transfer of skills from synthetic to real task evaluations (e.g., $10.5\%$ improvement on $20$ documents MDQA at position $10$ for GPT-3.5 Turbo). We also find that finetuned LLMs' performance on general benchmarks remains almost constant while LLMs finetuned on other baseline long-context augmentation data can encourage hallucination (e.g., on TriviaQA, Mistral 7B finetuned on our synthetic data cause no performance drop while other baseline data can cause a drop that ranges from $2.33\%$ to $6.19\%$). Our study highlights the potential of finetuning on synthetic data for improving the performance of LLMs on longer-context tasks.
Can Mamba Learn How to Learn? A Comparative Study on In-Context Learning Tasks
Feb 06, 2024State-space models (SSMs), such as Mamba Gu & Dao (2034), have been proposed as alternatives to Transformer networks in language modeling, by incorporating gating, convolutions, and input-dependent token selection to mitigate the quadratic cost of multi-head attention. Although SSMs exhibit competitive performance, their in-context learning (ICL) capabilities, a remarkable emergent property of modern language models that enables task execution without parameter optimization, remain underexplored compared to Transformers. In this study, we evaluate the ICL performance of SSMs, focusing on Mamba, against Transformer models across various tasks. Our results show that SSMs perform comparably to Transformers in standard regression ICL tasks, while outperforming them in tasks like sparse parity learning. However, SSMs fall short in tasks involving non-standard retrieval functionality. To address these limitations, we introduce a hybrid model, \variant, that combines Mamba with attention blocks, surpassing individual models in tasks where they struggle independently. Our findings suggest that hybrid architectures offer promising avenues for enhancing ICL in language models.
Strong Lottery Ticket Hypothesis with $\varepsilon$--perturbation
Oct 29, 2022



The strong Lottery Ticket Hypothesis (LTH) claims the existence of a subnetwork in a sufficiently large, randomly initialized neural network that approximates some target neural network without the need of training. We extend the theoretical guarantee of the strong LTH literature to a scenario more similar to the original LTH, by generalizing the weight change in the pre-training step to some perturbation around initialization. In particular, we focus on the following open questions: By allowing an $\varepsilon$-scale perturbation on the random initial weights, can we reduce the over-parameterization requirement for the candidate network in the strong LTH? Furthermore, does the weight change by SGD coincide with a good set of such perturbation? We answer the first question by first extending the theoretical result on subset sum to allow perturbation on the candidates. Applying this result to the neural network setting, we show that such $\varepsilon$-perturbation reduces the over-parameterization requirement of the strong LTH. To answer the second question, we show via experiments that the perturbed weight achieved by the projected SGD shows better performance under the strong LTH pruning.
Frame Difference-Based Temporal Loss for Video Stylization
Feb 11, 2021
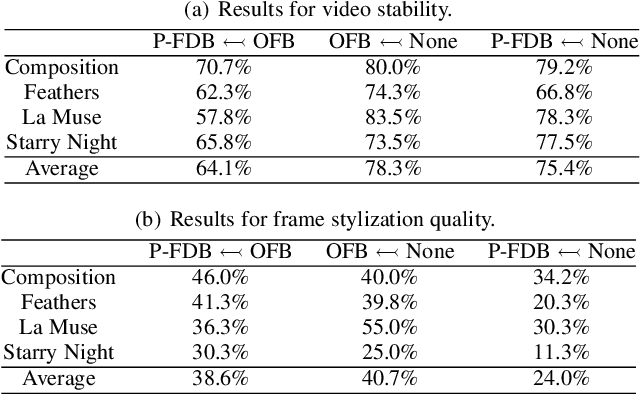
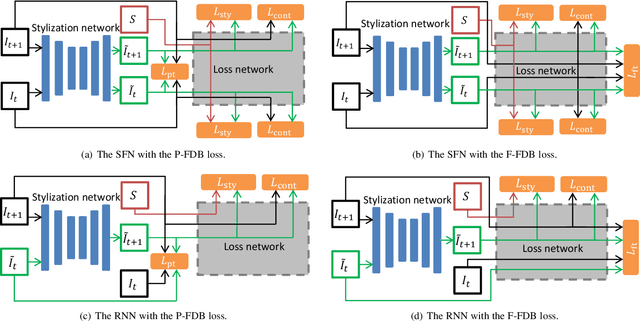
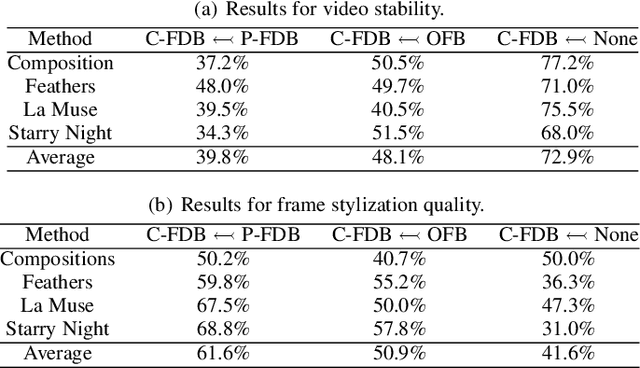
Neural style transfer models have been used to stylize an ordinary video to specific styles. To ensure temporal inconsistency between the frames of the stylized video, a common approach is to estimate the optic flow of the pixels in the original video and make the generated pixels match the estimated optical flow. This is achieved by minimizing an optical flow-based (OFB) loss during model training. However, optical flow estimation is itself a challenging task, particularly in complex scenes. In addition, it incurs a high computational cost. We propose a much simpler temporal loss called the frame difference-based (FDB) loss to solve the temporal inconsistency problem. It is defined as the distance between the difference between the stylized frames and the difference between the original frames. The differences between the two frames are measured in both the pixel space and the feature space specified by the convolutional neural networks. A set of human behavior experiments involving 62 subjects with 25,600 votes showed that the performance of the proposed FDB loss matched that of the OFB loss. The performance was measured by subjective evaluation of stability and stylization quality of the generated videos on two typical video stylization models. The results suggest that the proposed FDB loss is a strong alternative to the commonly used OFB loss for video stylization.