 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Risk Minimization
May 09, 2021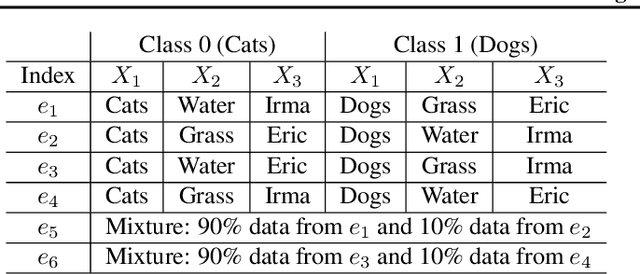

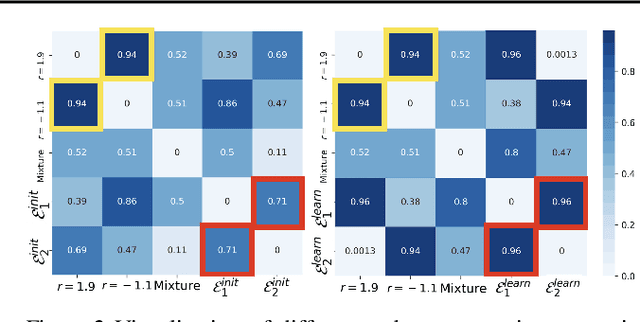
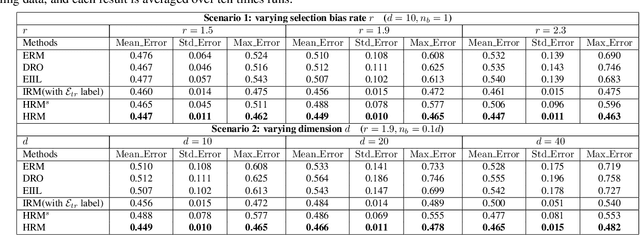
Machine learning algorithms with empirical risk minimization usually suffer from poor generalization performance due to the greedy exploitation of correlations among the training data, which are not stable under distributional shifts. Recently, some invariant learning methods for out-of-distribution (OOD) generalization have been proposed by leveraging multiple training environments to find invariant relationships. However, modern datasets are frequently assembled by merging data from multiple sources without explicit source labels. The resultant unobserved heterogeneity renders many invariant learning methods inapplicable. In this paper, we propose Heterogeneous Risk Minimization (HRM) framework to achieve joint learning of latent heterogeneity among the data and invariant relationship, which leads to stable prediction despite distributional shifts. We theoretically characterize the roles of the environment labels in invariant learning and justify our newly proposed HRM framework. Extensive experimental results validate the effectiveness of our HRM framework.
Deep Stable Learning for Out-Of-Distribution Generalization
Apr 16, 2021
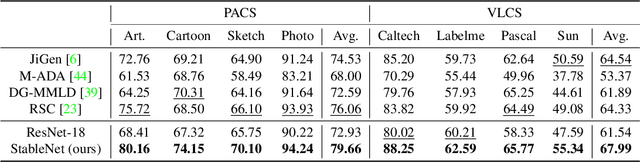
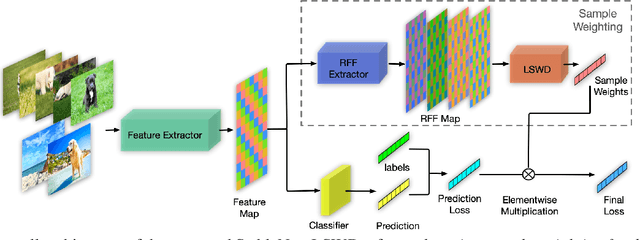
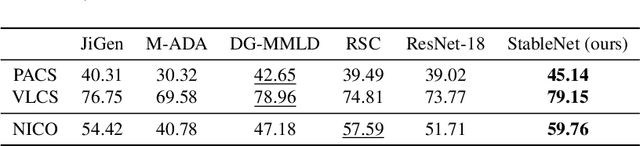
Approaches based on deep neural networks have achieved striking performance when testing data and training data share similar distribution, but can significantly fail otherwise. Therefore, eliminating the impact of distribution shifts between training and testing data is crucial for building performance-promising deep models. Conventional methods assume either the known heterogeneity of training data (e.g. domain labels) or the approximately equal capacities of different domains. In this paper, we consider a more challenging case where neither of the above assumptions holds. We propose to address this problem by removing the dependencies between features via learning weights for training samples, which helps deep models get rid of spurious correlations and, in turn, concentrate more on the true connection between discriminative features and labels. Extensive experiments clearly demonstrate the effectiveness of our method on multiple distribution generalization benchmarks compared with state-of-the-art counterparts. Through extensive experiments on distribution generalization benchmarks including PACS, VLCS, MNIST-M, and NICO, we show the effectiveness of our method compared with state-of-the-art counterparts.
Algorithmic Decision Making with Conditional Fairness
Jul 14, 2020
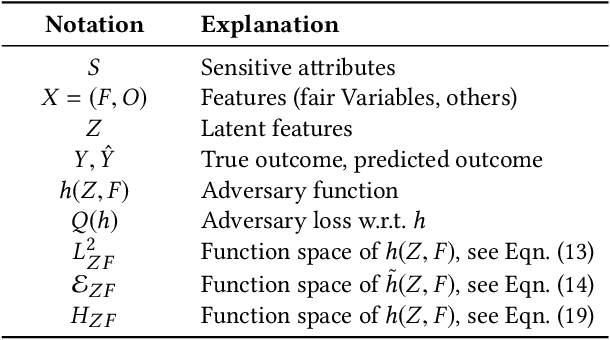
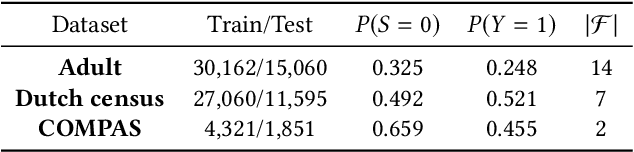
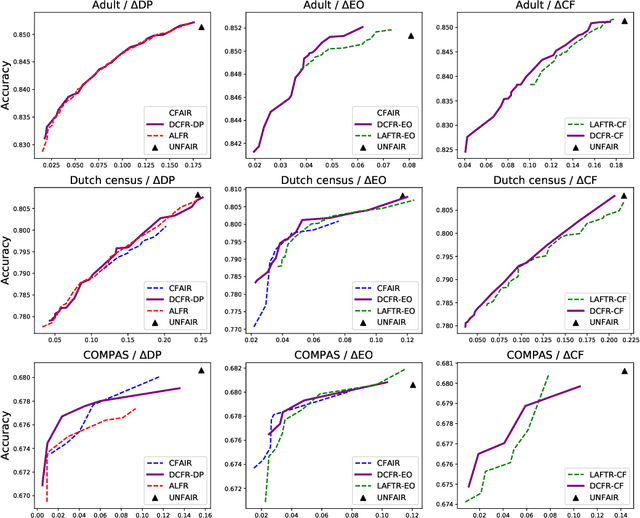
Nowadays fairness issues have raised great concerns in decision-making systems. Various fairness notions have been proposed to measure the degree to which an algorithm is unfair. In practice, there frequently exist a certain set of variables we term as fair variables, which are pre-decision covariates such as users' choices. The effects of fair variables are irrelevant in assessing the fairness of the decision support algorithm. We thus define conditional fairness as a more sound fairness metric by conditioning on the fairness variables. Given different prior knowledge of fair variables, we demonstrate that traditional fairness notations, such as demographic parity and equalized odds, are special cases of our conditional fairness notations. Moreover, we propose a Derivable Conditional Fairness Regularizer (DCFR), which can be integrated into any decision-making model, to track the trade-off between precision and fairness of algorithmic decision making. Specifically, an adversarial representation based conditional independence loss is proposed in our DCFR to measure the degree of unfairness. With extensive experiments on three real-world datasets, we demonstrate the advantages of our conditional fairness notation and DCFR.
Invariant Adversarial Learning for Distributional Robustness
Jun 08, 2020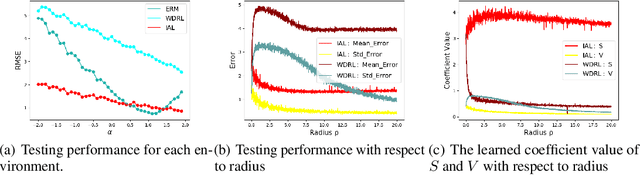
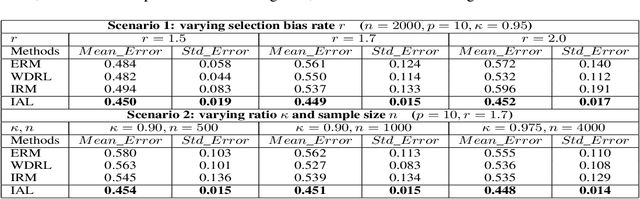
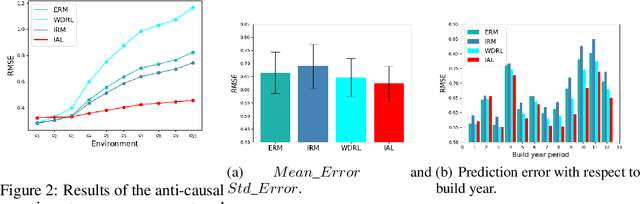
Machine learning algorithms with empirical risk minimization are vulnerable to distributional shifts due to the greedy adoption of all the correlations found in training data. Recently, there are robust learning methods aiming at this problem by minimizing the worst-case risk over an uncertainty set. However, they equally treat all covariates to form the uncertainty sets regardless of the stability of their correlations with the target, resulting in the overwhelmingly large set and low confidence of the learner. In this paper, we propose the Invariant Adversarial Learning (IAL) algorithm that leverages heterogeneous data sources to construct a more practical uncertainty set and conduct robustness optimization, where covariates are differentiated according to the stability of their correlations with the target. We theoretically show that our method is tractable for stochastic gradient-based optimization and provide the performance guarantees for our method. Empirical studies on both simulation and real datasets validate the effectiveness of our method in terms of robust performance across unknown distributional shifts.
Stable Learning via Sample Reweighting
Nov 28, 2019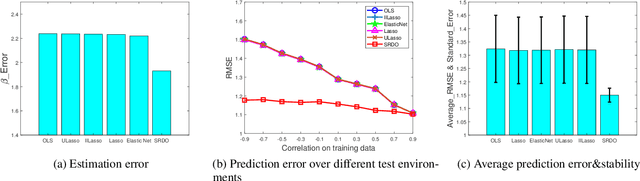
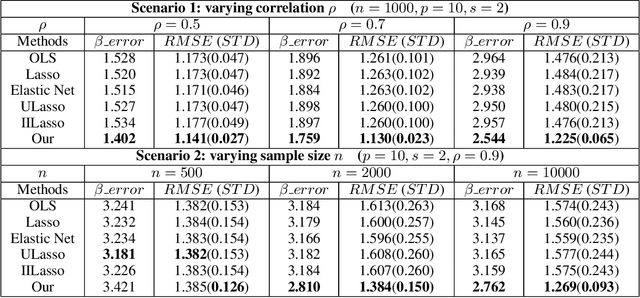
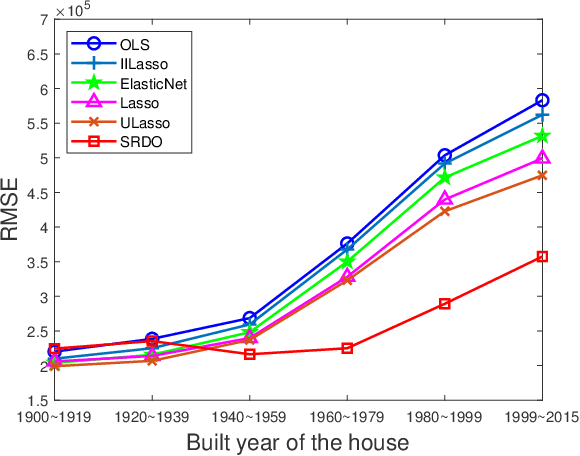
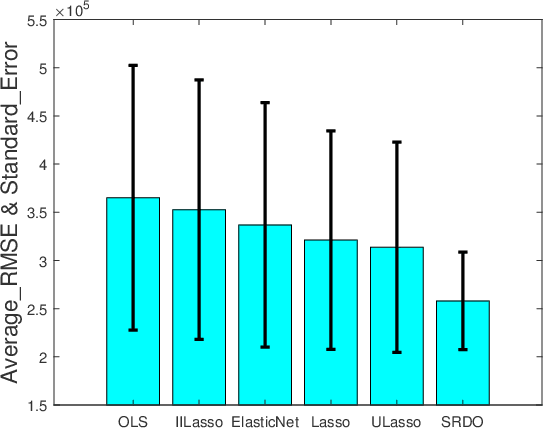
We consider the problem of learning linear prediction models with model misspecification bias. In such case, the collinearity among input variables may inflate the error of parameter estimation, resulting in instability of prediction results when training and test distributions do not match. In this paper we theoretically analyze this fundamental problem and propose a sample reweighting method that reduces collinearity among input variables. Our method can be seen as a pretreatment of data to improve the condition of design matrix, and it can then be combined with any standard learning method for parameter estimation and variable selection. Empirical studies on both simulation and real datasets demonstrate the effectiveness of our method in terms of more stable performance across different distributed data.
NICO: A Dataset Towards Non-I.I.D. Image Classification
Jul 01, 2019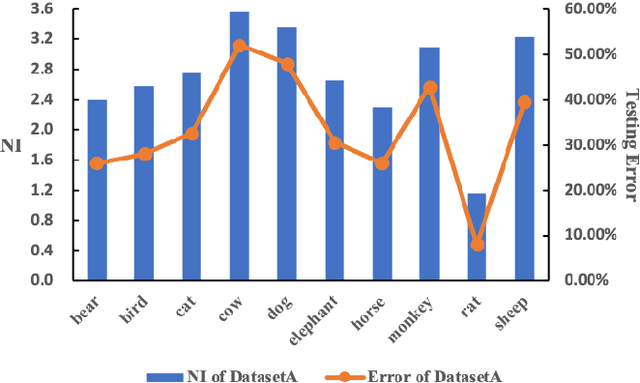
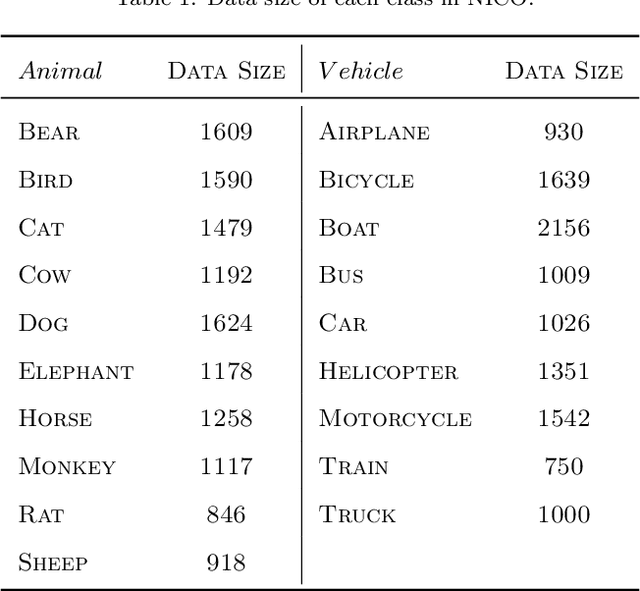
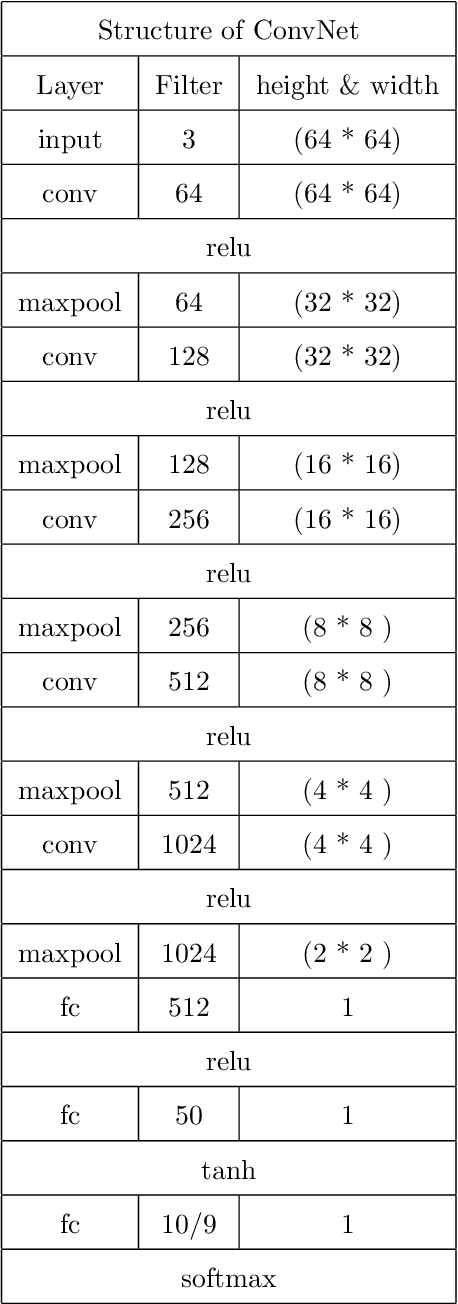
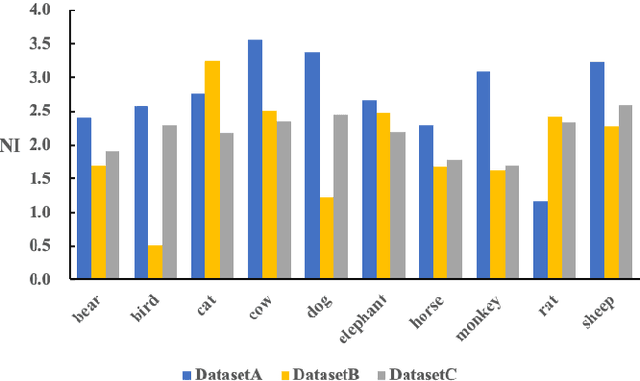
The I.I.D. hypothesis between training data and testing data is the basis of a large number of image classification methods. Such a property can hardly be guaranteed in practical cases where the Non-IIDness is common, leading to instable performances of these models. In literature, however, the Non-I.I.D. image classification problem is largely understudied. A key reason is the lacking of a well-designed dataset to support related research. In this paper, we construct and release a Non-I.I.D. image dataset called NICO, which makes use of contexts to create Non-IIDness consciously. Extended experimental results and anslyses demonstrate that the NICO dataset can well support the training of a ConvNet model from scratch, and NICO can support various Non-I.I.D. situations with sufficient flexibility compared to other datasets.
Causally Regularized Learning with Agnostic Data Selection Bias
Aug 19, 2018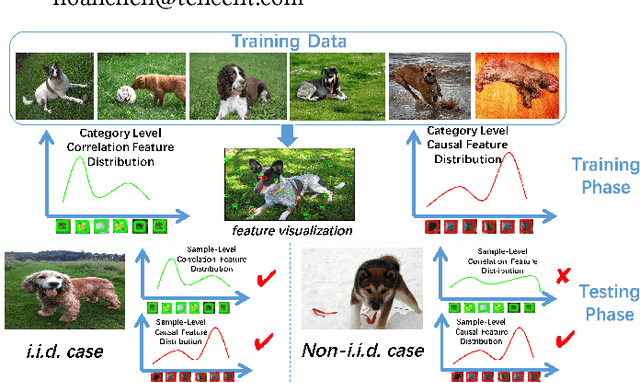
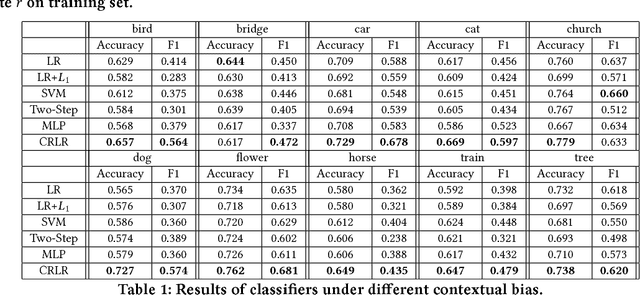
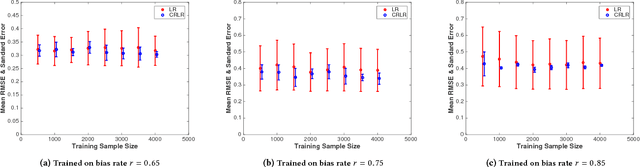
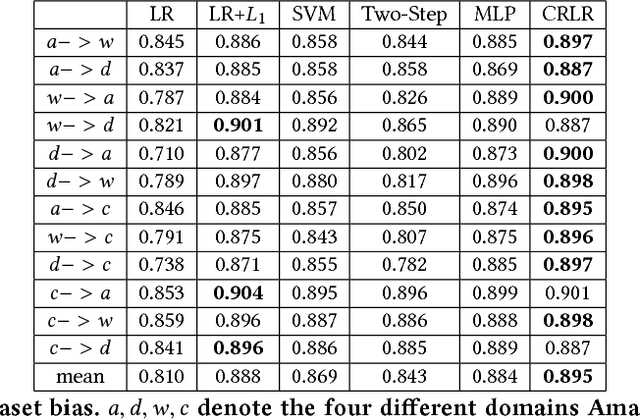
Most of previous machine learning algorithms are proposed based on the i.i.d. hypothesis. However, this ideal assumption is often violated in real applications, where selection bias may arise between training and testing process. Moreover, in many scenarios, the testing data is not even available during the training process, which makes the traditional methods like transfer learning infeasible due to their need on prior of test distribution. Therefore, how to address the agnostic selection bias for robust model learning is of paramount importance for both academic research and real applications. In this paper, under the assumption that causal relationships among variables are robust across domains, we incorporate causal technique into predictive modeling and propose a novel Causally Regularized Logistic Regression (CRLR) algorithm by jointly optimize global confounder balancing and weighted logistic regression. Global confounder balancing helps to identify causal features, whose causal effect on outcome are stable across domains, then performing logistic regression on those causal features constructs a robust predictive model against the agnostic bias. To validate the effectiveness of our CRLR algorithm, we conduct comprehensive experiments on both synthetic and real world datasets. Experimental results clearly demonstrate that our CRLR algorithm outperforms the state-of-the-art methods, and the interpretability of our method can be fully depicted by the feature visualization.