 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel regression in high dimension: Refined analysis beyond double descent
Oct 06, 2020
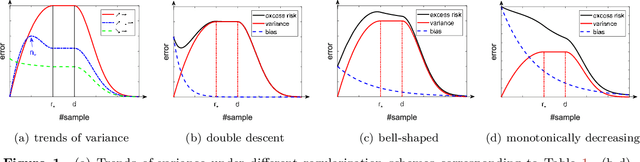


In this paper, we provide a precise characterize of generalization properties of high dimensional kernel ridge regression across the under- and over-parameterized regimes, depending on whether the number of training data $n$ exceeds the feature dimension $d$. By establishing a novel bias-variance decomposition of the expected excess risk, we show that, while the bias is independent of $d$ and monotonically decreases with $n$, the variance depends on $n,d$ and can be unimodal or monotonically decreasing under different regularization schemes. Our refined analysis goes beyond the double descent theory by showing that, depending on the data eigen-profile and the level of regularization, the kernel regression risk curve can be a double-descent-like, bell-shaped, or monotonic function of $n$. Experiments on synthetic and real data are conducted to support our theoretical findings.
Sparse Quantized Spectral Clustering
Oct 03, 2020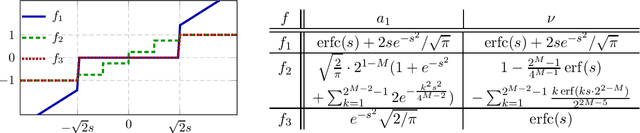

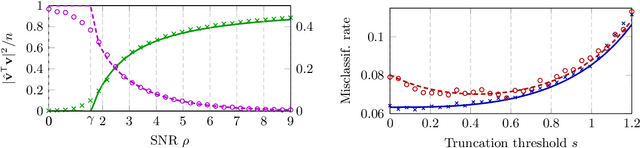
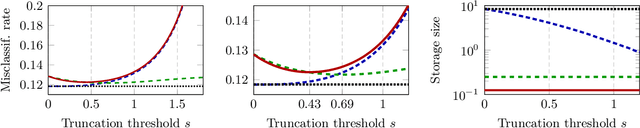
Given a large data matrix, sparsifying, quantizing, and/or performing other entry-wise nonlinear operations can have numerous benefits, ranging from speeding up iterative algorithms for core numerical linear algebra problems to providing nonlinear filters to design state-of-the-art neural network models. Here, we exploit tools from random matrix theory to make precise statements about how the eigenspectrum of a matrix changes under such nonlinear transformations. In particular, we show that very little change occurs in the informative eigenstructure even under drastic sparsification/quantization, and consequently that very little downstream performance loss occurs with very aggressively sparsified or quantized spectral clustering. We illustrate how these results depend on the nonlinearity, we characterize a phase transition beyond which spectral clustering becomes possible, and we show when such nonlinear transformations can introduce spurious non-informative eigenvectors.
Precise expressions for random projections: Low-rank approximation and randomized Newton
Jun 18, 2020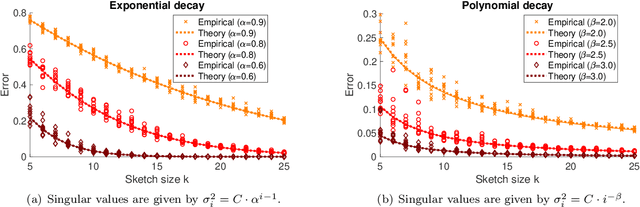
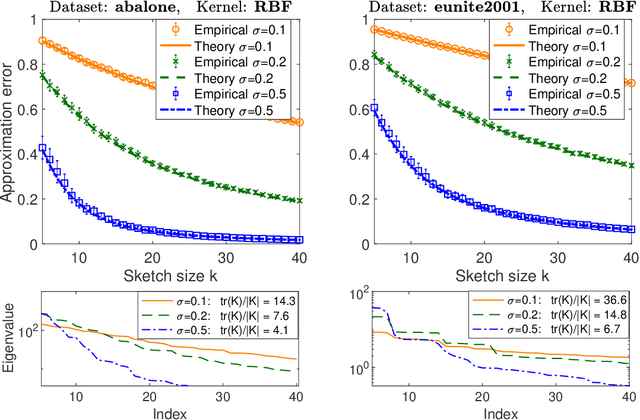
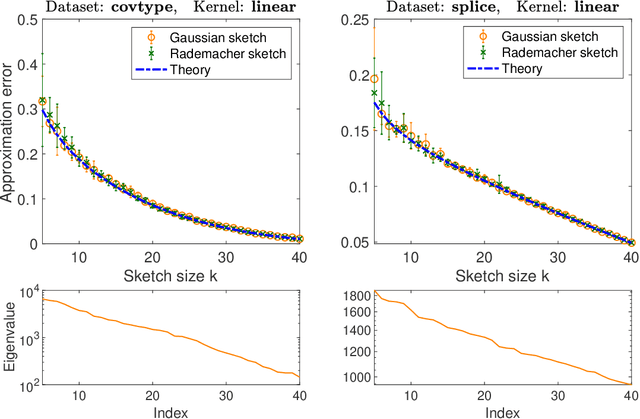
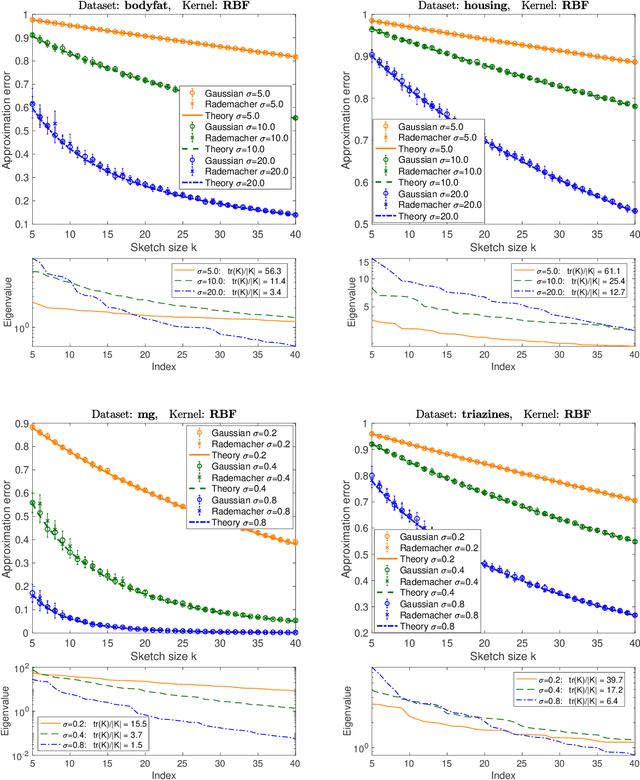
It is often desirable to reduce the dimensionality of a large dataset by projecting it onto a low-dimensional subspace. Matrix sketching has emerged as a powerful technique for performing such dimensionality reduction very efficiently. Even though there is an extensive literature on the worst-case performance of sketching, existing guarantees are typically very different from what is observed in practice. We exploit recent developments in the spectral analysis of random matrices to develop novel techniques that provide provably accurate expressions for the expected value of random projection matrices obtained via sketching. These expressions can be used to characterize the performance of dimensionality reduction in a variety of common machine learning tasks, ranging from low-rank approximation to iterative stochastic optimization. Our results apply to several popular sketching methods, including Gaussian and Rademacher sketches, and they enable precise analysis of these methods in terms of spectral properties of the data. Empirical results show that the expressions we derive reflect the practical performance of these sketching methods, down to lower-order effects and even constant factors.
A random matrix analysis of random Fourier features: beyond the Gaussian kernel, a precise phase transition, and the corresponding double descent
Jun 09, 2020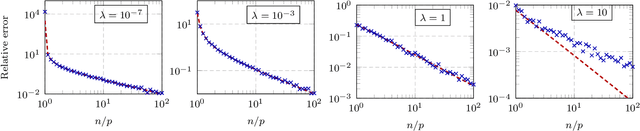
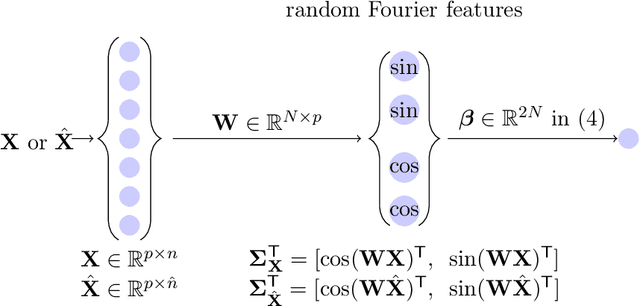
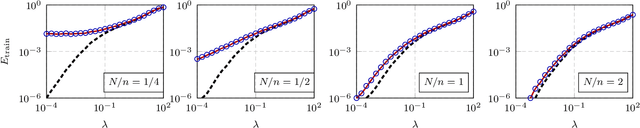
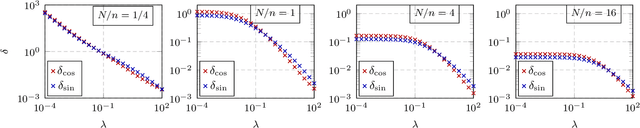
This article characterizes the exact asymptotics of random Fourier feature (RFF) regression, in the realistic setting where the number of data samples $n$, their dimension $p$, and the dimension of feature space $N$ are all large and comparable. In this regime, the random RFF Gram matrix no longer converges to the well-known limiting Gaussian kernel matrix (as it does when $N \to \infty$ alone), but it still has a tractable behavior that is captured by our analysis. This analysis also provides accurate estimates of training and test regression errors for large $n,p,N$. Based on these estimates, a precise characterization of two qualitatively different phases of learning, including the phase transition between them, is provided; and the corresponding double descent test error curve is derived from this phase transition behavior. These results do not depend on strong assumptions on the data distribution, and they perfectly match empirical results on finite-dimensional real-world data sets.
Towards Efficient Training for Neural Network Quantization
Dec 21, 2019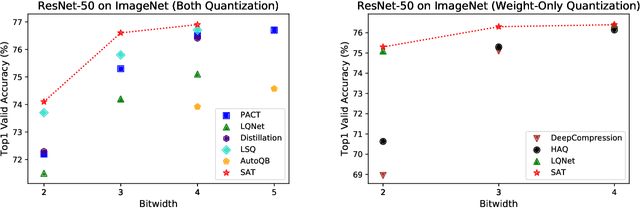
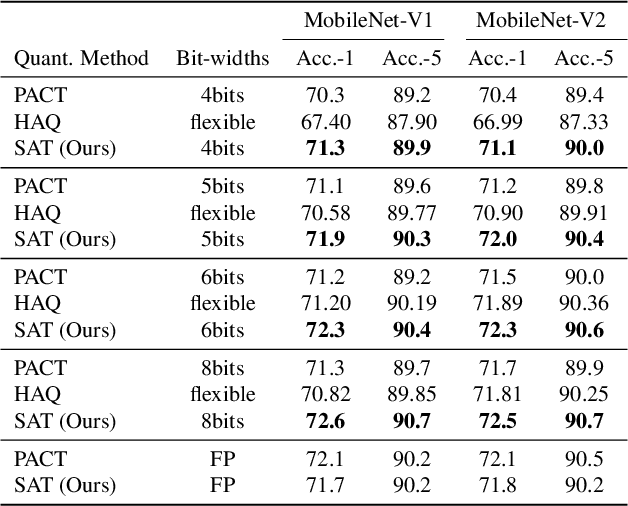
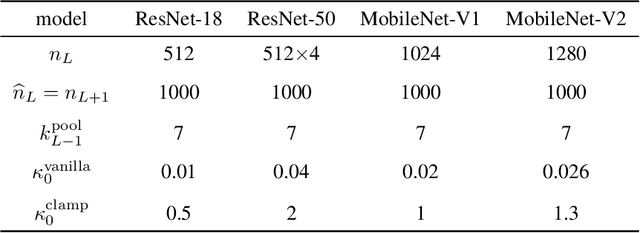
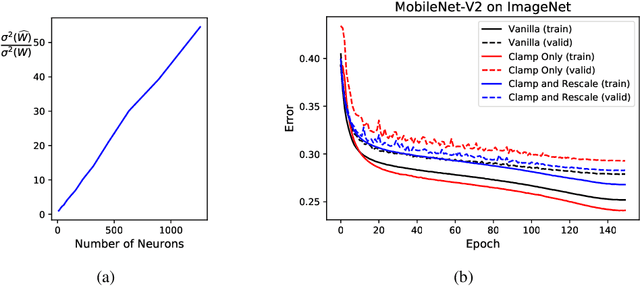
Quantization reduces computation costs of neural networks but suffers from performance degeneration. Is this accuracy drop due to the reduced capacity, or inefficient training during the quantization procedure? After looking into the gradient propagation process of neural networks by viewing the weights and intermediate activations as random variables, we discover two critical rules for efficient training. Recent quantization approaches violates the two rules and results in degenerated convergence. To deal with this problem, we propose a simple yet effective technique, named scale-adjusted training (SAT), to comply with the discovered rules and facilitates efficient training. We also analyze the quantization error introduced in calculating the gradient in the popular parameterized clipping activation (PACT) technique. Through SAT together with gradient-calibrated PACT, quantized models obtain comparable or even better performance than their full-precision counterparts, achieving state-of-the-art accuracy with consistent improvement over previous quantization methods on a wide spectrum of models including MobileNet-V1/V2 and PreResNet-50.
AdaBits: Neural Network Quantization with Adaptive Bit-Widths
Dec 20, 2019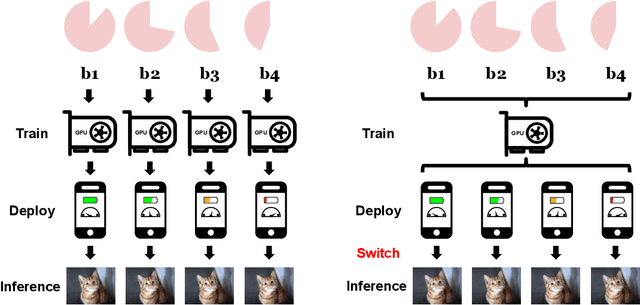
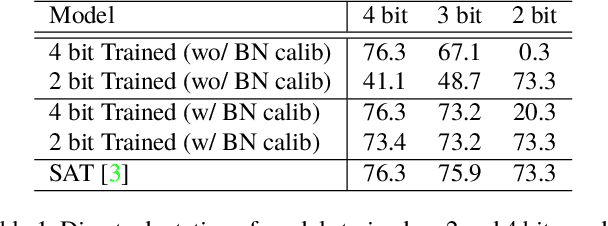
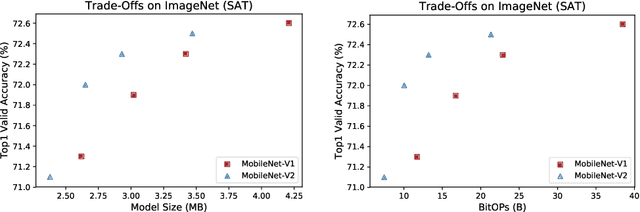
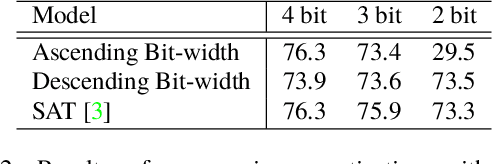
Deep neural networks with adaptive configurations have gained increasing attention due to the instant and flexible deployment of these models on platforms with different resource budgets. In this paper, we investigate a novel option to achieve this goal by enabling adaptive bit-widths of weights and activations in the model. We first examine the benefits and challenges of training quantized model with adaptive bit-widths, and then experiment with several approaches including direct adaptation, progressive training and joint training. We discover that joint training is able to produce comparable performance on the adaptive model as individual models. We further propose a new technique named Switchable Clipping Level (S-CL) to further improve quantized models at the lowest bit-width. With our proposed techniques applied on a bunch of models including MobileNet-V1/V2 and ResNet-50, we demonstrate that bit-width of weights and activations is a new option for adaptively executable deep neural networks, offering a distinct opportunity for improved accuracy-efficiency trade-off as well as instant adaptation according to the platform constraints in real-world applications.
Inner-product Kernels are Asymptotically Equivalent to Binary Discrete Kernels
Sep 15, 2019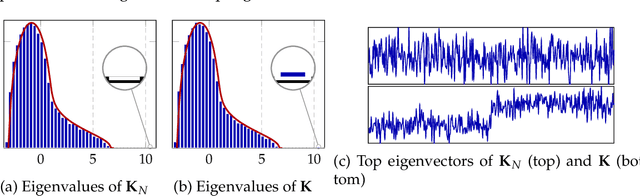
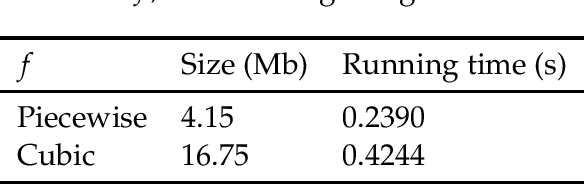
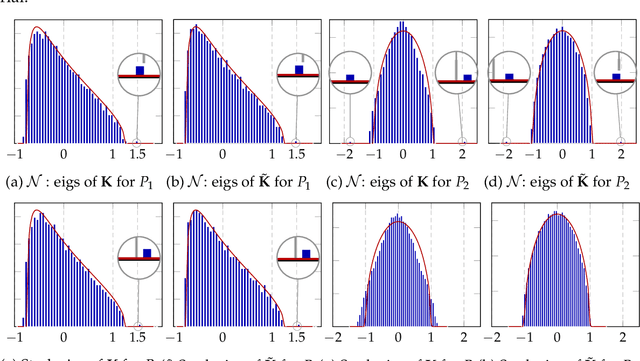
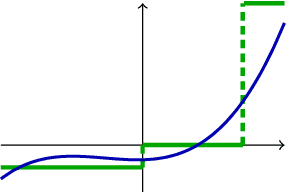
This article investigates the eigenspectrum of the inner product-type kernel matrix $\sqrt{p} \mathbf{K}=\{f( \mathbf{x}_i^{\sf T} \mathbf{x}_j/\sqrt{p})\}_{i,j=1}^n $ under a binary mixture model in the high dimensional regime where the number of data $n$ and their dimension $p$ are both large and comparable. Based on recent advances in random matrix theory, we show that, for a wide range of nonlinear functions $f$, the eigenspectrum behavior is asymptotically equivalent to that of an (at most) cubic function. This sheds new light on the understanding of nonlinearity in large dimensional problems. As a byproduct, we propose a simple function prototype valued in $ (-1,0,1) $ that, while reducing both storage memory and running time, achieves the same (asymptotic) classification performance as any arbitrary function $f$.
Complete Dictionary Learning via $\ell^4$-Norm Maximization over the Orthogonal Group
Jul 10, 2019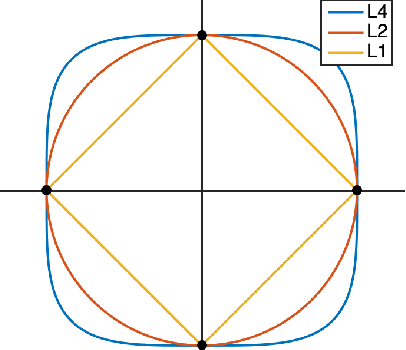
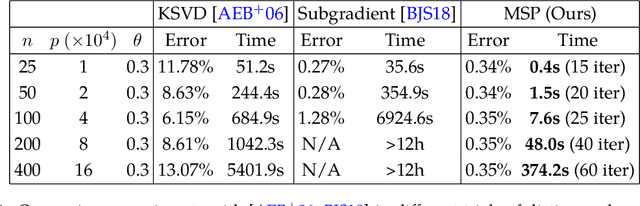
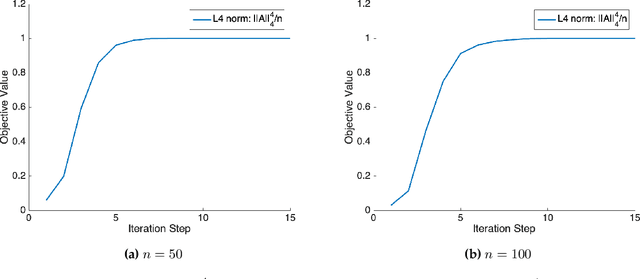
This paper considers the fundamental problem of learning a complete (orthogonal) dictionary from samples of sparsely generated signals. Most existing methods solve the dictionary (and sparse representations) based on heuristic algorithms, usually without theoretical guarantees for either optimality or complexity. The recent $\ell^1$-minimization based methods do provide such guarantees but the associated algorithms recover the dictionary one column at a time. In this work, we propose a new formulation that maximizes the $\ell^4$-norm over the orthogonal group, to learn the entire dictionary. We prove that under a random data model, with nearly minimum sample complexity, the global optima of the $\ell^4$ norm are very close to signed permutations of the ground truth. Inspired by this observation, we give a conceptually simple and yet effective algorithm based on "matching, stretching, and projection" (MSP). The algorithm provably converges locally at a superlinear (cubic) rate and cost per iteration is merely an SVD. In addition to strong theoretical guarantees, experiments show that the new algorithm is significantly more efficient and effective than existing methods, including KSVD and $\ell^1$-based methods. Preliminary experimental results on mixed real imagery data clearly demonstrate advantages of so learned dictionary over classic PCA bases.
High Dimensional Classification via Empirical Risk Minimization: Improvements and Optimality
May 31, 2019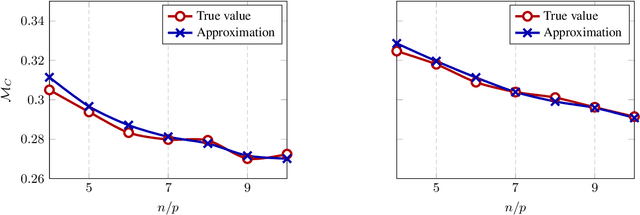
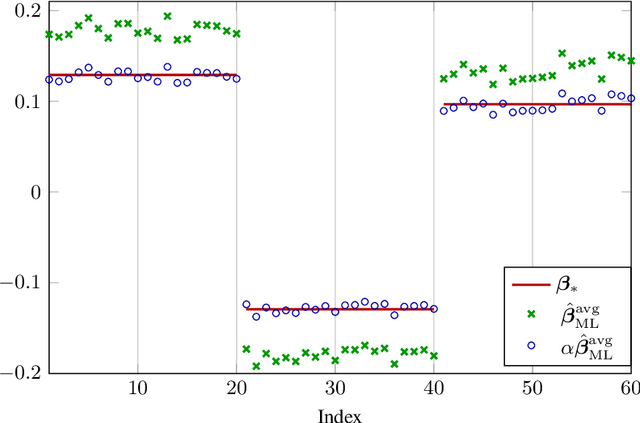
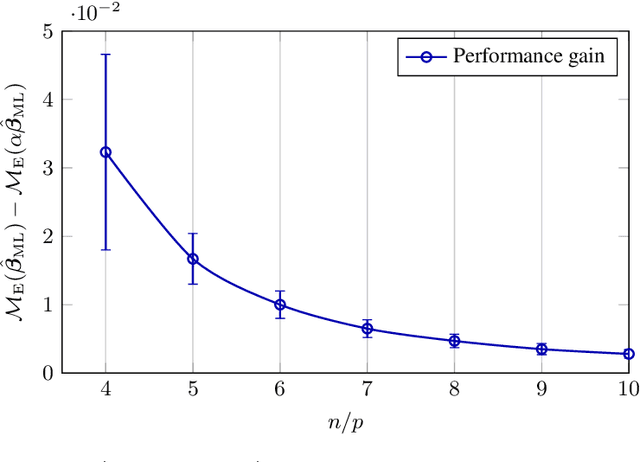
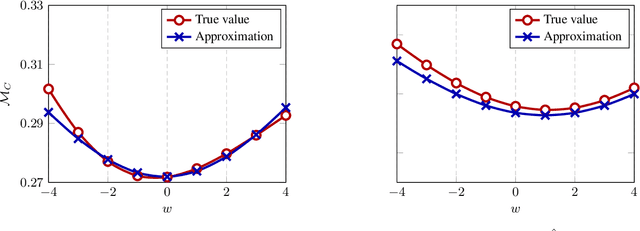
In this article, we investigate a family of classification algorithms defined by the principle of empirical risk minimization, in the high dimensional regime where the feature dimension $p$ and data number $n$ are both large and comparable. Based on recent advances in high dimensional statistics and random matrix theory, we provide under mixture data model a unified stochastic characterization of classifiers learned with different loss functions. Our results are instrumental to an in-depth understanding as well as practical improvements on this fundamental classification approach. As the main outcome, we demonstrate the existence of a universally optimal loss function which yields the best high dimensional performance at any given $n/p$ ratio.
Regional Homogeneity: Towards Learning Transferable Universal Adversarial Perturbations Against Defenses
Apr 01, 2019

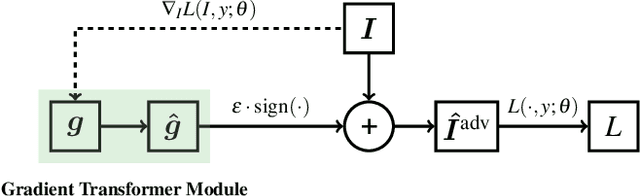
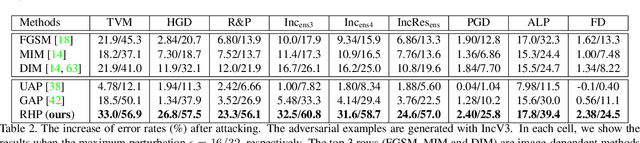
This paper focuses on learning transferable adversarial examples specifically against defense models (models to defense adversarial attacks). In particular, we show that a simple universal perturbation can fool a series of state-of-the-art defenses. Adversarial examples generated by existing attacks are generally hard to transfer to defense models. We observe the property of regional homogeneity in adversarial perturbations and suggest that the defenses are less robust to regionally homogeneous perturbations. Therefore, we propose an effective transforming paradigm and a customized gradient transformer module to transform existing perturbations into regionally homogeneous ones. Without explicitly forcing the perturbations to be universal, we observe that a well-trained gradient transformer module tends to output input-independent gradients (hence universal) benefiting from the under-fitting phenomenon. Thorough experiments demonstrate that our work significantly outperforms the prior art attacking algorithms (either image-dependent or universal ones) by an average improvement of 14.0% when attacking 9 defenses in the black-box setting. In addition to the cross-model transferability, we also verify that regionally homogeneous perturbations can well transfer across different vision tasks (attacking with the semantic segmentation task and testing on the object detection task).