 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaP-AVR: A Meta-Action Planner for Agents Leveraging Vision Language Models and Retrieval-Augmented Generation
Dec 22, 2025Embodied robotic AI systems designed to manage complex daily tasks rely on a task planner to understand and decompose high-level tasks. While most research focuses on enhancing the task-understanding abilities of LLMs/VLMs through fine-tuning or chain-of-thought prompting, this paper argues that defining the planned skill set is equally crucial. To handle the complexity of daily environments, the skill set should possess a high degree of generalization ability. Empirically, more abstract expressions tend to be more generalizable. Therefore, we propose to abstract the planned result as a set of meta-actions. Each meta-action comprises three components: {move/rotate, end-effector status change, relationship with the environment}. This abstraction replaces human-centric concepts, such as grasping or pushing, with the robot's intrinsic functionalities. As a result, the planned outcomes align seamlessly with the complete range of actions that the robot is capable of performing. Furthermore, to ensure that the LLM/VLM accurately produces the desired meta-action format, we employ the Retrieval-Augmented Generation (RAG) technique, which leverages a database of human-annotated planning demonstrations to facilitate in-context learning. As the system successfully completes more tasks, the database will self-augment to continue supporting diversity. The meta-action set and its integration with RAG are two novel contributions of our planner, denoted as MaP-AVR, the meta-action planner for agents composed of VLM and RAG. To validate its efficacy, we design experiments using GPT-4o as the pre-trained LLM/VLM model and OmniGibson as our robotic platform. Our approach demonstrates promising performance compared to the current state-of-the-art method. Project page: https://map-avr.github.io/.
DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection
Apr 12, 2022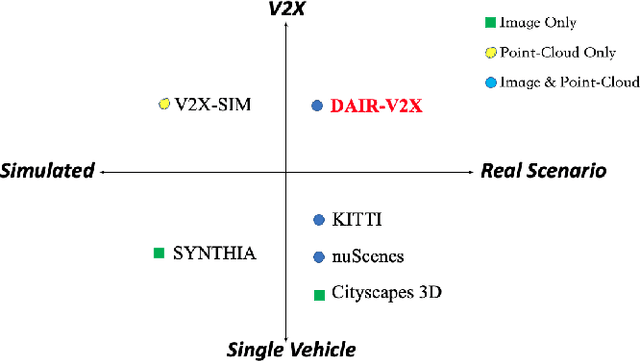
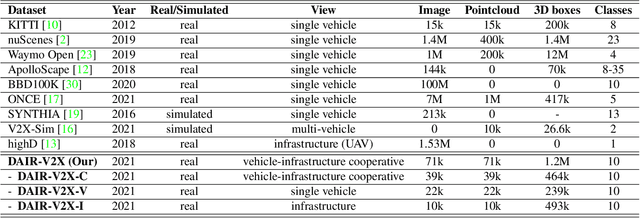
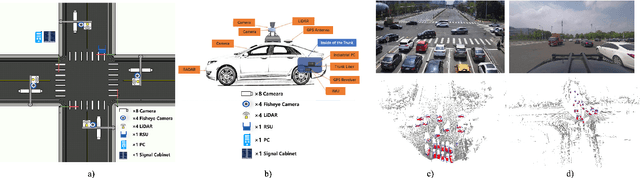
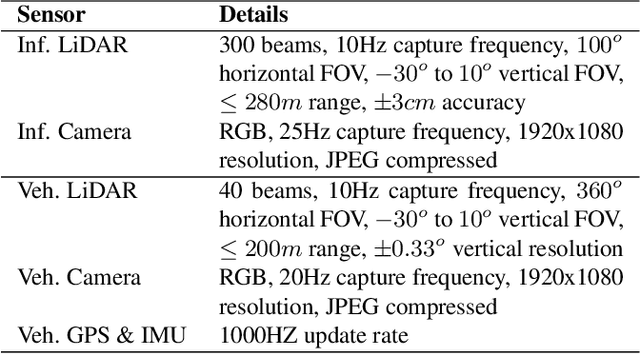
Autonomous driving faces great safety challenges for a lack of global perspective and the limitation of long-range perception capabilities. It has been widely agreed that vehicle-infrastructure cooperation is required to achieve Level 5 autonomy. However, there is still NO dataset from real scenarios available for computer vision researchers to work on vehicle-infrastructure cooperation-related problems. To accelerate computer vision research and innovation for Vehicle-Infrastructure Cooperative Autonomous Driving (VICAD), we release DAIR-V2X Dataset, which is the first large-scale, multi-modality, multi-view dataset from real scenarios for VICAD. DAIR-V2X comprises 71254 LiDAR frames and 71254 Camera frames, and all frames are captured from real scenes with 3D annotations. The Vehicle-Infrastructure Cooperative 3D Object Detection problem (VIC3D) is introduced, formulating the problem of collaboratively locating and identifying 3D objects using sensory inputs from both vehicle and infrastructure. In addition to solving traditional 3D object detection problems, the solution of VIC3D needs to consider the temporal asynchrony problem between vehicle and infrastructure sensors and the data transmission cost between them. Furthermore, we propose Time Compensation Late Fusion (TCLF), a late fusion framework for the VIC3D task as a benchmark based on DAIR-V2X. Find data, code, and more up-to-date information at https://thudair.baai.ac.cn/index and https://github.com/AIR-THU/DAIR-V2X.