 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAspect-Based Sentiment Analysis using Local Context Focus Mechanism with DeBERTa
Jul 07, 2022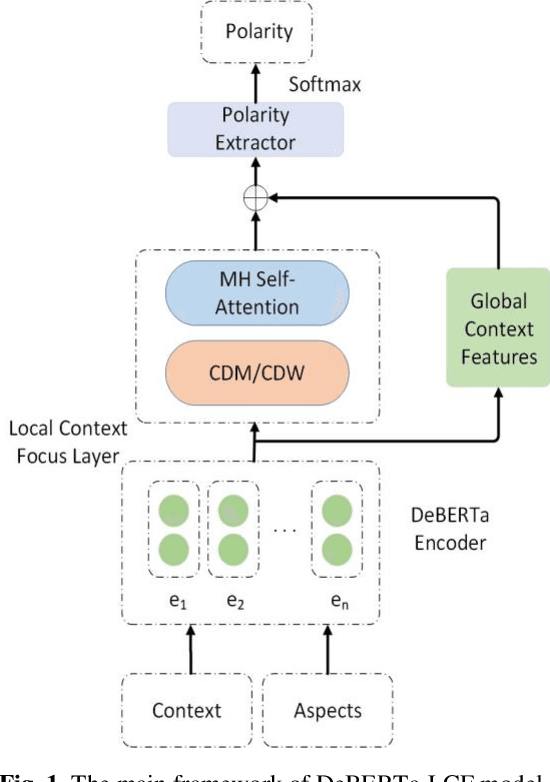

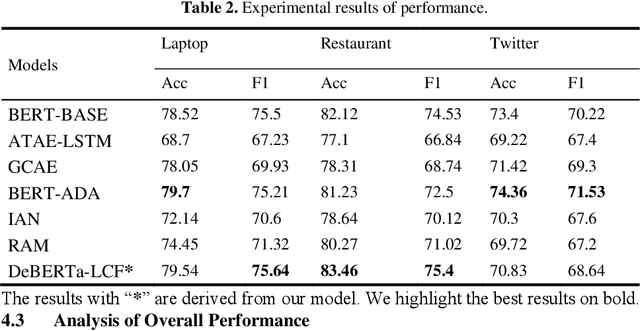
Text sentiment analysis, also known as opinion mining, is research on the calculation of people's views, evaluations, attitude and emotions expressed by entities. Text sentiment analysis can be divided into text-level sentiment analysis, sen-tence-level sentiment analysis and aspect-level sentiment analysis. Aspect-Based Sentiment Analysis (ABSA) is a fine-grained task in the field of sentiment analysis, which aims to predict the polarity of aspects. The research of pre-training neural model has significantly improved the performance of many natural language processing tasks. In recent years, pre training model (PTM) has been applied in ABSA. Therefore, there has been a question, which is whether PTMs contain sufficient syntactic information for ABSA. In this paper, we explored the recent DeBERTa model (Decoding-enhanced BERT with disentangled attention) to solve Aspect-Based Sentiment Analysis problem. DeBERTa is a kind of neural language model based on transformer, which uses self-supervised learning to pre-train on a large number of original text corpora. Based on the Local Context Focus (LCF) mechanism, by integrating DeBERTa model, we purpose a multi-task learning model for aspect-based sentiment analysis. The experiments result on the most commonly used the laptop and restaurant datasets of SemEval-2014 and the ACL twitter dataset show that LCF mechanism with DeBERTa has significant improvement.
Chinese Word Sense Embedding with SememeWSD and Synonym Set
Jun 29, 2022
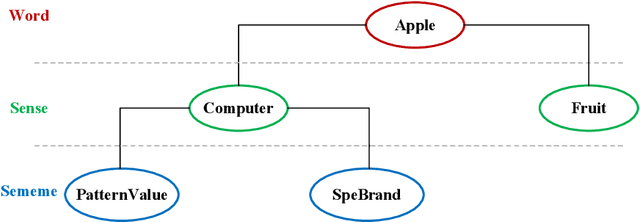

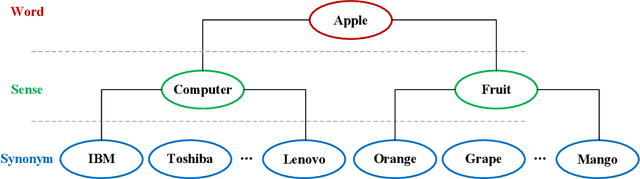
Word embedding is a fundamental natural language processing task which can learn feature of words. However, most word embedding methods assign only one vector to a word, even if polysemous words have multi-senses. To address this limitation, we propose SememeWSD Synonym (SWSDS) model to assign a different vector to every sense of polysemous words with the help of word sense disambiguation (WSD) and synonym set in OpenHowNet. We use the SememeWSD model, an unsupervised word sense disambiguation model based on OpenHowNet, to do word sense disambiguation and annotate the polysemous word with sense id. Then, we obtain top 10 synonyms of the word sense from OpenHowNet and calculate the average vector of synonyms as the vector of the word sense. In experiments, We evaluate the SWSDS model on semantic similarity calculation with Gensim's wmdistance method. It achieves improvement of accuracy. We also examine the SememeWSD model on different BERT models to find the more effective model.
Bi-convolution matrix factorization algorithm based on improved ConvMF
Jun 02, 2022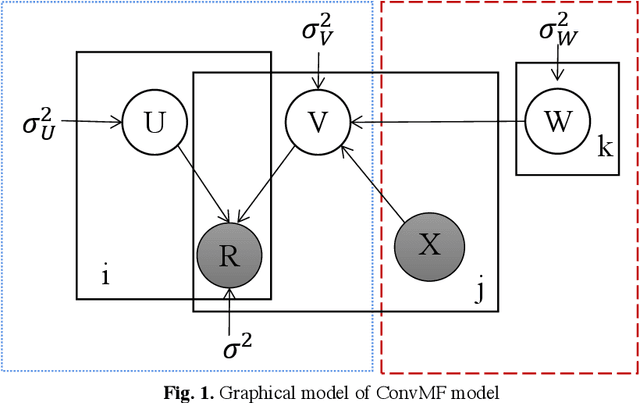



With the rapid development of information technology, "information overload" has become the main theme that plagues people's online life. As an effective tool to help users quickly search for useful information, a personalized recommendation is more and more popular among people. In order to solve the sparsity problem of the traditional matrix factorization algorithm and the problem of low utilization of review document information, this paper proposes a Bicon-vMF algorithm based on improved ConvMF. This algorithm uses two parallel convolutional neural networks to extract deep features from the user review set and item review set respectively and fuses these features into the decomposition of the rating matrix, so as to construct the user latent model and the item latent model more accurately. The experimental results show that compared with traditional recommendation algorithms like PMF, ConvMF, and DeepCoNN, the method proposed in this paper has lower prediction error and can achieve a better recommendation effect. Specifically, compared with the previous three algorithms, the prediction errors of the algorithm proposed in this paper are reduced by 45.8%, 16.6%, and 34.9%, respectively.
Mining and searching association relation of scientific papers based on deep learning
Apr 25, 2022There is a complex correlation among the data of scientific papers. The phenomenon reveals the data characteristics, laws, and correlations contained in the data of scientific and technological papers in specific fields, which can realize the analysis of scientific and technological big data and help to design applications to serve scientific researchers. Therefore, the research on mining and searching the association relationship of scientific papers based on deep learning has far-reaching practical significance.
Research on Domain Information Mining and Theme Evolution of Scientific Papers
Apr 18, 2022In recent years, with the increase of social investment in scientific research, the number of research results in various fields has increased significantly. Cross-disciplinary research results have gradually become an emerging frontier research direction. There is a certain dependence between a large number of research results. It is difficult to effectively analyze today's scientific research results when looking at a single research field in isolation. How to effectively use the huge number of scientific papers to help researchers becomes a challenge. This paper introduces the research status at home and abroad in terms of domain information mining and topic evolution law of scientific and technological papers from three aspects: the semantic feature representation learning of scientific and technological papers, the field information mining of scientific and technological papers, and the mining and prediction of research topic evolution rules of scientific and technological papers.
Knowledge Graph and Accurate Portrait Construction of Scientific and Technological Academic Conferences
Apr 11, 2022In recent years, with the continuous progress of science and technology, the number of scientific research achievements is increasing day by day, as the exchange platform and medium of scientific research achievements, the scientific and technological academic conferences have become more and more abundant. The convening of scientific and technological academic conferences will bring large number of academic papers, researchers, research institutions and other data, and the massive data brings difficulties for researchers to obtain valuable information. Therefore, it is of great significance to use deep learning technology to mine the core information in the data of scientific and technological academic conferences, and to realize a knowledge graph and accurate portrait system of scientific and technological academic conferences, so that researchers can obtain scientific research information faster.
Research on Cross-media Science and Technology Information Data Retrieval
Apr 11, 2022Since the era of big data, the Internet has been flooded with all kinds of information. Browsing information through the Internet has become an integral part of people's daily life. Unlike the news data and social data in the Internet, the cross-media technology information data has different characteristics. This data has become an important basis for researchers and scholars to track the current hot spots and explore the future direction of technology development. As the volume of science and technology information data becomes richer, the traditional science and technology information retrieval system, which only supports unimodal data retrieval and uses outdated data keyword matching model, can no longer meet the daily retrieval needs of science and technology scholars. Therefore, in view of the above research background, it is of profound practical significance to study the cross-media science and technology information data retrieval system based on deep semantic features, which is in line with the development trend of domestic and international technologies.
Accurate Portraits of Scientific Resources and Knowledge Service Components
Apr 11, 2022With the advent of the cloud computing era, the cost of creating, capturing and managing information has gradually decreased. The amount of data in the Internet is also showing explosive growth, and more and more scientific and technological resources are uploaded to the network. Different from news and social media data ubiquitous in the Internet, the main body of scientific and technological resources is composed of academic-style resources or entities such as papers, patents, authors, and research institutions. There is a rich relationship network between resources, from which a large amount of cutting-edge scientific and technological information can be mined. There are a large number of management and classification standards for existing scientific and technological resources, but these standards are difficult to completely cover all entities and associations of scientific and technological resources, and cannot accurately extract important information contained in scientific and technological resources. How to construct a complete and accurate representation of scientific and technological resources from structured and unstructured reports and texts in the network, and how to tap the potential value of scientific and technological resources is an urgent problem. The solution is to construct accurate portraits of scientific and technological resources in combination with knowledge graph related technologies.
An unsupervised cluster-level based method for learning node representations of heterogeneous graphs in scientific papers
Mar 31, 2022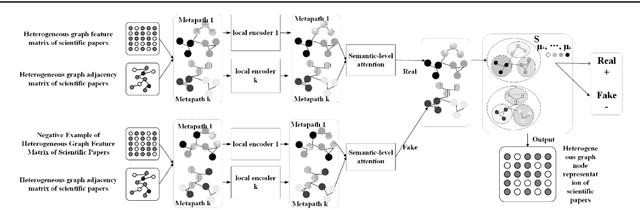
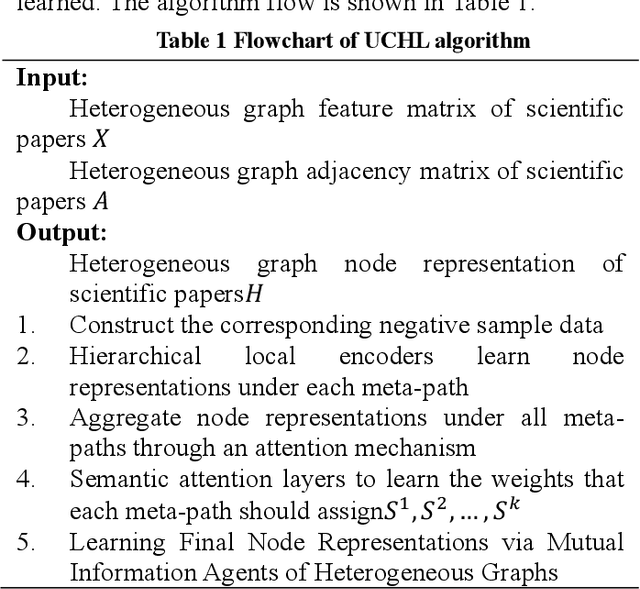
Learning knowledge representation of scientific paper data is a problem to be solved, and how to learn the representation of paper nodes in scientific paper heterogeneous network is the core to solve this problem. This paper proposes an unsupervised cluster-level scientific paper heterogeneous graph node representation learning method (UCHL), aiming at obtaining the representation of nodes (authors, institutions, papers, etc.) in the heterogeneous graph of scientific papers. Based on the heterogeneous graph representation, this paper performs link prediction on the entire heterogeneous graph and obtains the relationship between the edges of the nodes, that is, the relationship between papers and papers. Experiments results show that the proposed method achieves excellent performance on multiple evaluation metrics on real scientific paper datasets.
Research topic trend prediction of scientific papers based on spatial enhancement and dynamic graph convolution network
Mar 30, 2022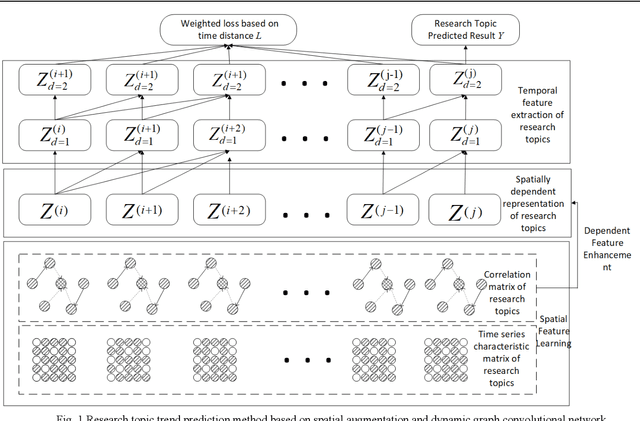
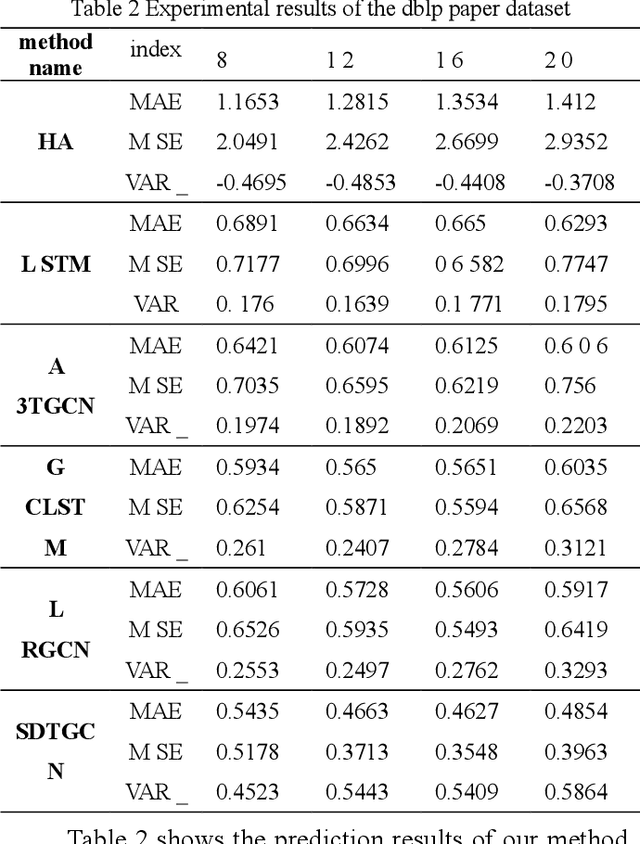
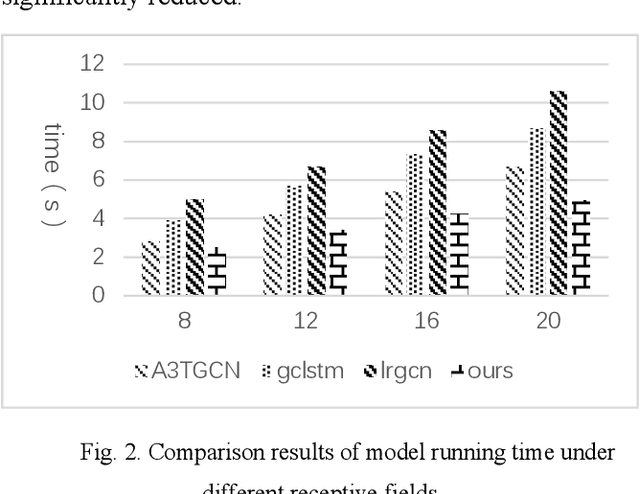
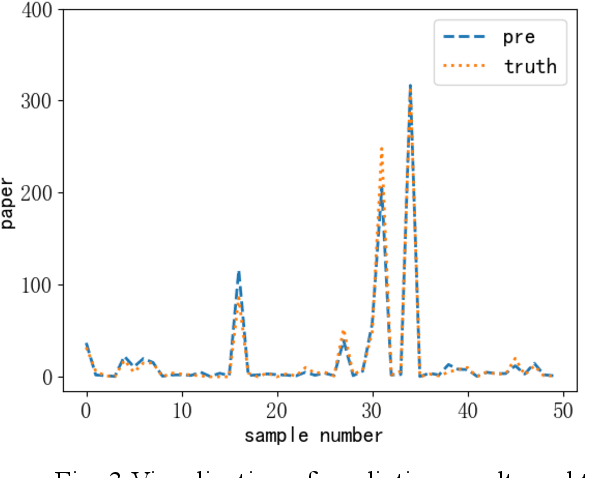
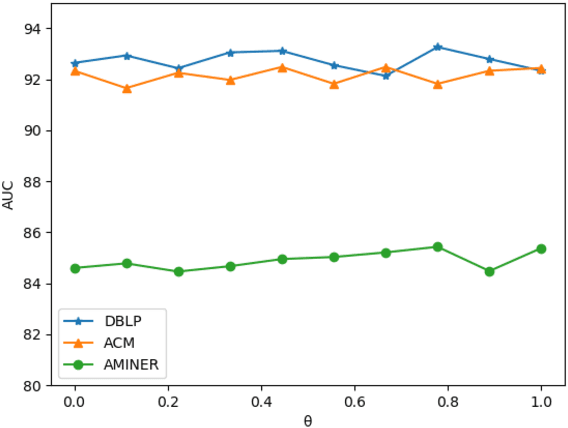
In recent years, with the increase of social investment in scientific research, the number of research results in various fields has increased significantly. Accurately and effectively predicting the trends of future research topics can help researchers discover future research hotspots. However, due to the increasingly close correlation between various research themes, there is a certain dependency relationship between a large number of research themes. Viewing a single research theme in isolation and using traditional sequence problem processing methods cannot effectively explore the spatial dependencies between these research themes. To simultaneously capture the spatial dependencies and temporal changes between research topics, we propose a deep neural network-based research topic hotness prediction algorithm, a spatiotemporal convolutional network model. Our model combines a graph convolutional neural network (GCN) and Temporal Convolutional Network (TCN), specifically, GCNs are used to learn the spatial dependencies of research topics a and use space dependence to strengthen spatial characteristics. TCN is used to learn the dynamics of research topics' trends. Optimization is based on the calculation of weighted losses based on time distance. Compared with the current mainstream sequence prediction models and similar spatiotemporal models on the paper datasets, experiments show that, in research topic prediction tasks, our model can effectively capture spatiotemporal relationships and the predictions outperform state-of-art baselines.