 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniRefiner: Teaching Pre-trained ViTs to Self-Dispose Dross via Contrastive Register
May 19, 2026Representation learning with Vision Transformers (ViTs) has advanced rapidly, yet the utility of large-scale models in spatially sensitive tasks is hindered by spurious tokens. Prior efforts to mitigate this have been limited, often defining these artifacts narrowly, for example, as simple high-norm outliers. We argue that this scope is insufficient. For dense prediction tasks, we posit that any token failing to encode location-aligned semantics should be treated as a spurious artifact. This broader definition reveals a more complex problem, leading us to systematically categorize and characterize three fundamental types of spurious tokens that corrupt spatial representations. Based on this comprehensive diagnosis, we propose UniRefiner, a universal refinement framework that teaches pre-trained ViTs to self-dispose of these artifacts. UniRefiner uses contrastive registers to explicitly isolate and redistribute spurious tokens via a dual objective: (i) it aligns image tokens with filtered regular tokens to preserve semantics, and (ii) it aligns register tokens with detected spurious tokens to capture the spurious signals. Our method requires only a few epochs of fine-tuning on ~5k images to refine diverse ViTs, including massive models like EVA-CLIP-8B and InternViT-6B. Experiments demonstrate consistent and significant improvements: notably, the refined EVA-CLIP-8B achieves 51.9\% mIoU on ADE20K (+9.4\%), surpassing specialized vision models like DINOv2 (49.1\%), while zero-shot segmentation accuracy improves by up to 22\%. UniRefiner unlocks the latent spatial potential of existing large-scale foundation models, paving the way for their broader application.
RecRM-Bench: Benchmarking Multidimensional Reward Modeling for Agentic Recommender Systems
May 12, 2026The integration of Large Language Model (LLM) agents is transforming recommender systems from simple query-item matching towards deeply personalized and interactive recommendations. Reinforcement Learning (RL) provides an essential framework for the optimization of these agents in recommendation tasks. However, current methodologies remain limited by a reliance on single dimensional outcome-based rewards that focus exclusively on final user interactions, overlooking critical intermediate capabilities, such as instruction following and complex intent understanding. Despite the necessity for designing multi-dimensional reward, the field lacks a standardized benchmark to facilitate this development. To bridge this gap, we introduce RecRM-Bench, the largest and most comprehensive benchmark to date for agentic recommender systems. It comprises over 1 million structured entries across four core evaluation dimensions: instruction following, factual consistency, query-item relevance, and fine-grained user behavior prediction. By supporting comprehensive assessment from syntactic compliance to complex intent grounding and preference modeling, RecRM-Bench provides a foundational dataset for training sophisticated reward models. Furthermore, we propose a systematic framework for the construction of multi-dimensional reward models and the integration of a hybrid reward function, establishing a robust foundation for developing reliable and highly capable agentic recommender systems. The complete RecRM-Bench dataset is publicly available at https://huggingface.co/datasets/wwzeng/RecRM-Bench.
TASL-Net: Tri-Attention Selective Learning Network for Intelligent Diagnosis of Bimodal Ultrasound Video
Sep 03, 2024In the intelligent diagnosis of bimodal (gray-scale and contrast-enhanced) ultrasound videos, medical domain knowledge such as the way sonographers browse videos, the particular areas they emphasize, and the features they pay special attention to, plays a decisive role in facilitating precise diagnosis. Embedding medical knowledge into the deep learning network can not only enhance performance but also boost clinical confidence and reliability of the network. However, it is an intractable challenge to automatically focus on these person- and disease-specific features in videos and to enable networks to encode bimodal information comprehensively and efficiently. This paper proposes a novel Tri-Attention Selective Learning Network (TASL-Net) to tackle this challenge and automatically embed three types of diagnostic attention of sonographers into a mutual transformer framework for intelligent diagnosis of bimodal ultrasound videos. Firstly, a time-intensity-curve-based video selector is designed to mimic the temporal attention of sonographers, thus removing a large amount of redundant information while improving computational efficiency of TASL-Net. Then, to introduce the spatial attention of the sonographers for contrast-enhanced video analysis, we propose the earliest-enhanced position detector based on structural similarity variation, on which the TASL-Net is made to focus on the differences of perfusion variation inside and outside the lesion. Finally, by proposing a mutual encoding strategy that combines convolution and transformer, TASL-Net possesses bimodal attention to structure features on gray-scale videos and to perfusion variations on contrast-enhanced videos. These modules work collaboratively and contribute to superior performance. We conduct a detailed experimental validation of TASL-Net's performance on three datasets, including lung, breast, and liver.
GenCos' Behaviors Modeling Based on Q Learning Improved by Dichotomy
Aug 04, 2020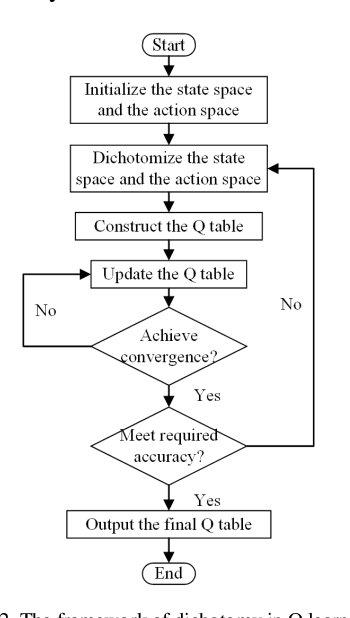
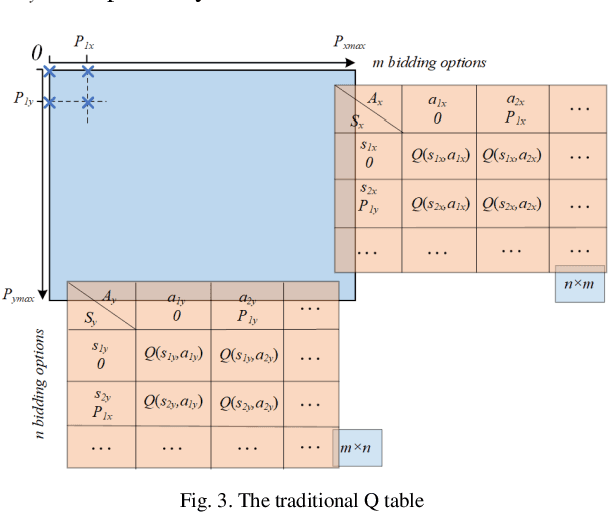

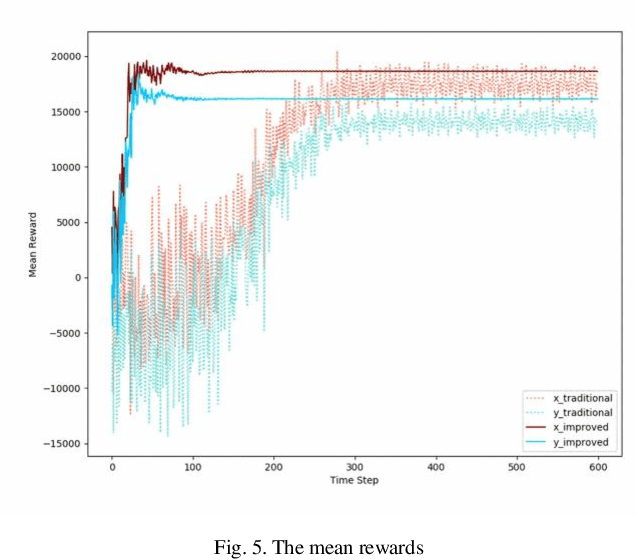
Q learning is widely used to simulate the behaviors of generation companies (GenCos) in an electricity market. However, existing Q learning method usually requires numerous iterations to converge, which is time-consuming and inefficient in practice. To enhance the calculation efficiency, a novel Q learning algorithm improved by dichotomy is proposed in this paper. This method modifies the update process of the Q table by dichotomizing the state space and the action space step by step. Simulation results in a repeated Cournot game show the effectiveness of the proposed algorithm.