 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom attention to profit: quantitative trading strategy based on transformer
Mar 30, 2024In traditional quantitative trading practice, navigating the complicated and dynamic financial market presents a persistent challenge. Former machine learning approaches have struggled to fully capture various market variables, often ignore long-term information and fail to catch up with essential signals that may lead the profit. This paper introduces an enhanced transformer architecture and designs a novel factor based on the model. By transfer learning from sentiment analysis, the proposed model not only exploits its original inherent advantages in capturing long-range dependencies and modelling complex data relationships but is also able to solve tasks with numerical inputs and accurately forecast future returns over a period. This work collects more than 5,000,000 rolling data of 4,601 stocks in the Chinese capital market from 2010 to 2019. The results of this study demonstrated the model's superior performance in predicting stock trends compared with other 100 factor-based quantitative strategies with lower turnover rates and a more robust half-life period. Notably, the model's innovative use transformer to establish factors, in conjunction with market sentiment information, has been shown to enhance the accuracy of trading signals significantly, thereby offering promising implications for the future of quantitative trading strategies.
Unleashing the potential of prompt engineering in Large Language Models: a comprehensive review
Oct 27, 2023



This paper delves into the pivotal role of prompt engineering in unleashing the capabilities of Large Language Models (LLMs). Prompt engineering is the process of structuring input text for LLMs and is a technique integral to optimizing the efficacy of LLMs. This survey elucidates foundational principles of prompt engineering, such as role-prompting, one-shot, and few-shot prompting, as well as more advanced methodologies such as the chain-of-thought and tree-of-thoughts prompting. The paper sheds light on how external assistance in the form of plugins can assist in this task, and reduce machine hallucination by retrieving external knowledge. We subsequently delineate prospective directions in prompt engineering research, emphasizing the need for a deeper understanding of structures and the role of agents in Artificial Intelligence-Generated Content (AIGC) tools. We discuss how to assess the efficacy of prompt methods from different perspectives and using different methods. Finally, we gather information about the application of prompt engineering in such fields as education and programming, showing its transformative potential. This comprehensive survey aims to serve as a friendly guide for anyone venturing through the big world of LLMs and prompt engineering.
CLARE: Conservative Model-Based Reward Learning for Offline Inverse Reinforcement Learning
Feb 21, 2023



This work aims to tackle a major challenge in offline Inverse Reinforcement Learning (IRL), namely the reward extrapolation error, where the learned reward function may fail to explain the task correctly and misguide the agent in unseen environments due to the intrinsic covariate shift. Leveraging both expert data and lower-quality diverse data, we devise a principled algorithm (namely CLARE) that solves offline IRL efficiently via integrating "conservatism" into a learned reward function and utilizing an estimated dynamics model. Our theoretical analysis provides an upper bound on the return gap between the learned policy and the expert policy, based on which we characterize the impact of covariate shift by examining subtle two-tier tradeoffs between the exploitation (on both expert and diverse data) and exploration (on the estimated dynamics model). We show that CLARE can provably alleviate the reward extrapolation error by striking the right exploitation-exploration balance therein. Extensive experiments corroborate the significant performance gains of CLARE over existing state-of-the-art algorithms on MuJoCo continuous control tasks (especially with a small offline dataset), and the learned reward is highly instructive for further learning.
Long-term Spatio-temporal Forecasting via Dynamic Multiple-Graph Attention
May 02, 2022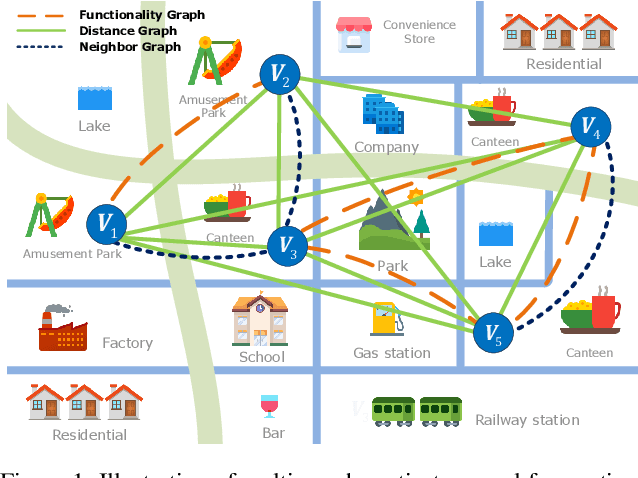
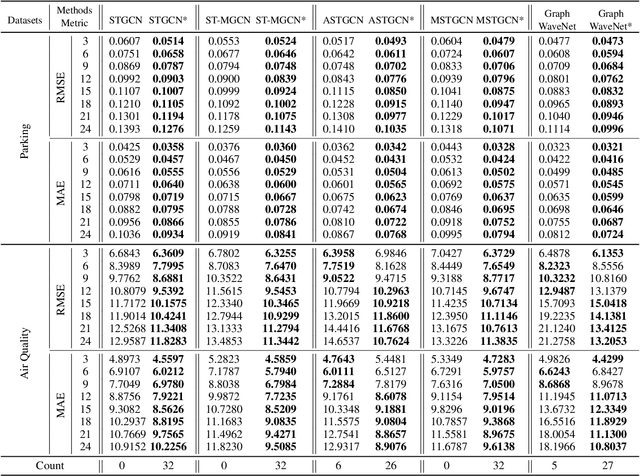
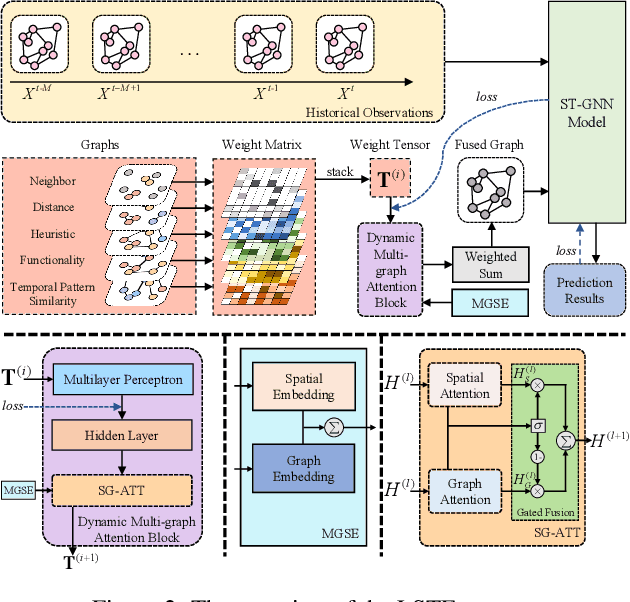
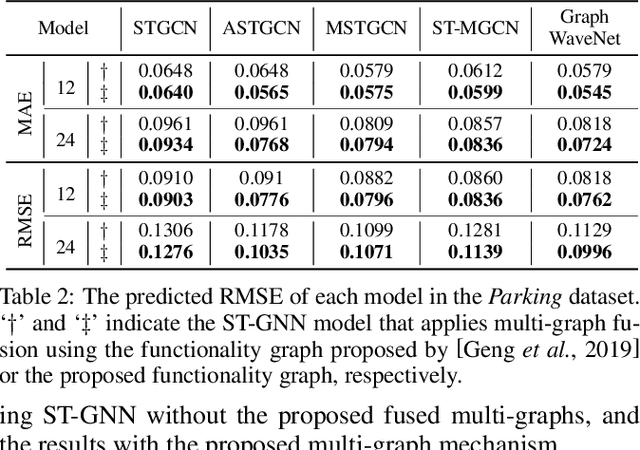
Many real-world ubiquitous applications, such as parking recommendations and air pollution monitoring, benefit significantly from accurate long-term spatio-temporal forecasting (LSTF). LSTF makes use of long-term dependency between spatial and temporal domains, contextual information, and inherent pattern in the data. Recent studies have revealed the potential of multi-graph neural networks (MGNNs) to improve prediction performance. However, existing MGNN methods cannot be directly applied to LSTF due to several issues: the low level of generality, insufficient use of contextual information, and the imbalanced graph fusion approach. To address these issues, we construct new graph models to represent the contextual information of each node and the long-term spatio-temporal data dependency structure. To fuse the information across multiple graphs, we propose a new dynamic multi-graph fusion module to characterize the correlations of nodes within a graph and the nodes across graphs via the spatial attention and graph attention mechanisms. Furthermore, we introduce a trainable weight tensor to indicate the importance of each node in different graphs. Extensive experiments on two large-scale datasets demonstrate that our proposed approaches significantly improve the performance of existing graph neural network models in LSTF prediction tasks.
Continual Learning of Generative Models with Limited Data: From Wasserstein-1 Barycenter to Adaptive Coalescence
Jan 22, 2021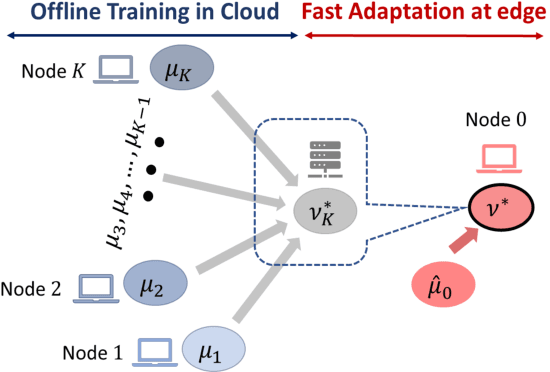

Learning generative models is challenging for a network edge node with limited data and computing power. Since tasks in similar environments share model similarity, it is plausible to leverage pre-trained generative models from the cloud or other edge nodes. Appealing to optimal transport theory tailored towards Wasserstein-1 generative adversarial networks (WGAN), this study aims to develop a framework which systematically optimizes continual learning of generative models using local data at the edge node while exploiting adaptive coalescence of pre-trained generative models. Specifically, by treating the knowledge transfer from other nodes as Wasserstein balls centered around their pre-trained models, continual learning of generative models is cast as a constrained optimization problem, which is further reduced to a Wasserstein-1 barycenter problem. A two-stage approach is devised accordingly: 1) The barycenters among the pre-trained models are computed offline, where displacement interpolation is used as the theoretic foundation for finding adaptive barycenters via a "recursive" WGAN configuration; 2) the barycenter computed offline is used as meta-model initialization for continual learning and then fast adaptation is carried out to find the generative model using the local samples at the target edge node. Finally, a weight ternarization method, based on joint optimization of weights and threshold for quantization, is developed to compress the generative model further.