 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiamond Maps: Efficient Reward Alignment via Stochastic Flow Maps
Feb 05, 2026Flow and diffusion models produce high-quality samples, but adapting them to user preferences or constraints post-training remains costly and brittle, a challenge commonly called reward alignment. We argue that efficient reward alignment should be a property of the generative model itself, not an afterthought, and redesign the model for adaptability. We propose "Diamond Maps", stochastic flow map models that enable efficient and accurate alignment to arbitrary rewards at inference time. Diamond Maps amortize many simulation steps into a single-step sampler, like flow maps, while preserving the stochasticity required for optimal reward alignment. This design makes search, sequential Monte Carlo, and guidance scalable by enabling efficient and consistent estimation of the value function. Our experiments show that Diamond Maps can be learned efficiently via distillation from GLASS Flows, achieve stronger reward alignment performance, and scale better than existing methods. Our results point toward a practical route to generative models that can be rapidly adapted to arbitrary preferences and constraints at inference time.
Dissecting Multimodal In-Context Learning: Modality Asymmetries and Circuit Dynamics in modern Transformers
Jan 28, 2026Transformer-based multimodal large language models often exhibit in-context learning (ICL) abilities. Motivated by this phenomenon, we ask: how do transformers learn to associate information across modalities from in-context examples? We investigate this question through controlled experiments on small transformers trained on synthetic classification tasks, enabling precise manipulation of data statistics and model architecture. We begin by revisiting core principles of unimodal ICL in modern transformers. While several prior findings replicate, we find that Rotary Position Embeddings (RoPE) increases the data complexity threshold for ICL. Extending to the multimodal setting reveals a fundamental learning asymmetry: when pretrained on high-diversity data from a primary modality, surprisingly low data complexity in the secondary modality suffices for multimodal ICL to emerge. Mechanistic analysis shows that both settings rely on an induction-style mechanism that copies labels from matching in-context exemplars; multimodal training refines and extends these circuits across modalities. Our findings provide a mechanistic foundation for understanding multimodal ICL in modern transformers and introduce a controlled testbed for future investigation.
TimeSAE: Sparse Decoding for Faithful Explanations of Black-Box Time Series Models
Jan 14, 2026As black box models and pretrained models gain traction in time series applications, understanding and explaining their predictions becomes increasingly vital, especially in high-stakes domains where interpretability and trust are essential. However, most of the existing methods involve only in-distribution explanation, and do not generalize outside the training support, which requires the learning capability of generalization. In this work, we aim to provide a framework to explain black-box models for time series data through the dual lenses of Sparse Autoencoders (SAEs) and causality. We show that many current explanation methods are sensitive to distributional shifts, limiting their effectiveness in real-world scenarios. Building on the concept of Sparse Autoencoder, we introduce TimeSAE, a framework for black-box model explanation. We conduct extensive evaluations of TimeSAE on both synthetic and real-world time series datasets, comparing it to leading baselines. The results, supported by both quantitative metrics and qualitative insights, show that TimeSAE provides more faithful and robust explanations. Our code is available in an easy-to-use library TimeSAE-Lib: https://anonymous.4open.science/w/TimeSAE-571D/.
Beyond the final layer: Attentive multilayer fusion for vision transformers
Jan 14, 2026With the rise of large-scale foundation models, efficiently adapting them to downstream tasks remains a central challenge. Linear probing, which freezes the backbone and trains a lightweight head, is computationally efficient but often restricted to last-layer representations. We show that task-relevant information is distributed across the network hierarchy rather than solely encoded in any of the last layers. To leverage this distribution of information, we apply an attentive probing mechanism that dynamically fuses representations from all layers of a Vision Transformer. This mechanism learns to identify the most relevant layers for a target task and combines low-level structural cues with high-level semantic abstractions. Across 20 diverse datasets and multiple pretrained foundation models, our method achieves consistent, substantial gains over standard linear probes. Attention heatmaps further reveal that tasks different from the pre-training domain benefit most from intermediate representations. Overall, our findings underscore the value of intermediate layer information and demonstrate a principled, task aware approach for unlocking their potential in probing-based adaptation.
Training-free Uncertainty Guidance for Complex Visual Tasks with MLLMs
Oct 01, 2025



Multimodal Large Language Models (MLLMs) often struggle with fine-grained perception, such as identifying small objects in high-resolution images or finding key moments in long videos. Existing works typically rely on complicated, task-specific fine-tuning, which limits their generalizability and increases model complexity. In this work, we propose an effective, training-free framework that uses an MLLM's intrinsic uncertainty as a proactive guidance signal. Our core insight is that a model's output entropy decreases when presented with relevant visual information. We introduce a unified mechanism that scores candidate visual inputs by response uncertainty, enabling the model to autonomously focus on the most salient data. We apply this simple principle to three complex visual tasks: Visual Search, Long Video Understanding, and Temporal Grounding, allowing off-the-shelf MLLMs to achieve performance competitive with specialized, fine-tuned methods. Our work validates that harnessing intrinsic uncertainty is a powerful, general strategy for enhancing fine-grained multimodal performance.
Stitch: Training-Free Position Control in Multimodal Diffusion Transformers
Sep 30, 2025Text-to-Image (T2I) generation models have advanced rapidly in recent years, but accurately capturing spatial relationships like "above" or "to the right of" poses a persistent challenge. Earlier methods improved spatial relationship following with external position control. However, as architectures evolved to enhance image quality, these techniques became incompatible with modern models. We propose Stitch, a training-free method for incorporating external position control into Multi-Modal Diffusion Transformers (MMDiT) via automatically-generated bounding boxes. Stitch produces images that are both spatially accurate and visually appealing by generating individual objects within designated bounding boxes and seamlessly stitching them together. We find that targeted attention heads capture the information necessary to isolate and cut out individual objects mid-generation, without needing to fully complete the image. We evaluate Stitch on PosEval, our benchmark for position-based T2I generation. Featuring five new tasks that extend the concept of Position beyond the basic GenEval task, PosEval demonstrates that even top models still have significant room for improvement in position-based generation. Tested on Qwen-Image, FLUX, and SD3.5, Stitch consistently enhances base models, even improving FLUX by 218% on GenEval's Position task and by 206% on PosEval. Stitch achieves state-of-the-art results with Qwen-Image on PosEval, improving over previous models by 54%, all accomplished while integrating position control into leading models training-free. Code is available at https://github.com/ExplainableML/Stitch.
Road Obstacle Video Segmentation
Sep 16, 2025With the growing deployment of autonomous driving agents, the detection and segmentation of road obstacles have become critical to ensure safe autonomous navigation. However, existing road-obstacle segmentation methods are applied on individual frames, overlooking the temporal nature of the problem, leading to inconsistent prediction maps between consecutive frames. In this work, we demonstrate that the road-obstacle segmentation task is inherently temporal, since the segmentation maps for consecutive frames are strongly correlated. To address this, we curate and adapt four evaluation benchmarks for road-obstacle video segmentation and evaluate 11 state-of-the-art image- and video-based segmentation methods on these benchmarks. Moreover, we introduce two strong baseline methods based on vision foundation models. Our approach establishes a new state-of-the-art in road-obstacle video segmentation for long-range video sequences, providing valuable insights and direction for future research.
Noise Hypernetworks: Amortizing Test-Time Compute in Diffusion Models
Aug 13, 2025The new paradigm of test-time scaling has yielded remarkable breakthroughs in Large Language Models (LLMs) (e.g. reasoning models) and in generative vision models, allowing models to allocate additional computation during inference to effectively tackle increasingly complex problems. Despite the improvements of this approach, an important limitation emerges: the substantial increase in computation time makes the process slow and impractical for many applications. Given the success of this paradigm and its growing usage, we seek to preserve its benefits while eschewing the inference overhead. In this work we propose one solution to the critical problem of integrating test-time scaling knowledge into a model during post-training. Specifically, we replace reward guided test-time noise optimization in diffusion models with a Noise Hypernetwork that modulates initial input noise. We propose a theoretically grounded framework for learning this reward-tilted distribution for distilled generators, through a tractable noise-space objective that maintains fidelity to the base model while optimizing for desired characteristics. We show that our approach recovers a substantial portion of the quality gains from explicit test-time optimization at a fraction of the computational cost. Code is available at https://github.com/ExplainableML/HyperNoise
SUB: Benchmarking CBM Generalization via Synthetic Attribute Substitutions
Jul 31, 2025



Concept Bottleneck Models (CBMs) and other concept-based interpretable models show great promise for making AI applications more transparent, which is essential in fields like medicine. Despite their success, we demonstrate that CBMs struggle to reliably identify the correct concepts under distribution shifts. To assess the robustness of CBMs to concept variations, we introduce SUB: a fine-grained image and concept benchmark containing 38,400 synthetic images based on the CUB dataset. To create SUB, we select a CUB subset of 33 bird classes and 45 concepts to generate images which substitute a specific concept, such as wing color or belly pattern. We introduce a novel Tied Diffusion Guidance (TDG) method to precisely control generated images, where noise sharing for two parallel denoising processes ensures that both the correct bird class and the correct attribute are generated. This novel benchmark enables rigorous evaluation of CBMs and similar interpretable models, contributing to the development of more robust methods. Our code is available at https://github.com/ExplainableML/sub and the dataset at http://huggingface.co/datasets/Jessica-bader/SUB.
Investigating Structural Pruning and Recovery Techniques for Compressing Multimodal Large Language Models: An Empirical Study
Jul 28, 2025
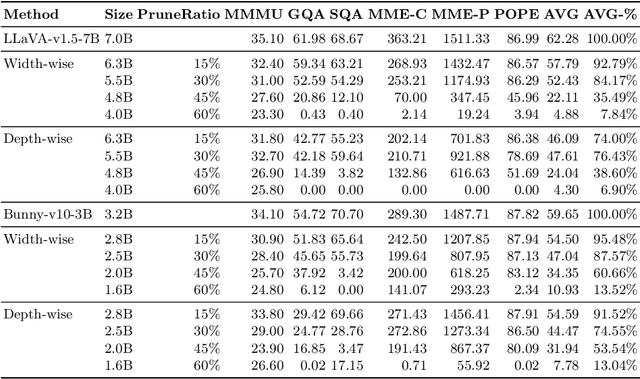
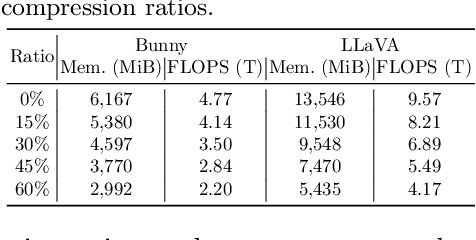

While Multimodal Large Language Models (MLLMs) demonstrate impressive capabilities, their substantial computational and memory requirements pose significant barriers to practical deployment. Current parameter reduction techniques primarily involve training MLLMs from Small Language Models (SLMs), but these methods offer limited flexibility and remain computationally intensive. To address this gap, we propose to directly compress existing MLLMs through structural pruning combined with efficient recovery training. Specifically, we investigate two structural pruning paradigms--layerwise and widthwise pruning--applied to the language model backbone of MLLMs, alongside supervised finetuning and knowledge distillation. Additionally, we assess the feasibility of conducting recovery training with only a small fraction of the available data. Our results show that widthwise pruning generally maintains better performance in low-resource scenarios with limited computational resources or insufficient finetuning data. As for the recovery training, finetuning only the multimodal projector is sufficient at small compression levels (< 20%). Furthermore, a combination of supervised finetuning and hidden-state distillation yields optimal recovery across various pruning levels. Notably, effective recovery can be achieved with as little as 5% of the original training data, while retaining over 95% of the original performance. Through empirical study on two representative MLLMs, i.e., LLaVA-v1.5-7B and Bunny-v1.0-3B, this study offers actionable insights for practitioners aiming to compress MLLMs effectively without extensive computation resources or sufficient data.