 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Pruning of Large Vision Language Models: A Comprehensive Study on Pruning Dynamics, Recovery, and Data Efficiency
Apr 27, 2026While Large Vision Language Models (LVLMs) demonstrate impressive capabilities, their substantial computational and memory requirements pose deployment challenges on resource-constrained edge devices. Current parameter reduction techniques primarily involve training LVLMs from small language models, but these methods offer limited flexibility and remain computationally intensive. We study a complementary route: compressing existing LVLMs by applying structured pruning to the language model backbone, followed by lightweight recovery training. Specifically, we investigate two structural pruning paradigms: layerwise and widthwise pruning, and pair them with supervised finetuning and knowledge distillation on logits and hidden states. Additionally, we assess the feasibility of conducting recovery training with only a small fraction of the available data. Our results show that widthwise pruning generally maintains better performance in low-resource scenarios, where computational resources are limited or there is insufficient finetuning data. As for the recovery training, finetuning only the multimodal projector is sufficient at small compression levels. Furthermore, a combination of supervised finetuning and hidden-state distillation yields optimal recovery across various pruning levels. Notably, effective recovery can be achieved using just 5% of the original data, while retaining over 95% of the original performance. Through empirical study on three representative LVLM families ranging from 3B to 7B parameters, this study offers actionable insights for practitioners to compress LVLMs without extensive computation resources or sufficient data. The code base is available at https://github.com/YiranHuangIrene/VLMCompression.git.
Beyond the final layer: Attentive multilayer fusion for vision transformers
Jan 14, 2026With the rise of large-scale foundation models, efficiently adapting them to downstream tasks remains a central challenge. Linear probing, which freezes the backbone and trains a lightweight head, is computationally efficient but often restricted to last-layer representations. We show that task-relevant information is distributed across the network hierarchy rather than solely encoded in any of the last layers. To leverage this distribution of information, we apply an attentive probing mechanism that dynamically fuses representations from all layers of a Vision Transformer. This mechanism learns to identify the most relevant layers for a target task and combines low-level structural cues with high-level semantic abstractions. Across 20 diverse datasets and multiple pretrained foundation models, our method achieves consistent, substantial gains over standard linear probes. Attention heatmaps further reveal that tasks different from the pre-training domain benefit most from intermediate representations. Overall, our findings underscore the value of intermediate layer information and demonstrate a principled, task aware approach for unlocking their potential in probing-based adaptation.
Investigating Structural Pruning and Recovery Techniques for Compressing Multimodal Large Language Models: An Empirical Study
Jul 28, 2025
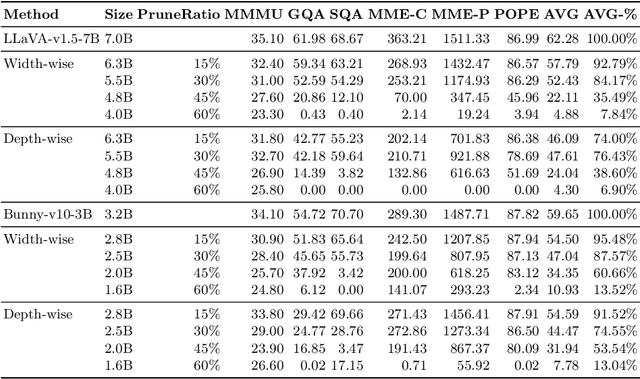
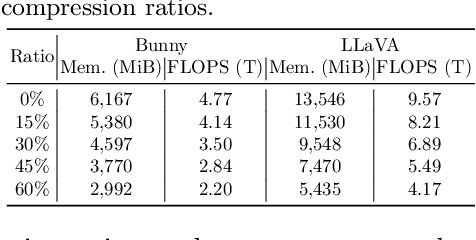

While Multimodal Large Language Models (MLLMs) demonstrate impressive capabilities, their substantial computational and memory requirements pose significant barriers to practical deployment. Current parameter reduction techniques primarily involve training MLLMs from Small Language Models (SLMs), but these methods offer limited flexibility and remain computationally intensive. To address this gap, we propose to directly compress existing MLLMs through structural pruning combined with efficient recovery training. Specifically, we investigate two structural pruning paradigms--layerwise and widthwise pruning--applied to the language model backbone of MLLMs, alongside supervised finetuning and knowledge distillation. Additionally, we assess the feasibility of conducting recovery training with only a small fraction of the available data. Our results show that widthwise pruning generally maintains better performance in low-resource scenarios with limited computational resources or insufficient finetuning data. As for the recovery training, finetuning only the multimodal projector is sufficient at small compression levels (< 20%). Furthermore, a combination of supervised finetuning and hidden-state distillation yields optimal recovery across various pruning levels. Notably, effective recovery can be achieved with as little as 5% of the original training data, while retaining over 95% of the original performance. Through empirical study on two representative MLLMs, i.e., LLaVA-v1.5-7B and Bunny-v1.0-3B, this study offers actionable insights for practitioners aiming to compress MLLMs effectively without extensive computation resources or sufficient data.
Understanding the Limits of Lifelong Knowledge Editing in LLMs
Mar 07, 2025Keeping large language models factually up-to-date is crucial for deployment, yet costly retraining remains a challenge. Knowledge editing offers a promising alternative, but methods are only tested on small-scale or synthetic edit benchmarks. In this work, we aim to bridge research into lifelong knowledge editing to real-world edits at practically relevant scale. We first introduce WikiBigEdit; a large-scale benchmark of real-world Wikidata edits, built to automatically extend lifelong for future-proof benchmarking. In its first instance, it includes over 500K question-answer pairs for knowledge editing alongside a comprehensive evaluation pipeline. Finally, we use WikiBigEdit to study existing knowledge editing techniques' ability to incorporate large volumes of real-world facts and contrast their capabilities to generic modification techniques such as retrieval augmentation and continual finetuning to acquire a complete picture of the practical extent of current lifelong knowledge editing.
Reflecting on the State of Rehearsal-free Continual Learning with Pretrained Models
Jun 13, 2024With the advent and recent ubiquity of foundation models, continual learning (CL) has recently shifted from continual training from scratch to the continual adaptation of pretrained models, seeing particular success on rehearsal-free CL benchmarks (RFCL). To achieve this, most proposed methods adapt and restructure parameter-efficient finetuning techniques (PEFT) to suit the continual nature of the problem. Based most often on input-conditional query-mechanisms or regularizations on top of prompt- or adapter-based PEFT, these PEFT-style RFCL (P-RFCL) approaches report peak performances; often convincingly outperforming existing CL techniques. However, on the other end, critical studies have recently highlighted competitive results by training on just the first task or via simple non-parametric baselines. Consequently, questions arise about the relationship between methodological choices in P-RFCL and their reported high benchmark scores. In this work, we tackle these questions to better understand the true drivers behind strong P-RFCL performances, their placement w.r.t. recent first-task adaptation studies, and their relation to preceding CL standards such as EWC or SI. In particular, we show: (1) P-RFCL techniques relying on input-conditional query mechanisms work not because, but rather despite them by collapsing towards standard PEFT shortcut solutions. (2) Indeed, we show how most often, P-RFCL techniques can be matched by a simple and lightweight PEFT baseline. (3) Using this baseline, we identify the implicit bound on tunable parameters when deriving RFCL approaches from PEFT methods as a potential denominator behind P-RFCL efficacy. Finally, we (4) better disentangle continual versus first-task adaptation, and (5) motivate standard RFCL techniques s.a. EWC or SI in light of recent P-RFCL methods.
Fantastic Gains and Where to Find Them: On the Existence and Prospect of General Knowledge Transfer between Any Pretrained Model
Oct 26, 2023Training deep networks requires various design decisions regarding for instance their architecture, data augmentation, or optimization. In this work, we find these training variations to result in networks learning unique feature sets from the data. Using public model libraries comprising thousands of models trained on canonical datasets like ImageNet, we observe that for arbitrary pairings of pretrained models, one model extracts significant data context unavailable in the other -- independent of overall performance. Given any arbitrary pairing of pretrained models and no external rankings (such as separate test sets, e.g. due to data privacy), we investigate if it is possible to transfer such "complementary" knowledge from one model to another without performance degradation -- a task made particularly difficult as additional knowledge can be contained in stronger, equiperformant or weaker models. Yet facilitating robust transfer in scenarios agnostic to pretrained model pairings would unlock auxiliary gains and knowledge fusion from any model repository without restrictions on model and problem specifics - including from weaker, lower-performance models. This work therefore provides an initial, in-depth exploration on the viability of such general-purpose knowledge transfer. Across large-scale experiments, we first reveal the shortcomings of standard knowledge distillation techniques, and then propose a much more general extension through data partitioning for successful transfer between nearly all pretrained models, which we show can also be done unsupervised. Finally, we assess both the scalability and impact of fundamental model properties on successful model-agnostic knowledge transfer.
Learning to Defer with Limited Expert Predictions
Apr 14, 2023



Recent research suggests that combining AI models with a human expert can exceed the performance of either alone. The combination of their capabilities is often realized by learning to defer algorithms that enable the AI to learn to decide whether to make a prediction for a particular instance or defer it to the human expert. However, to accurately learn which instances should be deferred to the human expert, a large number of expert predictions that accurately reflect the expert's capabilities are required -- in addition to the ground truth labels needed to train the AI. This requirement shared by many learning to defer algorithms hinders their adoption in scenarios where the responsible expert regularly changes or where acquiring a sufficient number of expert predictions is costly. In this paper, we propose a three-step approach to reduce the number of expert predictions required to train learning to defer algorithms. It encompasses (1) the training of an embedding model with ground truth labels to generate feature representations that serve as a basis for (2) the training of an expertise predictor model to approximate the expert's capabilities. (3) The expertise predictor generates artificial expert predictions for instances not yet labeled by the expert, which are required by the learning to defer algorithms. We evaluate our approach on two public datasets. One with "synthetically" generated human experts and another from the medical domain containing real-world radiologists' predictions. Our experiments show that the approach allows the training of various learning to defer algorithms with a minimal number of human expert predictions. Furthermore, we demonstrate that even a small number of expert predictions per class is sufficient for these algorithms to exceed the performance the AI and the human expert can achieve individually.