 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Limits of Model Compression in LLMs: A Knowledge Distillation Study on QA Tasks
Jul 10, 2025

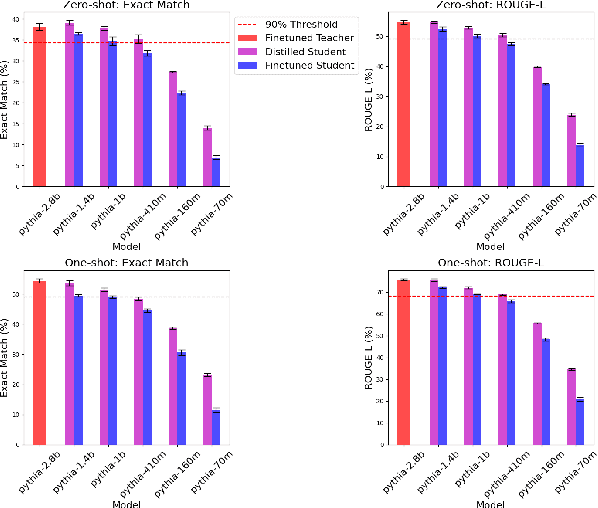

Large Language Models (LLMs) have demonstrated outstanding performance across a range of NLP tasks, however, their computational demands hinder their deployment in real-world, resource-constrained environments. This work investigates the extent to which LLMs can be compressed using Knowledge Distillation (KD) while maintaining strong performance on Question Answering (QA) tasks. We evaluate student models distilled from the Pythia and Qwen2.5 families on two QA benchmarks, SQuAD and MLQA, under zero-shot and one-shot prompting conditions. Results show that student models retain over 90% of their teacher models' performance while reducing parameter counts by up to 57.1%. Furthermore, one-shot prompting yields additional performance gains over zero-shot setups for both model families. These findings underscore the trade-off between model efficiency and task performance, demonstrating that KD, combined with minimal prompting, can yield compact yet capable QA systems suitable for resource-constrained applications.
Large Language Model in Medical Informatics: Direct Classification and Enhanced Text Representations for Automatic ICD Coding
Nov 11, 2024

Addressing the complexity of accurately classifying International Classification of Diseases (ICD) codes from medical discharge summaries is challenging due to the intricate nature of medical documentation. This paper explores the use of Large Language Models (LLM), specifically the LLAMA architecture, to enhance ICD code classification through two methodologies: direct application as a classifier and as a generator of enriched text representations within a Multi-Filter Residual Convolutional Neural Network (MultiResCNN) framework. We evaluate these methods by comparing them against state-of-the-art approaches, revealing LLAMA's potential to significantly improve classification outcomes by providing deep contextual insights into medical texts.
Falcon 7b for Software Mention Detection in Scholarly Documents
May 14, 2024
This paper aims to tackle the challenge posed by the increasing integration of software tools in research across various disciplines by investigating the application of Falcon-7b for the detection and classification of software mentions within scholarly texts. Specifically, the study focuses on solving Subtask I of the Software Mention Detection in Scholarly Publications (SOMD), which entails identifying and categorizing software mentions from academic literature. Through comprehensive experimentation, the paper explores different training strategies, including a dual-classifier approach, adaptive sampling, and weighted loss scaling, to enhance detection accuracy while overcoming the complexities of class imbalance and the nuanced syntax of scholarly writing. The findings highlight the benefits of selective labelling and adaptive sampling in improving the model's performance. However, they also indicate that integrating multiple strategies does not necessarily result in cumulative improvements. This research offers insights into the effective application of large language models for specific tasks such as SOMD, underlining the importance of tailored approaches to address the unique challenges presented by academic text analysis.