 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillful high-resolution weather forecasting independent of physical models
May 27, 2026Accurate and timely weather forecasts are critical for high-impact decisions in modern society. Machine-learning-based weather prediction is emerging as an alternative for producing initial conditions, forecasts, and even both in end-to-end systems. These methods deliver predictions faster and often with higher skill than traditional numerical weather prediction (NWP). However, even end-to-end models typically rely on NWP-generated reanalyses for supervision, thereby inheriting the biases and resolution limitations of those NWPs, and limiting adaptation to settings where suitable reanalysis products are unavailable, infrequently updated, or expensive to produce. Here we introduce ObsCast, a regional system that generates both analysis and predictions, without using any NWP-derived data in either training or inference, while still achieving state-of-the-art performance in short-term high-resolution regional modeling. Over the contiguous United States and Europe, ObsCast outperforms operational NWP for near-surface variables through 18 h and produces skillful precipitation forecasts. It provides a simpler and more adaptable route to build and refine regional forecasting services directly from local observations, without the need to develop complex and costly traditional forecasting pipelines.
OMG-HD: A High-Resolution AI Weather Model for End-to-End Forecasts from Observations
Dec 24, 2024



In recent years, Artificial Intelligence Weather Prediction (AIWP) models have achieved performance comparable to, or even surpassing, traditional Numerical Weather Prediction (NWP) models by leveraging reanalysis data. However, a less-explored approach involves training AIWP models directly on observational data, enhancing computational efficiency and improving forecast accuracy by reducing the uncertainties introduced through data assimilation processes. In this study, we propose OMG-HD, a novel AI-based regional high-resolution weather forecasting model designed to make predictions directly from observational data sources, including surface stations, radar, and satellite, thereby removing the need for operational data assimilation. Our evaluation shows that OMG-HD outperforms both the European Centre for Medium-Range Weather Forecasts (ECMWF)'s high-resolution operational forecasting system, IFS-HRES, and the High-Resolution Rapid Refresh (HRRR) model at lead times of up to 12 hours across the contiguous United States (CONUS) region. We achieve up to a 13% improvement on RMSE for 2-meter temperature, 17% on 10-meter wind speed, 48% on 2-meter specific humidity, and 32% on surface pressure compared to HRRR. Our method shows that it is possible to use AI-driven approaches for rapid weather predictions without relying on NWP-derived weather fields as model input. This is a promising step towards using observational data directly to make operational forecasts with AIWP models.
ChemiRise: a data-driven retrosynthesis engine
Aug 09, 2021
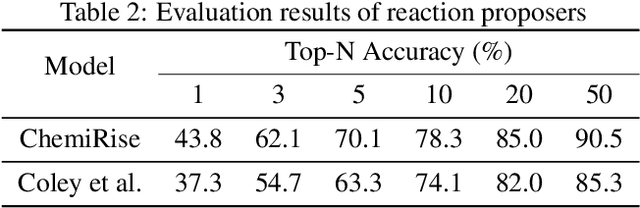

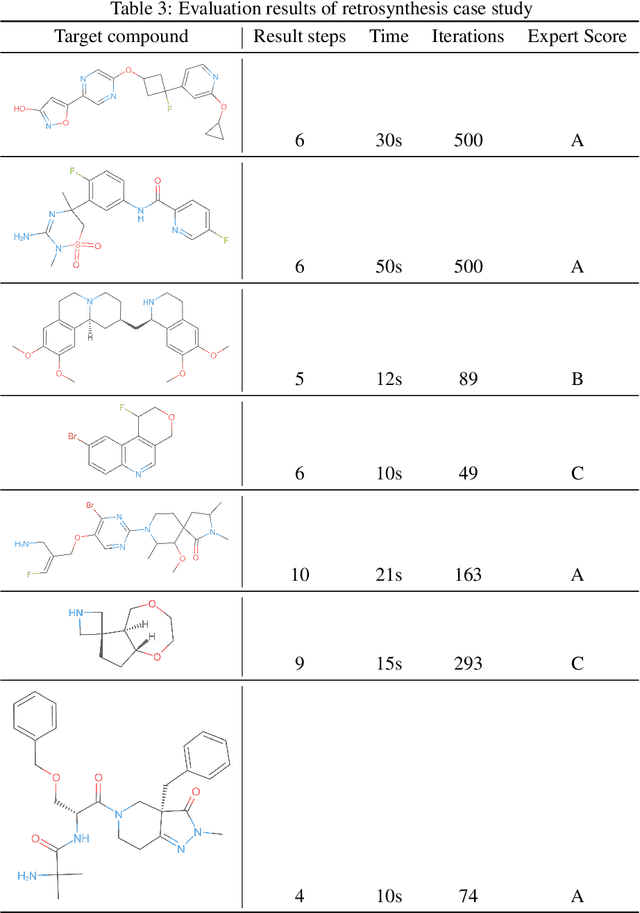
We have developed an end-to-end, retrosynthesis system, named ChemiRise, that can propose complete retrosynthesis routes for organic compounds rapidly and reliably. The system was trained on a processed patent database of over 3 million organic reactions. Experimental reactions were atom-mapped, clustered, and extracted into reaction templates. We then trained a graph convolutional neural network-based one-step reaction proposer using template embeddings and developed a guiding algorithm on the directed acyclic graph (DAG) of chemical compounds to find the best candidate to explore. The atom-mapping algorithm and the one-step reaction proposer were benchmarked against previous studies and showed better results. The final product was demonstrated by retrosynthesis routes reviewed and rated by human experts, showing satisfying functionality and a potential productivity boost in real-life use cases.
Molecular modeling with machine-learned universal potential functions
Mar 06, 2021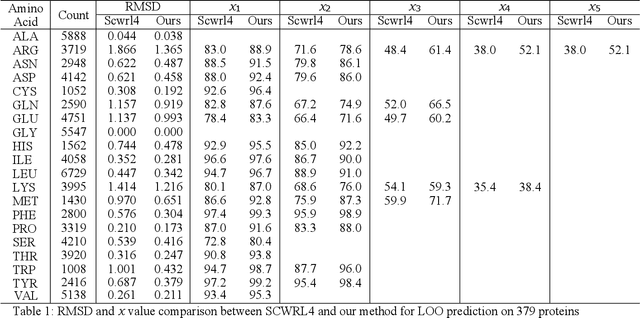


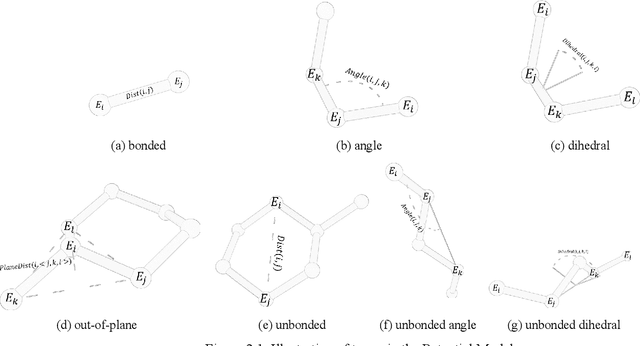
Molecular modeling is an important topic in drug discovery. Decades of research have led to the development of high quality scalable molecular force fields. In this paper, we show that neural networks can be used to train an universal approximator for energy potential functions. By incorporating a fully automated training process we have been able to train smooth, differentiable, and predictive potential functions on large scale crystal structures. A variety of tests have also performed to show the superiority and versatility of the machine-learned model.
DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients
Feb 02, 2018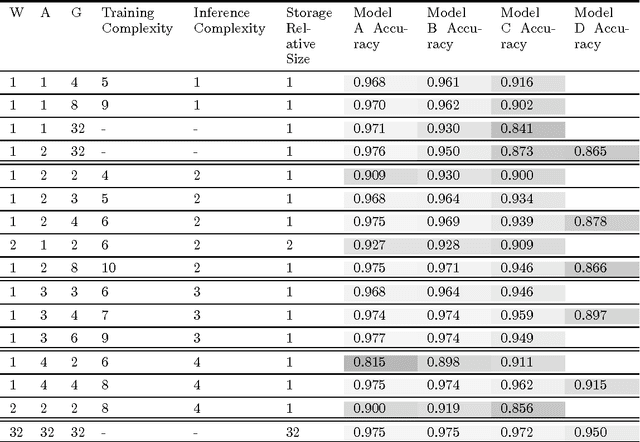
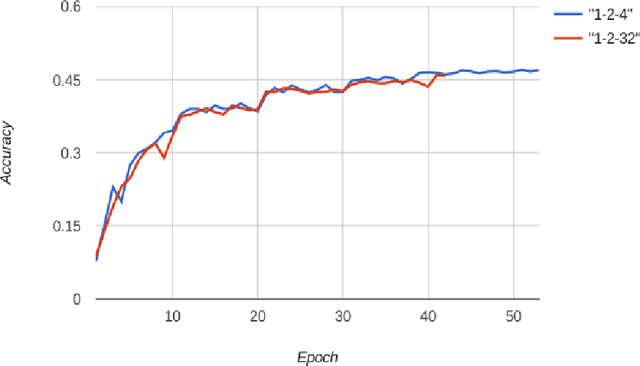
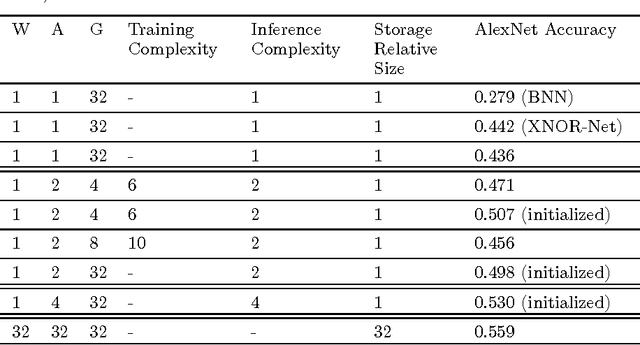
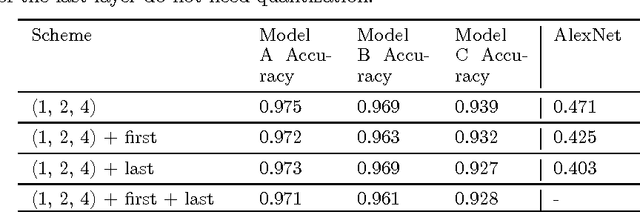
We propose DoReFa-Net, a method to train convolutional neural networks that have low bitwidth weights and activations using low bitwidth parameter gradients. In particular, during backward pass, parameter gradients are stochastically quantized to low bitwidth numbers before being propagated to convolutional layers. As convolutions during forward/backward passes can now operate on low bitwidth weights and activations/gradients respectively, DoReFa-Net can use bit convolution kernels to accelerate both training and inference. Moreover, as bit convolutions can be efficiently implemented on CPU, FPGA, ASIC and GPU, DoReFa-Net opens the way to accelerate training of low bitwidth neural network on these hardware. Our experiments on SVHN and ImageNet datasets prove that DoReFa-Net can achieve comparable prediction accuracy as 32-bit counterparts. For example, a DoReFa-Net derived from AlexNet that has 1-bit weights, 2-bit activations, can be trained from scratch using 6-bit gradients to get 46.1\% top-1 accuracy on ImageNet validation set. The DoReFa-Net AlexNet model is released publicly.